initial commit
35
.gitignore
vendored
Normal file
|
|
@ -0,0 +1,35 @@
|
||||||
|
# OS
|
||||||
|
.DS_Store
|
||||||
|
Thumbs.db
|
||||||
|
|
||||||
|
# IDEs
|
||||||
|
.buildpath
|
||||||
|
.project
|
||||||
|
.settings/
|
||||||
|
.build/
|
||||||
|
.idea/
|
||||||
|
public/
|
||||||
|
nbproject/
|
||||||
|
*.swp
|
||||||
|
|
||||||
|
# Vagrant
|
||||||
|
.vagrant/
|
||||||
|
|
||||||
|
# FE Setup
|
||||||
|
.bin/node_modules/
|
||||||
|
/node_modules/
|
||||||
|
src/node_modules/
|
||||||
|
exampleSite/node_modules/
|
||||||
|
src/npm-debug.log.*
|
||||||
|
npm-debug.log
|
||||||
|
/npm-debug.log*
|
||||||
|
/dist/
|
||||||
|
/src/client.config.json
|
||||||
|
/styleguide/
|
||||||
|
/docs/
|
||||||
|
|
||||||
|
/junit.xml
|
||||||
|
partials/structure/stylesheet.html
|
||||||
|
|
||||||
|
# Hugo
|
||||||
|
.hugo_build.lock
|
||||||
12
.gitmodules
vendored
Normal file
|
|
@ -0,0 +1,12 @@
|
||||||
|
[submodule "themes/mediumish"]
|
||||||
|
path = themes/mediumish
|
||||||
|
url = https://github.com/lgaida/mediumish-gohugo-theme
|
||||||
|
[submodule "themes/ananke"]
|
||||||
|
path = themes/ananke
|
||||||
|
url = https://github.com/theNewDynamic/gohugo-theme-ananke.git
|
||||||
|
[submodule "themes/hugo-coder"]
|
||||||
|
path = themes/hugo-coder
|
||||||
|
url = https://github.com/luizdepra/hugo-coder.git
|
||||||
|
[submodule "themes/hugo-tranquilpeak-theme"]
|
||||||
|
path = themes/hugo-tranquilpeak-theme
|
||||||
|
url = https://github.com/kakawait/hugo-tranquilpeak-theme.git
|
||||||
5
archetypes/default.md
Normal file
|
|
@ -0,0 +1,5 @@
|
||||||
|
+++
|
||||||
|
title = '{{ replace .File.ContentBaseName "-" " " | title }}'
|
||||||
|
date = {{ .Date }}
|
||||||
|
draft = true
|
||||||
|
+++
|
||||||
25
config.toml
Normal file
|
|
@ -0,0 +1,25 @@
|
||||||
|
baseURL = 'https://cowley.tech/'
|
||||||
|
languageCode = 'en-gb'
|
||||||
|
title = "Chris' Tech Blog"
|
||||||
|
theme = 'ananke'
|
||||||
|
|
||||||
|
|
||||||
|
enableRobotsTXT = true
|
||||||
|
[params]
|
||||||
|
show_reading_time = true
|
||||||
|
|
||||||
|
[services.disqus]
|
||||||
|
shortname = 'cowley-tech'
|
||||||
|
|
||||||
|
[[params.ananke_socials]]
|
||||||
|
name = "mastodon"
|
||||||
|
url = "https://mastodon.social/@chriscowley"
|
||||||
|
[[params.ananke_socials]]
|
||||||
|
name = "github"
|
||||||
|
url = "https://github.com/chriscowley"
|
||||||
|
[[params.ananke_socials]]
|
||||||
|
name = "gitlab"
|
||||||
|
url = "https://gitlab.com/chriscowleysound"
|
||||||
|
[[params.ananke_socials]]
|
||||||
|
name = "twitter"
|
||||||
|
url = "https://twitter.com/ccunix9"
|
||||||
9
content/_index.md
Normal file
|
|
@ -0,0 +1,9 @@
|
||||||
|
---
|
||||||
|
title: "tech and stuff"
|
||||||
|
description: "Wanderings through tech, cycling, DIY and other things that interest me"
|
||||||
|
|
||||||
|
cascade:
|
||||||
|
featured_image: https://assets.cowley.tech/file/cowley-tech-assets/88771809-5cfa-4383-b543-ea06a7a32f4f.png
|
||||||
|
---
|
||||||
|
|
||||||
|
|
||||||
25
content/blog/a-learning-experience/index.md
Normal file
|
|
@ -0,0 +1,25 @@
|
||||||
|
---
|
||||||
|
date: 2012-04-16
|
||||||
|
title: A Learning Experience
|
||||||
|
category: Opinions
|
||||||
|
---
|
||||||
|
|
||||||
|
How many times have you installed/updated a bit of software and read the
|
||||||
|
line "Please take a back up" or something to that effect? 99 times out
|
||||||
|
of a hundred, you will just continue and ignore it.
|
||||||
|
|
||||||
|
Today I had a reminder of why it is import to do so. I did a routine
|
||||||
|
plug-in upgrade on our Jira installation (Customware Salesforce
|
||||||
|
connector for those who want to know). I have done this several times, I
|
||||||
|
had tested it in our Dev installation I was 100% confident it would work
|
||||||
|
as expected. However, I actually decided to take a backup anyway.
|
||||||
|
|
||||||
|
I ran the upgrade in the production environment and re-indexed. Nothing
|
||||||
|
out of the ordinary. 10% of the way into the index it fell over. Jira's
|
||||||
|
database was gone! Fortunately I was able to restore from my backup and
|
||||||
|
at worst a comment or two was lost, but that still caused significant
|
||||||
|
downtime.
|
||||||
|
|
||||||
|
I had done everything I could to make sure the upgrade would go
|
||||||
|
smoothly, but it still did not. That is why software vendors always tell
|
||||||
|
you to take a backup before even the smallest change -- DO IT!
|
||||||
|
|
@ -0,0 +1,125 @@
|
||||||
|
---
|
||||||
|
date: 2012-03-20
|
||||||
|
title: Add SAN functions to Highly Available NFS/NAS
|
||||||
|
category: linux
|
||||||
|
---
|
||||||
|
|
||||||
|
This based on my last post where I documented building a Highly
|
||||||
|
Available NFS/NAS server.
|
||||||
|
|
||||||
|
There is not a huge amount that needs to be done in order to add iSCSI
|
||||||
|
functionality as well.
|
||||||
|
|
||||||
|
Add a file called */etc/drbd/iscsi.res* containing:
|
||||||
|
|
||||||
|
resource iscsi {
|
||||||
|
on nfs1 {
|
||||||
|
device /dev/drbd1;
|
||||||
|
disk /dev/vdc;
|
||||||
|
meta-disk internal;
|
||||||
|
address 10.0.0.1:7789;
|
||||||
|
}
|
||||||
|
on nfs2 {
|
||||||
|
device /dev/drbd1;
|
||||||
|
disk /dev/vdc;
|
||||||
|
meta-disk internal;
|
||||||
|
address 10.0.0.2:7789;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
This differs from the previous resource in 2 ways. Obviously it using a
|
||||||
|
different physical disk. Also the port number of the address is
|
||||||
|
incremented; each resource has to have its own port to communicate on.
|
||||||
|
|
||||||
|
# Configure Heartbeat
|
||||||
|
|
||||||
|
Add a new resource to */etc/ha.d/haresources*:
|
||||||
|
|
||||||
|
iscsi1.snellwilcox.local IPaddr::10.0.0.101/24/eth0 drbddisk::iscsi tgtd
|
||||||
|
|
||||||
|
Same primary host, new IP address, new drbd resource and of course the
|
||||||
|
service to be controlled (tgtd in this case).
|
||||||
|
|
||||||
|
I also made a couple of changes to */etc/ha.d/ha.cf*:
|
||||||
|
|
||||||
|
keepalive 500ms
|
||||||
|
deadtime 5
|
||||||
|
warntime 10
|
||||||
|
initdead 120
|
||||||
|
|
||||||
|
This changes the regularity of the heartbeat packets from every 2
|
||||||
|
seconds to 2 every second. We also say that a node is dead after only 5
|
||||||
|
seconds rather than after 30.
|
||||||
|
|
||||||
|
# Configure an iSCSI Target
|
||||||
|
|
||||||
|
Tgtd has a config file that you can use in */etc/tgt/targets.conf*. It
|
||||||
|
is an XML file, so add entry like:
|
||||||
|
|
||||||
|
<target iqn.2011-07.world.server:target0>
|
||||||
|
# provided devicce as a iSCSI target
|
||||||
|
backing-store /dev/vg_matthew/lv_iscsi1
|
||||||
|
# iSCSI Initiator's IP address you allow to connect
|
||||||
|
initiator-address 192.168.1.20
|
||||||
|
# authentication info ( set anyone you like for "username", "password" )
|
||||||
|
</target>
|
||||||
|
|
||||||
|
The target name is by convention
|
||||||
|
*iqn.year-month.reverse-domainname:hostname.targetname*. Each backing
|
||||||
|
store will be a seperate LUN. A discussion of this is out of the scope
|
||||||
|
of this article.
|
||||||
|
|
||||||
|
By default, this config file is disabled. Enable it by un-commenting the
|
||||||
|
line `#TGTD_CONFIG=/etc/tgt/targets.conf` in */etc/sysconfig/tgtd*. You
|
||||||
|
can now enable the target with service tgtd reload.
|
||||||
|
|
||||||
|
Now when you run `tgtadm –mode target –op show` you should get something
|
||||||
|
like:
|
||||||
|
|
||||||
|
Target 1: iqn.2012-03.com.example:iscsi.target1
|
||||||
|
System information:
|
||||||
|
Driver: iscsi
|
||||||
|
State: ready
|
||||||
|
I_T nexus information:
|
||||||
|
LUN information:
|
||||||
|
LUN: 0
|
||||||
|
Type: controller
|
||||||
|
SCSI ID: IET 00010000
|
||||||
|
SCSI SN: beaf10
|
||||||
|
Size: 0 MB, Block size: 1
|
||||||
|
Online: Yes
|
||||||
|
Removable media: No
|
||||||
|
Readonly: No
|
||||||
|
Backing store type: null
|
||||||
|
Backing store path: None
|
||||||
|
Backing store flags:
|
||||||
|
LUN: 1
|
||||||
|
Type: disk
|
||||||
|
SCSI ID: IET 00010001
|
||||||
|
SCSI SN: beaf11
|
||||||
|
Size: 8590 MB, Block size: 512
|
||||||
|
Online: Yes
|
||||||
|
Removable media: No
|
||||||
|
Readonly: No
|
||||||
|
Backing store type: rdwr
|
||||||
|
Backing store path: /dev/drbd/by-res/iscsi
|
||||||
|
Backing store flags:
|
||||||
|
Account information:
|
||||||
|
ACL information:
|
||||||
|
ALL
|
||||||
|
|
||||||
|
# Connect An Initiator
|
||||||
|
|
||||||
|
Install the iscsi utils:
|
||||||
|
|
||||||
|
yum install iscsi-initiator-utils
|
||||||
|
chkconfig iscsi on
|
||||||
|
chkconfig iscsid on
|
||||||
|
|
||||||
|
Discover the targets on the host and login to the target.
|
||||||
|
|
||||||
|
iscsiadm -m discovery -t sendtargets -p 10.0.0.101
|
||||||
|
iscsiadm -m node --login
|
||||||
|
|
||||||
|
If you run `cat /proc/partitions` you will see an new partition has
|
||||||
|
appeared. You can do whatever you want with it.
|
||||||
100
content/blog/all-backup-solutions-suck/index.md
Normal file
|
|
@ -0,0 +1,100 @@
|
||||||
|
---
|
||||||
|
date: 2015-08-27
|
||||||
|
title: All Backup Solutions Suck
|
||||||
|
category: opinions
|
||||||
|
---
|
||||||
|
|
||||||
|
Recently I have been working a lot on a backup solution at work, which
|
||||||
|
has been a painful experience to say the least. Why? Simply because
|
||||||
|
there is no solution that meets my ideal requirements. These are pretty
|
||||||
|
precise:
|
||||||
|
|
||||||
|
- Open Source
|
||||||
|
- Openstack Swift as a backend
|
||||||
|
- File level restores
|
||||||
|
- Scalable
|
||||||
|
- Lightweight
|
||||||
|
- An idiot must be able to restore a file
|
||||||
|
- Not a source of truth about my infrastructure
|
||||||
|
- Automated restore testing
|
||||||
|
|
||||||
|
A nice bonus would be volume level backups of Openstack Cinder.
|
||||||
|
|
||||||
|
From what I can tell, nothing currently out there meets these
|
||||||
|
requirements. If I take away the Open Source requirement it does not get
|
||||||
|
much better. [Rubrik](http://www.rubrik.com) looks interesting, if it
|
||||||
|
weren't tied into VMware, as are a few other solutions.
|
||||||
|
|
||||||
|
Nothing meets my needs :-( Naturally this has got me thinking about how
|
||||||
|
something like this could be achieved, so here goes.
|
||||||
|
|
||||||
|
I am actually taking my inspiration from the monitoring world, where
|
||||||
|
there has been similar problems. In the past, one just went straight for
|
||||||
|
Nagios to do alerting and Munin/Cacti for storing metrics. For various
|
||||||
|
reasons these just sucked, but the big one for me was this:
|
||||||
|
|
||||||
|
> I had to tell it what it had to monitor!
|
||||||
|
|
||||||
|
Tomorrow, I may be called upon to deploy a Hadoop cluster with 100
|
||||||
|
slaves. All of these would have to be individually added to Nagios. This
|
||||||
|
invariable got forgotten and before long nothing was monitored and
|
||||||
|
Nagios was forgotten about. Things broke, nobody knew about it. Everyone
|
||||||
|
said "IT SUCKS".
|
||||||
|
|
||||||
|
However, recently I\'ve been playing around with
|
||||||
|
[Sensu](http://www.sensuapp.org). This works the other way round. The
|
||||||
|
node announces itself to the server, which has a set of rules that that
|
||||||
|
the node uses to monitor itself. This, allied with all the comms being
|
||||||
|
over a Message Queue, makes it astoundingly scalable.
|
||||||
|
|
||||||
|
This is the sort of principle that backup should follow.
|
||||||
|
|
||||||
|
You have a central server, which is essentially just an API that a node
|
||||||
|
can query to discover what to do. This is based on rules such as cloud
|
||||||
|
metadata, hostname, subnet, whatever else takes your fancy. As this
|
||||||
|
server is just an API, we can use an HTTP load balancer and a NoSQL
|
||||||
|
database to improve availability and scaling.
|
||||||
|
|
||||||
|
A new agent comes online, after being installed by my CM system. It
|
||||||
|
queries the API to find out what to do, it the takes it from there. The
|
||||||
|
only time it will interact with the central server is when its
|
||||||
|
configuration changes. It knows what to backup and where to put it, so
|
||||||
|
off it goes. It can use existing tools: `tar`, `bzip2`, `duplicity`,
|
||||||
|
`gpg` etc and push it directly into the storage desired (S3/Glacier or
|
||||||
|
Openstack Swift would be the best choices I\'d say).
|
||||||
|
|
||||||
|
Of course I mindful that not all nodes will have direct access to the
|
||||||
|
storage backend for many reasons. In this case, it could use the Load
|
||||||
|
Balancer already used for the server API to bounce off to the storage.
|
||||||
|
After all, this is just an HTTP stream we are talking about; even a
|
||||||
|
fairly lightweight HAProxy instance will be able to handle 100s of
|
||||||
|
streams.
|
||||||
|
|
||||||
|
So on paper, what this should give us is a backup solution that is:
|
||||||
|
|
||||||
|
- Scalable: as there is no need to define nodes on a central server,
|
||||||
|
there is no extra step when configuring an new node. You deploy it,
|
||||||
|
install the agent and it just works. Perhaps one could follow the
|
||||||
|
Puppet model, where it defaults to a certain hostname as the server.
|
||||||
|
If that is in your DNS, then you do not even need to configure the
|
||||||
|
agent.
|
||||||
|
- High performance: The processing is distributed accross literally
|
||||||
|
your entire infrastructure, so your backup server does not become a
|
||||||
|
bottleneck.
|
||||||
|
- Has no single point of failure: If your server is just a REST API
|
||||||
|
and a web app, then HA can be performed easily with well understood
|
||||||
|
techniques. Even if you do lose it, your backups do not stop as the
|
||||||
|
nodes are doing it all themselves.
|
||||||
|
- Restores use standard tools: If you have lost everything, there is
|
||||||
|
no need to bring up your backup infrastructure first in order access
|
||||||
|
your data. It is stored on a standard backend, created with standard
|
||||||
|
tools that are available on any node with just a simple
|
||||||
|
`apt-get`/`yum`.
|
||||||
|
|
||||||
|
All this seems obvious to me, so why has no-one done it?
|
||||||
|
|
||||||
|
Of course, a genuine backup product needs do do reporting and things
|
||||||
|
like that. This is another role the central server could take on: it has
|
||||||
|
a MongoDB cluster to store all that in. Or, that could be an \"add-on\"
|
||||||
|
that just hooks into the same MongoDB (UNIX principal: do one job, and
|
||||||
|
do it well).
|
||||||
28
content/blog/another-cycling-post/index.md
Normal file
|
|
@ -0,0 +1,28 @@
|
||||||
|
---
|
||||||
|
date: 2016-07-07
|
||||||
|
title: Spiuk Z16R
|
||||||
|
category: cycling
|
||||||
|
featured_image: /images/spiuk-z16r.jpg
|
||||||
|
---
|
||||||
|
|
||||||
|
I seem to be writing more about cycling than anything else at the moment. I even have some more posts lined up on the subject, but there are few IT related ones coming too.
|
||||||
|
|
||||||
|
Anyway, I just got these the the other day to replace my old Scotts that had served through a hard Brittany winter. I got them because I read they were incredibly comfortable.
|
||||||
|
|
||||||
|
They are pretty standard fair for their RRP of €145. Sadly there is no carbon sole, for which you have to trade up to the [Z16RC](http://spiuk.com/en/producto.asp?f=16rc) for an extra €50. What you get is a polymide/glass-fibre composite. It is stiff enough, but not earth shattering. Unless you are Mark Cavendish it is fine, but carbon would definitely be stiffer. It is [possible to get a carbon sole for around this price](http://www.wiggle.co.uk/mavic-ksyrium-elite-ii-road-shoes/), especially with offers, but that is not enough for me to be critical of Spiuk for not having it.
|
||||||
|
|
||||||
|
Spiuk says they have an "Ergonomic, edgy and youthful" design. I have no idea what that means, but I think they look pretty good. I have them in black with white highlights; they are also available in white are floro yellow. They are bit too glossy for my taste if I am honest, but that is not a deal breaker. I have not got them dirty yet, so I do not know how well they clean up, but they look like they can just be sponged clean. Spiuk say to do exactly that, with just a bt of warm soapy water. Living in Brittany means it will probably not be long before I get to test that :-).
|
||||||
|
|
||||||
|
The closure is a single "Atop" dial (with a kevlar cable) and a ratchet strap. The dial does not have the micro adjust release that you see on some shoes, you release it and it undoes completely. It is pretty simple to tighten it up slightly as you ride along, so I do not find that troubles me. The ratchet works well, and between the two it took me about 500m before I was perfectly happy. What I did like is that there are two sets of straps in the box - one set a little shorter. For people like me who have fairly fine feet that means there is no excess flapping around.
|
||||||
|
|
||||||
|
Another extra in the box is the second set of insoles - you have pair for warm weather and another for cool. I think that is a really nice touch.
|
||||||
|
|
||||||
|
The standout feature of these shoes though is their "thin heat-moudable layer". The idea is that they mould to the shape of your foot a room temperature. You put them on a do them up a little too tight and spend the next hour or so wandering around. I did exactly that, much to the amusement of my colleagues who wondered why I was walking around in my new cycling shoes. Lo and behold, during that time I honestly felt them getting more comfortable.
|
||||||
|
|
||||||
|
That evening I put the straight on and road home:
|
||||||
|
|
||||||
|
<iframe height='405' width='590' frameborder='0' allowtransparency='true' scrolling='no' src='https://www.strava.com/activities/632159141/embed/ba62472cd2fc7edb93acc870d82372f6b0913a43'></iframe>
|
||||||
|
|
||||||
|
On the first ride, they were unbelievably comfortable. Honestly, I have never worn a pair of shoes that were so comfortable. I had them on again the following morning, and if anything they were even better. The air flow was really good too, it was about 25ºC and my feet were fine.
|
||||||
|
|
||||||
|
So, TL;DR: Incredibly comfortable, with some nice features and good value. Carbon soles would be nice though for a bit more power transfer
|
||||||
182
content/blog/automated-glusterfs/index.md
Normal file
|
|
@ -0,0 +1,182 @@
|
||||||
|
---
|
||||||
|
date: 2013-06-23
|
||||||
|
title: Automated GlusterFS
|
||||||
|
category: devops
|
||||||
|
---
|
||||||
|
|
||||||
|
{% img right
|
||||||
|
[https://www.hastexo.com/system/files/imagecache/sidebar/20120221105324808-f2df3ea3e3aeab8\\\_250\\\_0.png](https://www.hastexo.com/system/files/imagecache/sidebar/20120221105324808-f2df3ea3e3aeab8\_250\_0.png)
|
||||||
|
%} As I promised on Twitter, this is how I automate a GlusterFS
|
||||||
|
deployment. I\'m making a few assumptions here:
|
||||||
|
|
||||||
|
- I am using CentOS 6, so should work on RHEL 6 and Scientific Linux 6
|
||||||
|
too. Others may work, but YMMV.
|
||||||
|
- As I use XFS, RHEL users will need the *Scalable Storage* option.
|
||||||
|
Ext4 will work, but XFS is recommended.
|
||||||
|
- That you have a way of automating your base OS installation. My
|
||||||
|
personal preference is to use
|
||||||
|
[Razor](https://github.com/puppetlabs/Razor).
|
||||||
|
- You have a system with at least a complete spare disk dedicated to a
|
||||||
|
GlusterFS brick. That is the best way to run GlusterFS anyway.
|
||||||
|
- You have 2 nodes and want to replicate the data
|
||||||
|
- You have a simple setup with only a single network, because I am
|
||||||
|
being lazy. As a proof-of concept this is fine. Modifying this for
|
||||||
|
second network is quite easy, just change the IP address in you use.
|
||||||
|
|
||||||
|
{% img
|
||||||
|
<https://docs.google.com/drawings/d/1XA7GH3a4BL1uszFXrSsZjysi59Iinh-0RmhqdDbt7QQ/pub?w=673&h=315>
|
||||||
|
\'simple gluster architecture\' %}
|
||||||
|
|
||||||
|
The diagram above shows the basic layout of what to start from in terms
|
||||||
|
of hardware. In terms of software, you just need a basic CentOS 6
|
||||||
|
install and to have Puppet working.
|
||||||
|
|
||||||
|
I use a pair of Puppet modules (both in the Forge):
|
||||||
|
[thias/glusterfs](https://forge.puppetlabs.com/thias/glusterfs) and
|
||||||
|
[puppetlabs/lvm](https://forge.puppetlabs.com/puppetlabs/lvm). The
|
||||||
|
GlusterFS module CAN do the LVM config, but that strikes me as not the
|
||||||
|
best idea. The UNIX philosophy of \"do one job well\" holds up for
|
||||||
|
Puppet modules as well. You will also need my
|
||||||
|
[yumrepos](https://github.com/chriscowley/puppet-yumrepos) module.
|
||||||
|
|
||||||
|
Clone those 3 modules into your modules directory:
|
||||||
|
|
||||||
|
cd /etc/puppet/
|
||||||
|
git clone git://github.com/chriscowley/puppet-yumrepos.git modules/yumrepos
|
||||||
|
puppet module install puppetlabs/lvm --version 0.1.2
|
||||||
|
puppet module install thias/glusterfs --version 0.0.3
|
||||||
|
|
||||||
|
I have specified the versions as that is what was the latest at the time
|
||||||
|
of writing. You should be able to take the latest as well, but comment
|
||||||
|
with any differences if any. That gives the core of what you need so you
|
||||||
|
can now move on to you `nodes.pp`.
|
||||||
|
|
||||||
|
class basenode {
|
||||||
|
class { 'yumrepos': }
|
||||||
|
class { 'yumrepos::epel': }
|
||||||
|
}
|
||||||
|
|
||||||
|
class glusternode {
|
||||||
|
class { 'basenode': }
|
||||||
|
class { 'yumrepos::gluster': }
|
||||||
|
|
||||||
|
volume_group { "vg0":
|
||||||
|
ensure => present,
|
||||||
|
physical_volumes => "/dev/sdb",
|
||||||
|
require => Physical_volume["/dev/sdb"]
|
||||||
|
}
|
||||||
|
physical_volume { "/dev/sdb":
|
||||||
|
ensure => present
|
||||||
|
}
|
||||||
|
logical_volume { "gv0":
|
||||||
|
ensure => present,
|
||||||
|
require => Volume_group['vg0'],
|
||||||
|
volume_group => "vg0",
|
||||||
|
size => "7G",
|
||||||
|
}
|
||||||
|
file { [ '/export', '/export/gv0']:
|
||||||
|
seltype => 'usr_t',
|
||||||
|
ensure => directory,
|
||||||
|
}
|
||||||
|
package { 'xfsprogs': ensure => installed
|
||||||
|
}
|
||||||
|
filesystem { "/dev/vg0/gv0":
|
||||||
|
ensure => present,
|
||||||
|
fs_type => "xfs",
|
||||||
|
options => "-i size=512",
|
||||||
|
require => [Package['xfsprogs'], Logical_volume['gv0'] ],
|
||||||
|
}
|
||||||
|
|
||||||
|
mount { '/export/gv0':
|
||||||
|
device => '/dev/vg0/gv0',
|
||||||
|
fstype => 'xfs',
|
||||||
|
options => 'defaults',
|
||||||
|
ensure => mounted,
|
||||||
|
require => [ Filesystem['/dev/vg0/gv0'], File['/export/gv0'] ],
|
||||||
|
}
|
||||||
|
class { 'glusterfs::server':
|
||||||
|
peers => $::hostname ? {
|
||||||
|
'gluster1' => '192.168.1.38', # Note these are the IPs of the other nodes
|
||||||
|
'gluster2' => '192.168.1.84',
|
||||||
|
},
|
||||||
|
}
|
||||||
|
glusterfs::volume { 'gv0':
|
||||||
|
create_options => 'replica 2 192.168.1.38:/export/gv0 192.168.1.84:/export/gv0',
|
||||||
|
require => Mount['/export/gv0'],
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
node 'gluster1' {
|
||||||
|
include glusternode
|
||||||
|
file { '/var/www': ensure => directory }
|
||||||
|
glusterfs::mount { '/var/www':
|
||||||
|
device => $::hostname ? {
|
||||||
|
'gluster1' => '192.168.1.84:/gv0',
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
node 'gluster2' {
|
||||||
|
include glusternode
|
||||||
|
file { '/var/www': ensure => directory }
|
||||||
|
glusterfs::mount { '/var/www':
|
||||||
|
device => $::hostname ? {
|
||||||
|
'gluster2' => '192.168.1.38:/gv0',
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
What does all that do? Starting from the top:
|
||||||
|
|
||||||
|
- The `basenode` class does all your basic configuration across all
|
||||||
|
your hosts. Mine actually does a lot more, but these are the
|
||||||
|
relevant parts.
|
||||||
|
- The `glusternode` class is shared between all your GlusterFS nodes.
|
||||||
|
This is where all your Server configuration is.
|
||||||
|
- Configures LVM
|
||||||
|
- Defines the Volume Group \"vg0\" with the Physical Volume
|
||||||
|
`/dev/sdb`
|
||||||
|
- Creates a Logical Volume \"gv0\" for GlusterFS use and make it
|
||||||
|
7GB
|
||||||
|
- Configures the file system
|
||||||
|
- Creates the directory `/export/gv0`
|
||||||
|
- Formats the LV created previously with XFS (installs the package
|
||||||
|
if necessary)
|
||||||
|
- Mounts the LV at `/export/gv0`
|
||||||
|
|
||||||
|
This is now all ready for the GlusterFS module to do its stuff. All this
|
||||||
|
happens in those last two sections.
|
||||||
|
|
||||||
|
- The class `glusterfs::Server` sets up the peering between the two
|
||||||
|
hosts. This will actually generate a errors, but do not worry. This
|
||||||
|
because gluster1 successfully peers with gluster2. As a result
|
||||||
|
gluster2 fails to peer with gluster1 as they are already peered.
|
||||||
|
- Now `glusterfs::volume` creates a replicated volume, having first
|
||||||
|
ensured that the LV is mounted correctly.
|
||||||
|
- All this is then included in the node declarations for `gluster1`
|
||||||
|
and `gluster2`.
|
||||||
|
|
||||||
|
All that creates the server very nicely. It will need a few passes to
|
||||||
|
get everything in place, while giving a few red herring errors. It
|
||||||
|
should would however, all the errors are there in the README for the
|
||||||
|
GlusterFS module in PuppetForge, so do not panic.
|
||||||
|
|
||||||
|
A multi-petabyte scale-out storage system is pretty useless if the data
|
||||||
|
cannot be read by anything. So lets use those nodes and mount the
|
||||||
|
volume. This could also be a separate node (but once again I am being
|
||||||
|
lazy) the process will be exactly the same.
|
||||||
|
|
||||||
|
- Create a mount point for it ( \`file {\'/var/www\': ensure =\>
|
||||||
|
directory }
|
||||||
|
- Define your `glusterfs::mount` using any of the hosts in the
|
||||||
|
cluster.
|
||||||
|
|
||||||
|
Voila, that should all pull together and give you a fully automated
|
||||||
|
GlusterFS set up. The sort of scale that GlusterFS can reach makes this
|
||||||
|
sort of automation absolutely essential in my opinion. This should be
|
||||||
|
relatively easy to convert to Chef or Ansible, whatever takes your
|
||||||
|
fancy. I have just used Puppet because of my familiarity with it.
|
||||||
|
|
||||||
|
This is only one way of doing this, and I make no claims to being the
|
||||||
|
most adept Puppet user in the world. All I hope to achieve is that
|
||||||
|
someone finds this useful. Courteous comments welcome.
|
||||||
107
content/blog/bamboo-invoice-on-centos-with-nginx/index.md
Normal file
|
|
@ -0,0 +1,107 @@
|
||||||
|
---
|
||||||
|
date: 2013-04-29
|
||||||
|
title: Bamboo Invoice on Centos with Nginx
|
||||||
|
category: linux
|
||||||
|
---
|
||||||
|
|
||||||
|
[BambooInvoice](https://www.bambooinvoice.org/) is free Open Source
|
||||||
|
invoicing software intended for small businesses and independent
|
||||||
|
contractors. It is easy to use and creates pretty good looking invoices.
|
||||||
|
|
||||||
|
It is a simple PHP application that is based on the CodeIgniter
|
||||||
|
framework. This means it is really simple to install on a typically LAMP
|
||||||
|
stack. I however use Nginx and could not find any notes on how to
|
||||||
|
configure it. It is pretty typical you can get most of the way by
|
||||||
|
reading any of the Nginx howto documents on the web. Personally, for PHP
|
||||||
|
apps, I use PHP-FPM, so you could use [this on
|
||||||
|
Howtoforge](https://www.howtoforge.com/installing-nginx-with-php5-and-php-fpm-and-mysql-support-on-centos-6.4)
|
||||||
|
to get most of the way. That will get you a working Nginx, PHP and MySQL
|
||||||
|
system.
|
||||||
|
|
||||||
|
Download the install file from \[<https://bambooinvoice.org/>\] an unzip
|
||||||
|
is in your www folder:
|
||||||
|
|
||||||
|
```
|
||||||
|
cd /var/www
|
||||||
|
wget https://bambooinvoice.org/img/bambooinvoice_089.zip
|
||||||
|
unzip bambooinvoice_089.zip
|
||||||
|
```
|
||||||
|
|
||||||
|
You next step is to create a database for it along with a user:
|
||||||
|
|
||||||
|
```
|
||||||
|
CREATE DATABASE bambooinvoice DEFAULT CHARACTER SET utf8;
|
||||||
|
GRANT ALL ON bambooinvoice.* TO 'bambooinvoice'@'localhost' IDENTIFIED BY 'bambooinvoice';
|
||||||
|
FLUSH PRIVILEGES;
|
||||||
|
exit
|
||||||
|
```
|
||||||
|
|
||||||
|
Now you can edit the config files to point at the database:
|
||||||
|
|
||||||
|
```
|
||||||
|
/var/www/bambooinvoices/bamboo\_system\_files/application/config/database.php
|
||||||
|
```
|
||||||
|
|
||||||
|
Next you need set the base\_url in
|
||||||
|
`/var/www/bambooinvoices/bamboo_system_files/application/config/config.php`.
|
||||||
|
Nothing else is essential in that file, but read the docs in the ZIP
|
||||||
|
file to see what else you want to change.
|
||||||
|
|
||||||
|
Now the all important bit (`/et/nginx/conf.d/bamboo.conf`).
|
||||||
|
|
||||||
|
```
|
||||||
|
server {
|
||||||
|
listen 80;
|
||||||
|
|
||||||
|
server_name bamboo.example;
|
||||||
|
root /var/www/bambooinvoice/;
|
||||||
|
index index.php index.html;
|
||||||
|
access_log /var/log/nginx/bamboo_access.log;
|
||||||
|
error_log /var/log/nginx/bamboo_error.log;
|
||||||
|
|
||||||
|
location = /robots.txt {
|
||||||
|
allow all;
|
||||||
|
log_not_found off;
|
||||||
|
access_log off;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
# Deny all attempts to access hidden files such as .htaccess, .htpasswd, .DS_Store (Mac).
|
||||||
|
location ~ /\. {
|
||||||
|
deny all;
|
||||||
|
access_log off;
|
||||||
|
log_not_found off;
|
||||||
|
}
|
||||||
|
location / {
|
||||||
|
try_files $uri $uri/ /index.php$request_uri /index.php;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
location ~ \.php($|/) {
|
||||||
|
try_files $uri =404;
|
||||||
|
fastcgi_pass 127.0.0.1:9000;
|
||||||
|
include /etc/nginx/fastcgi_params;
|
||||||
|
fastcgi_index index.php;
|
||||||
|
set $script $uri;
|
||||||
|
set $path_info "";
|
||||||
|
if ($uri ~ "^(.+\.php)(/.+)") {
|
||||||
|
set $script $1;
|
||||||
|
set $path_info $2;
|
||||||
|
}
|
||||||
|
fastcgi_param URI $uri;
|
||||||
|
# Next two lines are fix the 502 (Bad gateway) error
|
||||||
|
fastcgi_buffers 8 16k;
|
||||||
|
fastcgi_buffer_size 32k;
|
||||||
|
|
||||||
|
fastcgi_param PATH_INFO $path_info;
|
||||||
|
fastcgi_param SCRIPT_NAME $script;
|
||||||
|
fastcgi_param SCRIPT_FILENAME $document_root$script;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
At first glance, there is nothing out of the ordinary. This is pretty
|
||||||
|
much what Howtoforge gives you. Look more closely and I have added the 3
|
||||||
|
lines 39-41. This solves a gateway problem I had when creating a client.
|
||||||
47
content/blog/bootstrapping-a-puppet-master/index.md
Normal file
|
|
@ -0,0 +1,47 @@
|
||||||
|
---
|
||||||
|
date: 2015-03-14
|
||||||
|
title: Bootstrapping a Puppet master
|
||||||
|
category: devops
|
||||||
|
---
|
||||||
|
|
||||||
|
Installing a Puppetmaster is a bit of a chicken-egg problem. We want to
|
||||||
|
have our environment as automated and slick as possible, but we
|
||||||
|
currently have no tools installed to to so.
|
||||||
|
|
||||||
|
So what do we actually need to install and configure for our Puppet
|
||||||
|
master:
|
||||||
|
|
||||||
|
- Puppet
|
||||||
|
- Hiera
|
||||||
|
- R10k
|
||||||
|
- Git
|
||||||
|
|
||||||
|
This is the minimum, from this it can go ahead and dogfood itself in my
|
||||||
|
prefered fashion.
|
||||||
|
|
||||||
|
I do this with a bit of bash that I threw together during a meeting. I
|
||||||
|
use only bash as that is the only thing I can be guaranteed to have on a
|
||||||
|
clean install.
|
||||||
|
|
||||||
|
If you trust me then simply run:
|
||||||
|
|
||||||
|
curl https://raw.githubusercontent.com/chriscowley/puppetmaster-bootstrap/master/bootstrap.sh | sudo -E sh
|
||||||
|
|
||||||
|
If not, or of you want to control it a bit more, then clone it. If you
|
||||||
|
modify it I\'ll happily accept pull requests.
|
||||||
|
|
||||||
|
git clone https://github.com/chriscowley/puppetmaster-bootstrap.git
|
||||||
|
cd puppetmaster-bootstrap
|
||||||
|
./bootstrap.sh
|
||||||
|
|
||||||
|
There are a few environment variables you can use to control it:
|
||||||
|
|
||||||
|
- PMB\_CONFIGURE\_GIT : Whether to install/configure Git (defaults=1)
|
||||||
|
- PMB\_CONFIGURE\_R10k : Whether to install/configure R10k
|
||||||
|
(defaults=1)
|
||||||
|
- PMB\_TEST : Only tell you what it would do, but nothing actually
|
||||||
|
happens
|
||||||
|
- PMB\_INSTALL\_POSTRECEIVE : Install the post-receive git hook
|
||||||
|
(default=1)
|
||||||
|
|
||||||
|
I have tried to use sensible defaults, at least for my purposes.
|
||||||
|
|
@ -0,0 +1,70 @@
|
||||||
|
---
|
||||||
|
date: 2017-09-14
|
||||||
|
title: Clean Old Exported Resources From Puppetdb
|
||||||
|
category: devops
|
||||||
|
---
|
||||||
|
|
||||||
|
Exported Resources are great, but also suck. If you are not careful how you tag them, you can easily end up in a situation where you have duplicate resources on a node. Of course this will mean that your catalogue will fail to compile.
|
||||||
|
|
||||||
|
Normally, old exported resources are cleaned up the next time the agent runs, but can be prone to failure for various reasons:
|
||||||
|
|
||||||
|
- the node no longer exists
|
||||||
|
- the moon is no longer on the right phase
|
||||||
|
- Puppet just doesn't feel like it
|
||||||
|
|
||||||
|
|
||||||
|
This means you get a big red error such as:
|
||||||
|
|
||||||
|
```
|
||||||
|
Error: Could not retrieve catalog from remote server: Error 500 on SERVER: Server Error: A duplicate resource was found while collecting exported resources, with the type and title Mysql::Db[<dbname>] on node <node2>
|
||||||
|
Warning: Not using cache on failed catalog
|
||||||
|
Error: Could not retrieve catalog; skipping run
|
||||||
|
```
|
||||||
|
|
||||||
|
The way to get rid of them is to delete them from PuppetDB's database. This is easy enough, but may be scary for some:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo -u postgres psql puppetdb -c 'delete from catalogs where certname in (select certname from certnames where certname like "<hostname1>%");'
|
||||||
|
```
|
||||||
|
|
||||||
|
Obviously, `<hostname>` is a placeholder which you need to replace as appropriate
|
||||||
|
|
||||||
|
**IMPORTANT:** This is applies to PuppetDB 4.0 and later as far as I can make out. Previously ( `>=1.6` and `<4` I believe) the column in the `certnames` table was called `name`, so the query would have been:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo -u postgres psql puppetdb -c 'delete from catalogs where certname in (select name from certnames where certname like "<hostname1>%");'
|
||||||
|
```
|
||||||
|
|
||||||
|
If you want to know what DB schema you have, the best idea is to check the `certnames` table:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo -u postgres psql puppetdb -c '\d+ certnames;'
|
||||||
|
```
|
||||||
|
|
||||||
|
You will get an ouput like:
|
||||||
|
|
||||||
|
```
|
||||||
|
Table "public.certnames"
|
||||||
|
Column | Type | Modifiers | Storage | Stats target | Description
|
||||||
|
------------------+--------------------------+-------------------------------------------------------+----------+--------------+-------------
|
||||||
|
id | bigint | not null default nextval('certname_id_seq'::regclass) | plain | |
|
||||||
|
certname | text | not null | extended | |
|
||||||
|
latest_report_id | bigint | | plain | |
|
||||||
|
deactivated | timestamp with time zone | | plain | |
|
||||||
|
expired | timestamp with time zone | | plain | |
|
||||||
|
Indexes:
|
||||||
|
"certnames_transform_pkey" PRIMARY KEY, btree (id)
|
||||||
|
"certnames_transform_certname_key" UNIQUE CONSTRAINT, btree (certname)
|
||||||
|
Foreign-key constraints:
|
||||||
|
"certnames_reports_id_fkey" FOREIGN KEY (latest_report_id) REFERENCES reports(id) ON DELETE SET NULL
|
||||||
|
Referenced by:
|
||||||
|
TABLE "catalog_resources" CONSTRAINT "catalog_resources_certname_id_fkey" FOREIGN KEY (certname_id) REFERENCES certnames(id) ON DELETE CASCADE
|
||||||
|
TABLE "catalogs" CONSTRAINT "catalogs_certname_fkey" FOREIGN KEY (certname) REFERENCES certnames(certname) ON DELETE CASCADE
|
||||||
|
TABLE "factsets" CONSTRAINT "factsets_certname_fk" FOREIGN KEY (certname) REFERENCES certnames(certname) ON UPDATE CASCADE ON DELETE CASCADE
|
||||||
|
TABLE "reports" CONSTRAINT "reports_certname_fkey" FOREIGN KEY (certname) REFERENCES certnames(certname) ON DELETE CASCADE
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
You will have either `certname` or `name` under Column depending on your version.
|
||||||
|
|
||||||
|
Having said all that, if you are still on pre-4 PuppetDB, you really should be upgrading.
|
||||||
179
content/blog/consul-prometheus-and-puppet/index.md
Normal file
43
content/blog/dell-announces-vrtx/index.md
Normal file
|
|
@ -0,0 +1,43 @@
|
||||||
|
---
|
||||||
|
date: 2013-06-04
|
||||||
|
title: Dell Announces VRTX
|
||||||
|
category: Opinions
|
||||||
|
featured_image: /images/PowerEdge-VRTX-Front-View-with-2.5-Drives.png
|
||||||
|
---
|
||||||
|
|
||||||
|
Dell has announced the new PowerEdge VRTX (pronounced Vertex). The
|
||||||
|
name comes from a vertex being "the intersection of multiple lines",
|
||||||
|
alluding to this being a mixture of a rack server, a blade server and a
|
||||||
|
SAN.
|
||||||
|
|
||||||
|
It is aimed at branch offices, so it contains 4 servers, storage,
|
||||||
|
networking and (unusually) the ability to add PCI-e cards (up to 8,
|
||||||
|
including 3 FH/FL). These cards can be connected to which ever server
|
||||||
|
you want. These features put in competition with the HP C3000 and the
|
||||||
|
Supermicro OfficeBlade.
|
||||||
|
|
||||||
|
The other 2 are basically standard blade chassis that have been given
|
||||||
|
quiet fans and IEC power connectors. You can pick and choose storage,
|
||||||
|
PCI-E and compute blades depending on your needs. They also have the
|
||||||
|
full array of networking options: anything from 2 1Gb uplinks to full on
|
||||||
|
40GB QDR infiniband. VRTX on the other hand is a fixed configuration of
|
||||||
|
a 2U SAS array (either 2.5" or 3.5" disks) and 4 compute servers. You
|
||||||
|
can add PCI-e cards, but support is limited. Basically, it expands the
|
||||||
|
limited networking available in the blades themselves (no 10Gb at
|
||||||
|
launch, max of 8x 1Gb uplink with no redundant fabric). There is support
|
||||||
|
for a GPU, but it is AMD only with no Nvidia Tesla support.
|
||||||
|
|
||||||
|
So what we have is a system that takes the same amount of space as it
|
||||||
|
competitors and is less flexible. So why would you want it? In several
|
||||||
|
cases I have wanted something that would give me a simple solution to
|
||||||
|
run VMware (or similar) properly (i.e. shared storage and at least 2
|
||||||
|
nodes) and go in the corner of the office on a standard plug. The other
|
||||||
|
solutions can do this with a bit of thought (more so with the
|
||||||
|
Supermicro), but the VRTX will do that out-of-the-box.
|
||||||
|
|
||||||
|
If I could make 1 request of Dell, it would be to do a "VRTX lite"
|
||||||
|
that drops the PCI-e slots and (perhaps) halves the number of disks and
|
||||||
|
servers. To get a pair of computer servers and a small SAN in a 4 bay
|
||||||
|
NAS sized box would be awesome for many a SMB branch office.
|
||||||
|
|
||||||
|
<iframe width="640" height="360" src="https://www.youtube.com/embed/16IlDQnIMrk?rel=0" frameborder="0" allowfullscreen></iframe>
|
||||||
71
content/blog/devops-terminology/index.md
Normal file
|
|
@ -0,0 +1,71 @@
|
||||||
|
---
|
||||||
|
date: 2014-11-21
|
||||||
|
title: DevOps Terminology
|
||||||
|
category: devops
|
||||||
|
---
|
||||||
|
|
||||||
|
Talking to a few people there seems to be a little confusion over the
|
||||||
|
various stages in the deployment pipeline. Specifically there seems to
|
||||||
|
be a little confusion over 3 things:
|
||||||
|
|
||||||
|
- Orchestration
|
||||||
|
- Provisioning
|
||||||
|
- Configuration Management
|
||||||
|
|
||||||
|
These seem to have got rather mixed up of late. I will put the blame
|
||||||
|
squarely at the doors of marketing departments because, well, why
|
||||||
|
not...
|
||||||
|
|
||||||
|
I should probably add that these are my opinions. It is all a little
|
||||||
|
grey, but this makes sense to me.
|
||||||
|
|
||||||
|
To me Configuration Management should be every single environment, no
|
||||||
|
matter how simple. By contrast the other 2 may not apply everywhere. Its
|
||||||
|
basic role is to take your basic system and prepare it for production.
|
||||||
|
|
||||||
|
It is also an ongoing process, because it does not only apply your
|
||||||
|
configuration. Once everything is going it continues to enforce that
|
||||||
|
configuration.
|
||||||
|
|
||||||
|
A benefit that comes from this is that it should also be effectively
|
||||||
|
self-documenting.
|
||||||
|
|
||||||
|
Personally I always head towards [Puppet](https://www.puppetlabs.com)
|
||||||
|
here. There are plenty of good options though, such as Ansible and
|
||||||
|
Saltstack.
|
||||||
|
|
||||||
|
Working back, provisioning should deploy the most basic system that can
|
||||||
|
hook up to your configuration management system.
|
||||||
|
|
||||||
|
> Personally I do not like templates, à la VMware. Rather I prefer to
|
||||||
|
> just to do fresh OS install. That way I do not need to perform a
|
||||||
|
> second pass to install updates. Having said that, when working with
|
||||||
|
> AWS or Openstack they are a very effective way to work
|
||||||
|
|
||||||
|
The key thing here is that it should link in with the next step
|
||||||
|
(configuration management). It is essentially that it hands the new
|
||||||
|
system over to CM with no input from the SysAdmin. As a Puppet user this
|
||||||
|
means that you should come out at the end with the Puppet agent
|
||||||
|
installed and configured.
|
||||||
|
|
||||||
|
I tend towards [Razor](https://github.com/puppetlabs/razor-server) which
|
||||||
|
is truly excellent. There are other good options such as
|
||||||
|
[Cobbler](https://www.cobblerd.org/), but basically anything that can
|
||||||
|
perform an OS install, add an agent and inject a config file is great.
|
||||||
|
In many environments, a simple PXE server with a bunch of kickstart
|
||||||
|
files may well be more than sufficient.
|
||||||
|
|
||||||
|
Orchestration is the first stage that provides an automated way of
|
||||||
|
launching your provisioning system. It also prepares the Configuration
|
||||||
|
Management. In my ver Puppet-centric world this means it should
|
||||||
|
configure Hiera data for what the new system(s) are to do.
|
||||||
|
|
||||||
|
It terms of tooling, there is always a certain amount of
|
||||||
|
cross-pollination. Puppet for example can be used as an excellent way of
|
||||||
|
[controlling your AWS
|
||||||
|
infrastucture](https://puppetlabs.com/blog/provision-aws-infrastructure-using-puppet)
|
||||||
|
which puts it firmly in the provisioning camp. I will not tell anyone
|
||||||
|
not to use it that way, but I personally see it as a little
|
||||||
|
*feature-creep*-like, so I will not be going there. I will be sticking
|
||||||
|
to the tried and tested UNIX philosophy of "do one thing and do it
|
||||||
|
well".
|
||||||
97
content/blog/emc-vipr-thoughts/index.md
Normal file
|
|
@ -0,0 +1,97 @@
|
||||||
|
---
|
||||||
|
date: 2013-05-13
|
||||||
|
title: EMC ViPR thoughts
|
||||||
|
category: Opinions
|
||||||
|
---
|
||||||
|
|
||||||
|
I have been a little slow on the uptake on this one. I would like to say
|
||||||
|
it is because I was carefully digesting the information, but that is not
|
||||||
|
true; the reality is that I have just had 2 5 day weekends in 2 weeks
|
||||||
|
:-).
|
||||||
|
|
||||||
|
The big announcement at this years EMC World is ViPR. Plenty of people
|
||||||
|
with far bigger reputations than me in the industry have already made
|
||||||
|
their comments:
|
||||||
|
|
||||||
|
- [Chad
|
||||||
|
Sakac](https://virtualgeek.typepad.com/virtual_geek/2013/05/storage-virtualization-platform-re-imagined.html)
|
||||||
|
has really good and deep, but long.
|
||||||
|
- [Chuck
|
||||||
|
Hollis](https://chucksblog.emc.com/chucks_blog/2013/05/introducing-emc-vipr-a-breathtaking-approach-to-software-defined-storage.html)
|
||||||
|
is nowhere near as technical but (as is normal for Chuck) sells it
|
||||||
|
beautifully
|
||||||
|
- [Scott
|
||||||
|
Lowe](https://blog.scottlowe.org/2013/05/06/very-early-thoughts-about-emc-vipr/)
|
||||||
|
has an excellent overview
|
||||||
|
- [Kate
|
||||||
|
Davies](https://h30507.www3.hp.com/t5/Around-the-Storage-Block-Blog/ViPR-or-Vapor-The-Software-Defined-Storage-saga-continues/ba-p/138013?utm_source=feedly#.UZCd_covj3w)
|
||||||
|
gives HP's take on it, which I sort of agree with, but not
|
||||||
|
completely. As she says, the StoreAll VSA is not really in the same
|
||||||
|
market, but I think it is the closest thing HP have so comparisons
|
||||||
|
will always be drawn.
|
||||||
|
|
||||||
|
ViPR is EMC's response to two major storage problems: 1. Storage is
|
||||||
|
missing some sort of abstraction layer, particularly for management (the
|
||||||
|
Control Plane). 1. There is more to storage than NFS and iSCSI. As well
|
||||||
|
as NAS/SAN we now have multiple forms of object stores, plus important
|
||||||
|
non-POSIX file systems such as HDFS.
|
||||||
|
|
||||||
|
Another problem I would add is that of *Openness*. For now there is not
|
||||||
|
really any protocols for managing multiple arrays from different
|
||||||
|
manufacturers, even at a basic level. They have been attempts in the
|
||||||
|
past (SMI-S), but they have never taken off. ViPR attacks that problem
|
||||||
|
as well, sort of.
|
||||||
|
|
||||||
|
In some respects I am quite excited about ViPR. The ability to
|
||||||
|
completely abstract the management of my storage is potentially very
|
||||||
|
powerful. For now it is not really possible to integrate storage with
|
||||||
|
Configuration Management tools. ViPR gives all supported arrays a REST
|
||||||
|
API, thus it would be very simple to create bindings for the scripting
|
||||||
|
language of your choice. Low and behold, a Puppet module to manage all
|
||||||
|
my storage arrays becomes possible. This very neatly solves problem \#1.
|
||||||
|
|
||||||
|
This is where my excitement ends however. The problem is that issue of
|
||||||
|
*Openness* I mentioned above. EMC has gone to great lengths to describe
|
||||||
|
ViPR as open, but the fact remains that it is not. EMC have published
|
||||||
|
the specifications of the REST API, they have also created a plugin
|
||||||
|
interface for third-parties to add their own arrays; this is where it
|
||||||
|
ends however. All development of ViPR is at the mercy of EMC, so why
|
||||||
|
would other vendors support it?
|
||||||
|
|
||||||
|
A lot of the management tools in ViPR are already in Openstack Cinder,
|
||||||
|
which supports a much wider range of backends than ViPR at present. In
|
||||||
|
that vendors have a completely open source management layer to develop
|
||||||
|
against. Why would they sell their souls to a competitor? Simple, they
|
||||||
|
will not. EMC exclusive shops will find ViPR to be an excellent way
|
||||||
|
integrating their storage with a DevOps style workflow. Unfortunately my
|
||||||
|
experience is that the sort of organizations that buy EMC (especially
|
||||||
|
the big ones like VMAX) are not really ready for DevOps yet.
|
||||||
|
|
||||||
|
Another feature that EMC has been touted is multi-protocol access to
|
||||||
|
your data. Block volumes can be accessed via both iSCSI and FC protocols
|
||||||
|
- nothing really clever there I\'m afraid. Dot Hill has been doing that
|
||||||
|
for several years with the [AssuredSAN
|
||||||
|
39x0](https://www.dothill.com/wp-content/uploads/2011/08/AssuredSAN-n-3920-3930-C-10.15.11.pdf)
|
||||||
|
models (and by extension the the HP P2000 as well). That is also easy
|
||||||
|
enough to do on commodity hardware using [LIO
|
||||||
|
target](https://linux-iscsi.org/wiki/Main_Page) plus a whole lot more.
|
||||||
|
On the file side, it gives you not only access to your data via both
|
||||||
|
CIFS and NFS, but it does add object access to that. They touted this as
|
||||||
|
being very clever, but once again you can already do this using well
|
||||||
|
respected, production proven open source. Glusterfs has an object
|
||||||
|
translator, so that covers that super clever feature. All the data
|
||||||
|
abstraction features it has are already there in in the open source
|
||||||
|
world. If you want object and NAS access to the same peta-byte storage
|
||||||
|
system, you have it in both Glusterfs and Ceph, both of which can easily
|
||||||
|
be managed by CM tools such as Puppet.
|
||||||
|
|
||||||
|
{% pullquote %} EMC has really pushed ViPR in the last couple of weeks,
|
||||||
|
but it fails to impress me. This is a shame, because in general I like
|
||||||
|
EMC\'s products. I don\'t like their marketing, but in their gear does
|
||||||
|
just work. ViPR will probably do well with large EMC/NetApp shops, but
|
||||||
|
it is by no means the ground-breaking product that EMC would have people
|
||||||
|
believe (to be honest, I\'m not sure anything ever is). It can never be
|
||||||
|
the universal gateway to manage our storage, it is too tied in to EMC.
|
||||||
|
{\"To be a universal standard it would need to be an open (source)
|
||||||
|
standard\"}, which is not really part of EMC\'s culture (with the
|
||||||
|
exception of the awesome Razor). {% endpullquote %}
|
||||||
256
content/blog/experience-buying-a-chinese-bike-frame/index.md
Normal file
|
|
@ -0,0 +1,256 @@
|
||||||
|
---
|
||||||
|
date: 2019-06-24
|
||||||
|
title: Experience Buying a Chinese Bike Frame
|
||||||
|
category: cycling
|
||||||
|
tags:
|
||||||
|
- cycling
|
||||||
|
- diy
|
||||||
|
featured_image: https://assets.cowley.tech/file/cowley-tech-assets/IMG_20190517_121211026_HDR.jpg
|
||||||
|
---
|
||||||
|
|
||||||
|
I've recently decided to change my bike frame as I developed a tendonitis due to my
|
||||||
|
beloved Felt F95 actually being too big. As we are also looking to buy a house,
|
||||||
|
my budget was quite limited. This put a nice shiney Cannondale SystemSix well out of
|
||||||
|
my reach, so I decided to give a Chinese frame a try.
|
||||||
|
|
||||||
|
This is not as shocking as it sounds because of the realities of the bike market.
|
||||||
|
|
||||||
|
## How does the market actually work?
|
||||||
|
Most frames are built in the far east, with the majority being built in China. Even the
|
||||||
|
expensive Italian Pinarello that Chris Froome and co. ride is built in China. The
|
||||||
|
problem is that carbon is difficult and the expertise to work with it has ended up
|
||||||
|
in just a few places. If you want 10 things made, you go to the UK (thanks to Formula 1),
|
||||||
|
but if you want more then China is really your only option. Carbon manufacture is labour
|
||||||
|
intensive and China basically has the mixture of expertise and low wages to make
|
||||||
|
it viable. Additionally, the mold is **really** expensive.
|
||||||
|
|
||||||
|
So how does this map on to the bike market? You have a few tiers, the exact details of which
|
||||||
|
are not exactly public knowledge:
|
||||||
|
|
||||||
|
- The biggest companies (Giant, Merida) make everything themselves. To my knowledge, these
|
||||||
|
are the only two.
|
||||||
|
- Next down you have companies that do all their own R&D and own the mold. I think the likes
|
||||||
|
of Trek and Specialized occupy this space. The fact that they own the mold means that the
|
||||||
|
factory will only make a Specialized Tarmac shaped bike for Specialized.
|
||||||
|
- Another step down are those who do all the R&D, but do not have the capital to buy the
|
||||||
|
mold. The factory builds the bikes for the company, but (as they own the mold) they can also build
|
||||||
|
them for themselves. My feeling is that Pinarello occupy this space. This is why *Chinarellos* are
|
||||||
|
a thing.
|
||||||
|
- Finally you have what are called *Open Mold* frames. These are frames that a factory offers to
|
||||||
|
to anyone. If you want to start a bike brand you basically choose a frameset off the menu. This
|
||||||
|
is how companies like Ribble work. Some of these factories will also allow a consumer to buy a
|
||||||
|
single frame.
|
||||||
|
|
||||||
|
Some will say that the mold is only part of the story. That the important part
|
||||||
|
is the layup and that is what you pay for. This is totally true, but I would also
|
||||||
|
say that the factory will have learnt a particular way of laying the sheets for
|
||||||
|
the major "manufacturer" and they will probably not modify it for their own
|
||||||
|
frames. Also, the Chinese have a culture where the ability to perfectly reproduce
|
||||||
|
something is highly respected. This will apply to the carbon layup as well as the
|
||||||
|
form.
|
||||||
|
|
||||||
|
# Buying/waiting/unboxing
|
||||||
|
|
||||||
|
It is those open mold frames that allow us consumers to get some super bargains.
|
||||||
|
For no really logical reason, I felt that Ebay was too risky, so I jumped on
|
||||||
|
Aliexpress and found a [Winice R03](https://www.aliexpress.com/item/32804420408.html) which
|
||||||
|
appealed to me aesthetically and financially.
|
||||||
|
|
||||||
|
So how has it gone? To be honest, it was mixed. I had a lot of messaging back and forth with
|
||||||
|
the seller and they were very reactive (even the english was pretty good). Aliexpress
|
||||||
|
does not allow PayPal, but the seller did, so I sent them a payment and within a
|
||||||
|
couple of hours I had a photo of my frameset ready to ship. The following morning
|
||||||
|
I had a shipping number and was getting gradually more excited. It arrived about
|
||||||
|
few days later having sat in Customs a Charle De Gaul airport for 2 of those days.
|
||||||
|
|
||||||
|
It was packed pretty well, with everything nicely wrapped and well protected.
|
||||||
|
|
||||||
|
<img class="article-image" src="https://assets.cowley.tech/file/cowley-tech-assets/IMG_20190507_194628800.jpg" />
|
||||||
|
|
||||||
|
I spent a while carefully unwrapping everything and spent a bit too much time admiring it.
|
||||||
|
I had a nice pseudo-aero frame, matching seat post and a fork with a tapered carbon steerer.
|
||||||
|
A nice touch is that the seat post has a high friction material down the front to stop it
|
||||||
|
slipping. Apparently that is a common problem not just with Chinese frame, but a lot of
|
||||||
|
aero frames that have non-standard clamps, so I was pretty happy to see that. In the box I
|
||||||
|
found a little box with the headset bearings and the seat post clamp.
|
||||||
|
|
||||||
|
I had a good look over everything and it all seems well put together. Looking
|
||||||
|
inside with a torch and best as I could, it appears to be clean on the inside
|
||||||
|
with no bits of bladder or bad finishing. Obviously, my next step was to put them
|
||||||
|
on the old kitchen scales:
|
||||||
|
|
||||||
|
<img class="article-image" src="https://assets.cowley.tech/file/cowley-tech-assets/IMG_20190507_195902700.jpg" />
|
||||||
|
|
||||||
|
<img class="article-image" src="https://assets.cowley.tech/file/cowley-tech-assets/IMG_20190507_195311178.jpg" />
|
||||||
|
|
||||||
|
<img class="article-image" src="https://assets.cowley.tech/file/cowley-tech-assets/IMG_20190507_195038057.jpg" />
|
||||||
|
|
||||||
|
- Frame: 1100g
|
||||||
|
- Fork: 380g
|
||||||
|
- Seat post: 140g
|
||||||
|
|
||||||
|
So 1620g in total, not bad for the price.
|
||||||
|
|
||||||
|
# Building
|
||||||
|
|
||||||
|
I will not put any photos because, to be honest, my garage is a mess. It is really
|
||||||
|
just a bike build though, of which there are many videos on [YouTube](https://www.youtube.com/watch?v=hhRYMx2gjs0)
|
||||||
|
that are better than mine would be. My plan was to move all the components of my
|
||||||
|
Felt over to the Winice, most of which went according to plan.
|
||||||
|
|
||||||
|
The first thing I did was put the fork in along with the headset bearings. These
|
||||||
|
pretty much dropped into place, although the bottom bearing needed a little
|
||||||
|
pressure from the fork (but not a lot). I put the stem on gently just to hold everything in place
|
||||||
|
as my toothless hacksaw blade had not arrived yet, so I could not cut the steerer down.
|
||||||
|
This was definitely necessary:
|
||||||
|
|
||||||
|
<img class="article-image" src="https://assets.cowley.tech/file/cowley-tech-assets/IMG_20190507_210039005.jpg" />
|
||||||
|
|
||||||
|
The seat post obviously went straight in and I slightly tightened the two bolts
|
||||||
|
to hold it in place. This was not really necessary though, as it is pretty solid
|
||||||
|
anyway. Also, it was very long so I noted that I would need to cut it down slightly
|
||||||
|
when I came to cut the steerer.
|
||||||
|
|
||||||
|
One difference was the bottom bracket as the Felt has threaded BSA, but now
|
||||||
|
now I have PF86. This works out pretty well as I could easily re-use my Tiagra
|
||||||
|
crankset and I needed new bearings anyway. I thought about getting a flashy
|
||||||
|
ceramic one from Aliexpress, but that was just a step to far for me. I ended up
|
||||||
|
getting the [basic Shimano model](https://www.chainreactioncycles.com/shimano-bb71-road-press-fit-bottom-bracket/rp-prod61803).
|
||||||
|
|
||||||
|
Many people will tell you that you have to use a special tool to press BB bearings
|
||||||
|
in and, if you don't, the world will end. This was a cheap build though, so I used my
|
||||||
|
home-made press - a long bolt, with a selection of washers. This worked perfectly and
|
||||||
|
(spoiler alert) there is absolutely no creaking.
|
||||||
|
|
||||||
|
Next up was to run the cables, which was a new experience for me having never
|
||||||
|
had internally routed cables in my life. To this end I called
|
||||||
|
in my "engineer in training" (aka, my 12 year old son) and we set to work. I started by
|
||||||
|
simply running a gear cable as normal, but I had already put the crankset in place,
|
||||||
|
so there was no way the cable was going to come out at the bottom bracket shell. So we
|
||||||
|
scrapped that idea and threaded an old cable in reverse. As the cable ports near the head
|
||||||
|
tube were larger, we were able to get an old spoke in and hook the cable out. I could now use
|
||||||
|
that to pull the actual cable for the front deraillleur. We did the same trick for the rear
|
||||||
|
derailleur, but fell foul at the rear axle. Again, removing the exit port gave a few more
|
||||||
|
milimetres to play with. After a lot of complaining and frustration, all of a sudden the
|
||||||
|
cable popped out and we celebrated with a cup of tea for me and an orange juice for my
|
||||||
|
slave/son.
|
||||||
|
|
||||||
|
Oddly enough the rear brake cable just worked as that has a guide. Why there is one for
|
||||||
|
the brake, but not the gears I cannot explain. I would add that, according to the photos
|
||||||
|
on AliExpress, this frame comes with cable-guides all-round:
|
||||||
|
|
||||||
|
<img src="https://assets.cowley.tech/file/cowley-tech-assets/big-discount-2018-New-road-bike-frameset-black-matt-road-bicycle-frame-toray-full-carbon-fiber.jpg" class="article-image" />
|
||||||
|
|
||||||
|
Despite all the hassle, I do like the internal cables - it looks great. In the future I
|
||||||
|
can simply use the old cables to pull new ones though.
|
||||||
|
|
||||||
|
> Note: run the cables before you install the crankset.
|
||||||
|
|
||||||
|
Once all the cables were in place, I moved onto the derailleurs. The rear was completely
|
||||||
|
free of surprises. I attached it and was able to line everything up with no issues. It
|
||||||
|
just took a couple of turns of the limit screws.
|
||||||
|
|
||||||
|
The front derailleur was a different story though.
|
||||||
|
|
||||||
|
<img src="https://assets.cowley.tech/file/cowley-tech-assets/IMG_20190525_211249774.jpg" class="article-image" />
|
||||||
|
|
||||||
|
You can see in the photo that the bolts for the mount itself have round heads. As a result,
|
||||||
|
the derailleur body fouls on them and it is impossible to line it up correctly with
|
||||||
|
the chain ring. This was not a major problem, as I could simply replace them with some
|
||||||
|
counter-sunk M5x15 bolts I had in stock. Once that was done, all was well.
|
||||||
|
|
||||||
|
Next up I decided to install my saddle and this was the biggest stumbling block.
|
||||||
|
The seatpost clamp came as 2 parts, 2 bolts to hold them in place and a pair of cylinder
|
||||||
|
nuts. These did not actually correspond to what was needed. Specifically, the bolt
|
||||||
|
that is at the front and threads down into the seat post. Both bolts included were M6,
|
||||||
|
**but** the thread cut into the seat post was for an M7. So, obviously, it did not fit:
|
||||||
|
|
||||||
|
{{< video "https://assets.cowley.tech/file/cowley-tech-assets/VID_20190508_162433918.mp4" >}}
|
||||||
|
|
||||||
|
This sent me once again searching around in my box of bits for a single M7x50 bolt. However,
|
||||||
|
M7 is an incredibly rare diameter. I eventually found an Amazon store in Germany that would
|
||||||
|
sell a pack of 10 for €26 - a lot for a single bolt (I will probably never use the other 9).
|
||||||
|
|
||||||
|
Once they arrived, I was able to continue the build. As you can see from the video above,
|
||||||
|
the front bolt goes in from the top. Fortunately I have a saddle with a cutout, but without
|
||||||
|
that I am not sure how one would actually get an allen key on to the bolt as the saddle
|
||||||
|
would be in the way. It holds securely though, so in the end all is good.
|
||||||
|
|
||||||
|
# How Does It Ride?
|
||||||
|
|
||||||
|
This is the important bit isn't it. I won't mince words: it is brilliant.
|
||||||
|
|
||||||
|
It is much smoother than the aluminium Felt, but also really stiff. I am sure a SuperSix or a
|
||||||
|
Tarmac would be at least as good, but certainly not 5 times as good. Admittedly, I have been off
|
||||||
|
the bike for several months, so have lost a LOT of power (about 30-40%), but I cannot get the
|
||||||
|
thing to flex.
|
||||||
|
|
||||||
|
When I stamp on the pedals it leaps away as fast as I am currently capable and has plenty in
|
||||||
|
reserve. As I get my strength back (and lose the kgs I've gained) I think it will improve with
|
||||||
|
me. Going down hill it is fast and precise. I have got it up to 70km/h for now with not
|
||||||
|
even a hint of speed wobble.
|
||||||
|
|
||||||
|
Going up there is no doubt that it is not the bike that slows me down. It is a budget
|
||||||
|
build, so is not particularly light (Tiagra cranks for example). Honestly, I am struggling
|
||||||
|
with a lowered power-to-weight ratio, but I will definitely be upgrading various components
|
||||||
|
to make it lighter.
|
||||||
|
|
||||||
|
It is kind of aero - the seat tube hugs the rear wheel, and it has aero cross-section tubes. The
|
||||||
|
seat post is tear drop shaped, other tubes have Kamm-tails. I have not seen any aero testing,
|
||||||
|
but it certainly feels fast. I do think I have lot a little less speed that I should have done.
|
||||||
|
|
||||||
|
Despite all this, it is pretty comfortable. I am still running 23mm tyres and there is definitely
|
||||||
|
space or 25mm, may be 28. I have not changed because my GP4000s were still nearly good
|
||||||
|
as new, so I will run them down. TYre size makes a big difference, but I do not have
|
||||||
|
any excessive vibrations - less than the Felt. I'm looking forward to trying it with
|
||||||
|
25s though.
|
||||||
|
|
||||||
|
It certainly does not have anything "special" about its ride. It does not have an
|
||||||
|
intangible "italian stallion" flair, nor does it feel like I am on a magic carpet and
|
||||||
|
I could not care less - I am an engineer, not an artist. This frame is stiff, light and
|
||||||
|
fast, but also comfortable.
|
||||||
|
|
||||||
|
A common complaint with carbon frames is that the seat post slips. This has not at all been
|
||||||
|
the case for me and it is solid as a rock.
|
||||||
|
|
||||||
|
# Conclusion
|
||||||
|
|
||||||
|
The negative:
|
||||||
|
|
||||||
|
- Despite what is on the Aliexpress photos, there are no guides for the internal cables
|
||||||
|
- Wrong bolts included for the seat clamp.
|
||||||
|
- Round head bolts for the front derailleur mount inhibit alignment of the derailleur
|
||||||
|
- The supplier refused to accept any responsibility for the wrong bolts.
|
||||||
|
|
||||||
|
Pros:
|
||||||
|
|
||||||
|
- Fast
|
||||||
|
- Stiff
|
||||||
|
- Comfortable.
|
||||||
|
|
||||||
|
Some of the negatives are pretty major - the seat post clamp bolts in particular. This means
|
||||||
|
that frame is more expensive than its sticker price. I wish it had a threaded bottom bracket.
|
||||||
|
Given what I paid for it though, even with the ridiculously expensive bolts, I really feel I have
|
||||||
|
got an absolute bargain.
|
||||||
|
|
||||||
|
Would I recommend this route for everyone? Honestly no. You have to be happy working on your
|
||||||
|
bike. Not only do you have to build it up yourself, but I can almost guarantee that no
|
||||||
|
bike shop will ever want to work on it. There were techincal issues with the build that
|
||||||
|
I had to resolve myself. I am that way inclined though, so it is not a big problem for me. If
|
||||||
|
you are not, then stick to Specialized, Trek, Cannondale et al. You will get a great bike
|
||||||
|
and great service. If however, you are techically inclined and have a decent tool kit, I
|
||||||
|
wholeheartedly recommend going the Chinese open mold route. You get a **lot** of bike for
|
||||||
|
your money.
|
||||||
|
|
||||||
|
This is a frame which will happily take better equipment, which I every intention of putting
|
||||||
|
on it. A pair of chinese, deep-section, carbon wheels are very tempting.
|
||||||
|
|
||||||
|
|
||||||
|
## Aside: What tools I had to buy
|
||||||
|
|
||||||
|
I had a pretty well stocked toolkit before, but I still needed to get a few things:
|
||||||
|
|
||||||
|
- [Torque spanner](https://www.chainreactioncycles.com/fr/en/x-tools-t-bar-torque-wrench-1-12nm/rp-prod175042)
|
||||||
|
- [Toothless saw blade](https://www.chainreactioncycles.com/fr/en/birzman-carbon-saw-blade/rp-prod172284)
|
||||||
|
|
||||||
|
I probably should have bought a [bearing press](https://www.chainreactioncycles.com/fr/en/x-tools-press-fit-bottom-bracket-installer/rp-prod155423) but I did not. Instead I did something like [this](https://www.youtube.com/watch?v=HGfvO-ztoT4) which works fine, but you have to be careful to ensure the cups go in straight.
|
||||||
59
content/blog/extend-cached-logical-volume/index.md
Normal file
|
|
@ -0,0 +1,59 @@
|
||||||
|
---
|
||||||
|
date: 2017-05-03
|
||||||
|
title: Extend cached Logical Volume
|
||||||
|
category: linux
|
||||||
|
---
|
||||||
|
|
||||||
|
You cannot do this directly for reasons that I have not tried to understand, but I suspect "it is hard" may have something to do with it.
|
||||||
|
|
||||||
|
The process is:
|
||||||
|
|
||||||
|
1. Mark your cached LV as `uncached`
|
||||||
|
2. Extended your LV
|
||||||
|
3. Recreate your cache
|
||||||
|
|
||||||
|
Simple, except there are some gotchas. The process of uncaching your LV will delete your cache volumes, so you may need to find out how you previously created them. I used:
|
||||||
|
|
||||||
|
```
|
||||||
|
[root@localhost ~]# lvs -a -o +devices
|
||||||
|
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices
|
||||||
|
root cl -wi-ao---- 7.09g /dev/vda2(231)
|
||||||
|
swap cl -wi-ao---- 924.00m /dev/vda2(0)
|
||||||
|
[cache] data Cwi---C--- 512.00m 0.61 0.75 0.00 cache_cdata(0)
|
||||||
|
[cache_cdata] data Cwi-ao---- 512.00m /dev/vdc(1)
|
||||||
|
[cache_cmeta] data ewi-ao---- 12.00m /dev/vdc(129)
|
||||||
|
lv data Cwi-aoC--- 5.00g [cache] [lv_corig] 0.61 0.75 0.00 lv_corig(0)
|
||||||
|
[lv_corig] data owi-aoC--- 5.00g /dev/vdb(0)
|
||||||
|
[lv_corig] data owi-aoC--- 5.00g /dev/vdc(0)
|
||||||
|
[lvol0_pmspare] data ewi------- 12.00m /dev/vdc(132)
|
||||||
|
```
|
||||||
|
|
||||||
|
Here you can see:
|
||||||
|
|
||||||
|
* that my cached LV is `lv`
|
||||||
|
* it uses `cache` for its pool
|
||||||
|
* The LV `[cache]` has 2 other lines associated with it:
|
||||||
|
* `[cache_cdata]` and `[cache_cmeta]`
|
||||||
|
* Both on `/dev/vdc`
|
||||||
|
* 512MB and 12MB respectively
|
||||||
|
* In the `Devices` column, `lv` that is on `lv_corig`
|
||||||
|
* itself on `/dev/vdb` and `/dev/vdc`
|
||||||
|
|
||||||
|
From all that we know our basic volume data is stored on `/dev/vdb` and cached on `/dev/vdc`. Naturally this means that our new device will `/dev/vdd`, although check first with `lsblk`.
|
||||||
|
|
||||||
|
```
|
||||||
|
pvcreate /dev/vdd
|
||||||
|
vgexend data /dev/vdd
|
||||||
|
|
||||||
|
# remove the cache and extend the volume
|
||||||
|
lvconvert --uncache data/lv
|
||||||
|
lvextend -L +1G data/lv /dev/vdd
|
||||||
|
|
||||||
|
# Recreate the cache using the data you collected above
|
||||||
|
lvcreate -L 512M -n cache data /dev/vdc
|
||||||
|
lvcreate -L 12M -n cache_meta data /dev/vdc
|
||||||
|
lvconvert --type cache-pool --cachemode writethrough --poolmetadata data/cache_meta data/cache
|
||||||
|
lvconvert --type cache --cachepool data/cache data/lv
|
||||||
|
```
|
||||||
|
|
||||||
|
Now you can resize the file system if necessary, but that is left as a (not very difficult) exercise for the reader.
|
||||||
44
content/blog/got-a-new-saddle/index.md
Normal file
|
|
@ -0,0 +1,44 @@
|
||||||
|
---
|
||||||
|
date: 2015-05-21
|
||||||
|
title: Got a New Saddle
|
||||||
|
category: cycling
|
||||||
|
featured_image: /images/82H3FWFl.jpg
|
||||||
|
---
|
||||||
|
|
||||||
|
I recently got myself a new saddle. The one that came with my Felt F95
|
||||||
|
was starting to rattle on its rails which was driving me, and my riding
|
||||||
|
buddies, insane. We are all engineers, so OCD is a shared problem we
|
||||||
|
have.
|
||||||
|
|
||||||
|
Anyway, while scanning through [my favourite non-local bike
|
||||||
|
shop](http://www.wiggle.co.uk) I came across the [Selle Italia Q-Bik
|
||||||
|
Flow](http://www.selleitalia.com/en/prodotti/road/pagina_sl/), for only
|
||||||
|
€15. Buying something as personal as a saddle online is always a risk,
|
||||||
|
but I figured that at the price it was not that much of a risk. I
|
||||||
|
promptly bought it (along with some new brakes and handlebar tape -
|
||||||
|
reviews to come), it arrived on Tuesday and I put it all on that
|
||||||
|
evening.
|
||||||
|
|
||||||
|
First, it looks great! I got it in white and it certainly does not look
|
||||||
|
like a €15 saddle. I did not weigh it, but it feels light too, so I can
|
||||||
|
believe Selle Italia's 280g claim.
|
||||||
|
|
||||||
|
In the last 2 days I have racked up about 100km on it:
|
||||||
|
|
||||||
|
<iframe height='405' width='590' frameborder='0' allowtransparency='true' scrolling='no' src='https://www.strava.com/activities/308653151/embed/fc988715669c27f5139068c72dd69f493f874495'></iframe>
|
||||||
|
<iframe height='405' width='590' frameborder='0' allowtransparency='true' scrolling='no' src='https://www.strava.com/activities/308117028/embed/5a80110feab45b012a0fe4429ee9b3afddbcae3a'></iframe>
|
||||||
|
Plus perhaps ~20km that I did not record.
|
||||||
|
|
||||||
|
I have the impression it sits slightly high on its rails compared to my
|
||||||
|
old saddle. Certainly I have had to nudge my seat post down a few
|
||||||
|
millimetres. That may also be because the old saddle has sunk however.
|
||||||
|
|
||||||
|
Over all though, it is incredibly comfortable. Firm yes, as any road
|
||||||
|
bike saddle is, but by no means painful. After each longer ride, I had
|
||||||
|
no numb nuts and could quite happily of carried on. This morning I did
|
||||||
|
end up riding over a road that was being prepared for resurfacing - that
|
||||||
|
hurt a bit, but that is not really fault of the saddle.
|
||||||
|
|
||||||
|
I am really happy with it. While there are plenty of lighter saddles
|
||||||
|
around, they are considerably more expensive. For the price there is
|
||||||
|
nothing I can complain about that would not be totally unreasonable.
|
||||||
95
content/blog/got-some-new-cycling-gear/index.md
Normal file
|
|
@ -0,0 +1,95 @@
|
||||||
|
---
|
||||||
|
date: 2015-12-11
|
||||||
|
title: Got some new cycling gear
|
||||||
|
category: cycling
|
||||||
|
featured_image: /images/dhb-vaeon-roubaix-windslam.png
|
||||||
|
---
|
||||||
|
|
||||||
|
I\'ve been shopping! I\'ve recently bought myself a new pair of pair of
|
||||||
|
bib tights (for the full Dave Lee Roth effect) and a new jersey. More
|
||||||
|
specifically I\'ve bought [DHB Vaeon Roubaix padded
|
||||||
|
tights](https://www.wiggle.co.uk/dhb-vaeon-roubaix-padded-bib-tight/)
|
||||||
|
and a [DHB Windslam
|
||||||
|
jersey](https://www.wiggle.co.uk/dhb-windslam-long-sleeve-jersey/).
|
||||||
|
|
||||||
|
DHB is the house brand of online cycle megastore
|
||||||
|
[Wiggle](https://www.wiggle.co.uk). Wiggle are based in Portsmouth,
|
||||||
|
which is where I studied, lived for 10 years, met my wife and where both
|
||||||
|
my children were born. As a result, I probably have a slightly bias
|
||||||
|
opinion of them - I could justifiably call them my LBS after all. I will
|
||||||
|
try and put any bias aside however and just give an honest opinion here
|
||||||
|
though.
|
||||||
|
|
||||||
|
DHB may be a house brand, but that does not mean Wiggle are just chosing
|
||||||
|
from the menu of some anonymous Chinese factory. I know for fact that
|
||||||
|
they have passionate cyclist designers working hard to make there gear
|
||||||
|
the best they can. I know this because I was introduced to them by other
|
||||||
|
parents at my sons\' school who work at Wiggle (my old LBS remember).
|
||||||
|
They put a lot of effort into there clothing and it shows.
|
||||||
|
|
||||||
|
Both are what Wiggle call \"Performance Fit\". This means that it is
|
||||||
|
tailored tight, but not quite to the point of the stuff they make for
|
||||||
|
their pro riders. Whatever, I can tell you that there is not a single
|
||||||
|
bit of fabric flapping around which is great - aero is everything after
|
||||||
|
all. In both cases I took a small (I am 5\'5 and weigh 61kg for
|
||||||
|
reference) and the fit is perfect).
|
||||||
|
|
||||||
|
<img class='image-process-article-image' src='/images/dhb Vaeon Roubaix Padded Bib Tight.jpg' />
|
||||||
|
|
||||||
|
The tights are Lombardia lycra which is quality stuff, usually seen on
|
||||||
|
garments costing 2 or 3 times the price. They look great - all black
|
||||||
|
with just the right amount of highlighting and reflective material to
|
||||||
|
make me visible in the dark. The fit is (for me) absolutely spot on,
|
||||||
|
although your mileage may vary here. If you have exactly the same shaped
|
||||||
|
bottom as I do the chamois is perfect. I have tree trunk thighs for my
|
||||||
|
size and often find the edge of the chamois rubs on my inner thighs,
|
||||||
|
this one does not. As the name suggests they have a roubaix fabric
|
||||||
|
lining. Wiggle say they are good for 8-15deg Celcius, but I strongly
|
||||||
|
disagree. So far I have worn them in conditions ranging from 3-12
|
||||||
|
degrees for both gentle and full gas rides. At 3 deg Celcius I was more
|
||||||
|
than warm enough, even riding gently. For me these will easily be
|
||||||
|
wearable below freezing. At 15 deg Celcius, to be honest, anyone not
|
||||||
|
wearing shorts is just weak.
|
||||||
|
|
||||||
|
<img class='image-process-article-image' src='/images/5360082447 - Mens Windslam LS Jersey - frnt.jpg' />
|
||||||
|
|
||||||
|
The jersey is equally good. Again the fit is perfect for me. Initially I
|
||||||
|
thought that the sleeves were a little long, but in fact once on the
|
||||||
|
bike they are about right. It has full length zip which seems sturdy
|
||||||
|
enough. On the back there are 3 pockets, plus an extra small pocket with
|
||||||
|
a zip. My phone (Moto G) fits in there in its wallet nicely along with
|
||||||
|
my badge for work. Here is one area I will critise this jersey - if
|
||||||
|
anything the pockets are little too deep. Getting an energy bar, or my
|
||||||
|
keys, out of them is a little awkward when walking. It is better on the
|
||||||
|
bike, but I would still take an inch off them perhaps. The front panel
|
||||||
|
of the jersey is what gives it its _Windslam_ name as it has a wind
|
||||||
|
resistant layer which seems to work nicely. Around 10 deg Celcius I have
|
||||||
|
been wearing it on its own over the bibs, below about 7 deg Celcius I
|
||||||
|
put a MTB jersey underneath and I am comfortable. One final thing, and
|
||||||
|
this is my only real critism, is that it is sold as blue. I would say it
|
||||||
|
is more a turquoise - my bike is properly blue, so it does not match as
|
||||||
|
well as I had hoped.
|
||||||
|
|
||||||
|
As DHB is a house brand, it is amazing value too. The RRPs are €67.79
|
||||||
|
and €49.99 for the tights and jersey respectively. In terms of fit and
|
||||||
|
quality, they compare favourably with the likes of Castelli and Rapha
|
||||||
|
which cost considerably more. Now add in the fact the Wiggle often sells
|
||||||
|
them 50% off and the value for money is quite simply off the charts.
|
||||||
|
|
||||||
|
So, the important stuff. Does it make me faster? Incredibly I would say
|
||||||
|
actually yes. I feel better on the bike, I can move around easily and
|
||||||
|
with no fabric flapping around I am more aero, at least on paper. I
|
||||||
|
think I am seeing this in my speed too. According to Strava I am
|
||||||
|
actually 2-3km/h faster since I got these, which equates to nearly 10
|
||||||
|
minutes on my commute home! That is not something to be sniffed at.
|
||||||
|
|
||||||
|
Finally, the service was amazing! I ordered on Black Friday and it
|
||||||
|
arrived at the relay point for me to collect (in France) the Tuesday
|
||||||
|
afternoon (with free delivery).
|
||||||
|
|
||||||
|
Am I happy with my purchase? Damn right!
|
||||||
|
|
||||||
|
Disclaimer: I paid for these out of my own pocket and Wiggle have never
|
||||||
|
even offered me anything - despite the fact I am fast turning into
|
||||||
|
self-powered advert for them and sing their praises to anyone that
|
||||||
|
listens.
|
||||||
199
content/blog/highly-available-nfs-slash-nas/index.md
Normal file
|
|
@ -0,0 +1,199 @@
|
||||||
|
---
|
||||||
|
date: 2012-03-19
|
||||||
|
title: Highly Available NFS/NAS
|
||||||
|
category: linux
|
||||||
|
---
|
||||||
|
|
||||||
|
Take 2 Centos Servers (nfs1 and nfs2 will do nicely) and install ELrepo
|
||||||
|
and EPEL on them both:
|
||||||
|
|
||||||
|
yum install \
|
||||||
|
https://download.fedoraproject.org/pub/epel/6/i386/epel-release-6-5.noarch.rpm \
|
||||||
|
https://elrepo.org/elrepo-release-6-4.el6.elrepo.noarch.rpm --nogpgcheck
|
||||||
|
|
||||||
|
Each of them should ideally have 2 NICS, with the secondary ones just
|
||||||
|
used for DRBD sync purposes. We'll give these the address 10.0.0.1/32
|
||||||
|
and 10.0.0.2/32.
|
||||||
|
|
||||||
|
I am also assuming that you have disabled the firewall and SELinux -- I
|
||||||
|
do not recommend that for production, but for testing it is fine.
|
||||||
|
|
||||||
|
# DRBD Configuration
|
||||||
|
|
||||||
|
Install DRBD 8.4 on the both:
|
||||||
|
|
||||||
|
yum install drbd84-utils kmod-drbd84
|
||||||
|
|
||||||
|
On each node the file /etc/drbd.d/global\_common.conf should contain:
|
||||||
|
|
||||||
|
global {
|
||||||
|
usage-count yes;
|
||||||
|
}
|
||||||
|
common {
|
||||||
|
net {
|
||||||
|
protocol C;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
and /etc/drbd.d/main.res should contain:
|
||||||
|
|
||||||
|
resource main {
|
||||||
|
on nfs1 {
|
||||||
|
device /dev/drbd0;
|
||||||
|
disk /dev/sdb;
|
||||||
|
address 10.0.0.1:7788;
|
||||||
|
meta-disk internal;
|
||||||
|
}
|
||||||
|
on nfs2 {
|
||||||
|
device /dev/drbd0;
|
||||||
|
disk /dev/sdb;
|
||||||
|
address 10.0.0.2:7788;
|
||||||
|
meta-disk internal;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
On both nodes you will need to create the resource metadata:
|
||||||
|
|
||||||
|
drbdadm create-md main
|
||||||
|
|
||||||
|
and start the daemons
|
||||||
|
|
||||||
|
service drbd start
|
||||||
|
chkconfig drbd on
|
||||||
|
|
||||||
|
Now `service drbd status` will give you:
|
||||||
|
|
||||||
|
drbd driver loaded OK; device status:
|
||||||
|
version: 8.4.1 (api:1/proto:86-100)
|
||||||
|
GIT-hash: 91b4c048c1a0e06777b5f65d312b38d47abaea80 build by dag@Build64R6, 2011-12-21 06:08:50
|
||||||
|
m:res cs ro ds p mounted fstype
|
||||||
|
0:main Connected Secondary/Secondary Inconsistent/Inconsistent C
|
||||||
|
|
||||||
|
Both devices or secondary and inconsistent, this is normal at this
|
||||||
|
stage. Choose a node to be your primary and run:
|
||||||
|
|
||||||
|
drbdadm primary --force main
|
||||||
|
|
||||||
|
And it start sync'ing, which will take a long time. You can temporarily
|
||||||
|
make it faster with (on one node:
|
||||||
|
|
||||||
|
drbdadm disk-options --resync-rate=110M main
|
||||||
|
|
||||||
|
Put it back again with drbdadm adjust main
|
||||||
|
|
||||||
|
On your primary node you can now create a fiiesystem. I'm using ext4 for
|
||||||
|
no good reason other than it being the default. Use whatever you are
|
||||||
|
most comfortable with.
|
||||||
|
|
||||||
|
mkfs.ext4 /dev/drbd0
|
||||||
|
|
||||||
|
# Configure NFS
|
||||||
|
|
||||||
|
If you diid a minimal Centos install, then you willl need to install the
|
||||||
|
nfs-utils package (yum install nfs-utils). Prepare your mount points and
|
||||||
|
exports on both servers:
|
||||||
|
|
||||||
|
mkdir /drbd
|
||||||
|
echo "/drbd/main *(rw)" >> /etc/exports
|
||||||
|
|
||||||
|
Now we do the actual NFS set up. We previously choose nfs1 as our master
|
||||||
|
when you used it to trigger the initial sync. On nfs1 mount the
|
||||||
|
replicated volumes, move the NFS data to it, then create symlinks to our
|
||||||
|
replicated data.
|
||||||
|
|
||||||
|
mount /dev/drbd0 /drbd
|
||||||
|
mkdir /drbd/main
|
||||||
|
mv /var/lib/nfs/ /drbd/
|
||||||
|
ln -s /drbd/nfs/ /var/lib/nfs
|
||||||
|
umount /drbd
|
||||||
|
|
||||||
|
If you get errors about not bring able to remove directories in
|
||||||
|
/var/lib/nfs do not worry.
|
||||||
|
|
||||||
|
Now a little preparation on nfs2:
|
||||||
|
|
||||||
|
mv /var/lib/nfs /var/lib/nfs.bak
|
||||||
|
ln -s /drbd/nfs/ /var/lib/nfs
|
||||||
|
|
||||||
|
This will create a broken symbolic link, but it will be fixed when
|
||||||
|
everything fails over.
|
||||||
|
|
||||||
|
# Heartbeat Configuration
|
||||||
|
|
||||||
|
Heartbeat is in the EPEL repository, so enable that and install it on
|
||||||
|
both nodes:
|
||||||
|
|
||||||
|
yum -y install heartbeat
|
||||||
|
|
||||||
|
Make sure that */etc/ha.d/ha.cf* contains:
|
||||||
|
|
||||||
|
keepalive 2
|
||||||
|
deadtime 30
|
||||||
|
bcast eth0
|
||||||
|
node nfs1 nfs2
|
||||||
|
|
||||||
|
The values in node should be whatever `uname -n` returns.
|
||||||
|
|
||||||
|
Now create `/etc/ha.d/haresources`:
|
||||||
|
|
||||||
|
nfs1 IPaddr::10.0.0.100/24/eth0 drbddisk::main Filesystem::/dev/drbd0::/drbd::ext4 nfslock nfs
|
||||||
|
|
||||||
|
That is a little cryptic, so I'll explain; nfs1 is the primary node,
|
||||||
|
IPaddr sets up a floating address on eth0 that our clients will connect
|
||||||
|
to. This has a resource drbddisk::main bound to it, which sets our main
|
||||||
|
to resource to primary on nfs1. Filesystem mounts /dev/drbd0 at /drbd on
|
||||||
|
nfs1. Finally the the services nfslock and nfs are started on nfs1.
|
||||||
|
|
||||||
|
Finally, it needs an authentication file in /etc/ha.d/authkeys, which
|
||||||
|
should be chmod'ed to 600 to be only readable by root.
|
||||||
|
|
||||||
|
auth 3
|
||||||
|
3 md5 mypassword123
|
||||||
|
|
||||||
|
You should also make sure that nfslock and nfs do not start up by
|
||||||
|
themselves:
|
||||||
|
|
||||||
|
chkconfig nfs off
|
||||||
|
chkconfig nfslock off
|
||||||
|
|
||||||
|
Now you can start heartbeat and check it is working:
|
||||||
|
|
||||||
|
service heartbeat start
|
||||||
|
chkconfig heartbeat on
|
||||||
|
|
||||||
|
# Testing
|
||||||
|
|
||||||
|
Running `ifconfig` on nfs1 should give you something like:
|
||||||
|
|
||||||
|
eth0 Link encap:Ethernet HWaddr 52:54:00:84:73:BD
|
||||||
|
inet addr:10.0.0.1 Bcast:10.0.0.255 Mask:255.255.255.0
|
||||||
|
inet6 addr: fe80::5054:ff:fe84:73bd/64 Scope:Link
|
||||||
|
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||||
|
RX packets:881922 errors:0 dropped:0 overruns:0 frame:0
|
||||||
|
TX packets:1302012 errors:0 dropped:0 overruns:0 carrier:0
|
||||||
|
collisions:0 txqueuelen:1000
|
||||||
|
RX bytes:239440621 (228.3 MiB) TX bytes:5791818459 (5.3 GiB)
|
||||||
|
|
||||||
|
eth0:0 Link encap:Ethernet HWaddr 52:54:00:84:73:BD
|
||||||
|
inet addr:10.0.0.100 Bcast:10.0.0.255 Mask:255.255.255.0
|
||||||
|
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
|
||||||
|
|
||||||
|
lo Link encap:Local Loopback
|
||||||
|
inet addr:127.0.0.1 Mask:255.0.0.0
|
||||||
|
inet6 addr: ::1/128 Scope:Host
|
||||||
|
UP LOOPBACK RUNNING MTU:16436 Metric:1
|
||||||
|
RX packets:2 errors:0 dropped:0 overruns:0 frame:0
|
||||||
|
TX packets:2 errors:0 dropped:0 overruns:0 carrier:0
|
||||||
|
collisions:0 txqueuelen:0
|
||||||
|
RX bytes:224 (224.0 b) TX bytes:224 (224.0 b)
|
||||||
|
|
||||||
|
Note an entry for `eth0:0` has miraculously appeared.
|
||||||
|
|
||||||
|
Also `df` should include the entry:
|
||||||
|
|
||||||
|
/dev/drbd0 20G 172M 19G 1% /drbd
|
||||||
|
|
||||||
|
Reboot nfs1 and the services should appear on nfs2.
|
||||||
|
|
||||||
|
Connect an NFS client to you floating address (10.0.0.100) and you
|
||||||
|
should be able to kill the live node and it will carry on.
|
||||||
105
content/blog/home-made-energy-bars/index.md
Normal file
|
|
@ -0,0 +1,105 @@
|
||||||
|
---
|
||||||
|
date: 2014-05-10
|
||||||
|
title: Home-made Energy Bars
|
||||||
|
category: cycling
|
||||||
|
Thumbail: https://i.imgur.com/RUF1L6e.jpg
|
||||||
|
---
|
||||||
|
|
||||||
|
A break from computing today and into the world of nutrition. Cyclists
|
||||||
|
love to talk about nutrition as the nature of our sport makes it a major
|
||||||
|
consideration. I do not really know of any other sport where your fuel
|
||||||
|
gives out before the rest of your body.
|
||||||
|
|
||||||
|
This means that cycling nutrition is big business, and expensive. A
|
||||||
|
typical box of energy bars will cost about 1 euro a bar from a big box
|
||||||
|
pusher, more from your LBS. To that end (as I like baking) I decided to
|
||||||
|
make my own.
|
||||||
|
|
||||||
|
# Ingredients
|
||||||
|
|
||||||
|
There is not much to it:
|
||||||
|
|
||||||
|
- 200g sugar
|
||||||
|
- 120ml oil
|
||||||
|
- 2 tablespoons honey
|
||||||
|
- 225g porridge oats
|
||||||
|
- 250g fruit/nut mix
|
||||||
|
|
||||||
|
Obviously the quality of these ingredients is all important. With the
|
||||||
|
amount you are saving compared to a commercial bar, one can afford to
|
||||||
|
splash out here. I use:
|
||||||
|
|
||||||
|
- Unrefined sugar
|
||||||
|
- Good quality sunflower oil
|
||||||
|
- Organic honey from a local producer
|
||||||
|
- Good quality, thick rolled oats
|
||||||
|
|
||||||
|
For the fruit and nut mix you can do whatever you want. We eat a lot of
|
||||||
|
these and get them from a local organic produce shop. I just raid the
|
||||||
|
kitchen draws and see what I come up with. The latest batch had:
|
||||||
|
|
||||||
|
- dried banana
|
||||||
|
- raisins
|
||||||
|
- sultanas
|
||||||
|
- coconut
|
||||||
|
- cranberries
|
||||||
|
|
||||||
|
# Recipe
|
||||||
|
|
||||||
|
You will need a decent sized saucepan as you\'ll do all the mixing on
|
||||||
|
the hob. Pre-heat the oven to 180ᵒC (350ᵒF/gas mark 4 I believe).
|
||||||
|
|
||||||
|
Start by gently melting together the sugar, oil and honey over a low
|
||||||
|
heat. Be patient, this will take a while.
|
||||||
|
|
||||||
|
Add you fruit/nut mix and mix it all in thouroughly. At this point you
|
||||||
|
will need enormous will power as the mixture is delicious and you may
|
||||||
|
find yourself eating it all there and then. This will make you feel
|
||||||
|
rather ill (trust me).
|
||||||
|
|
||||||
|
Finally, add the oats a little bit at a time. It is very important to
|
||||||
|
take your time over this. The mixture gets really thick and heavy, which
|
||||||
|
may be too much for your puny cyclist arms. If you can find a way to
|
||||||
|
stir it with your super-mega strong cyclist legs please tell me in the
|
||||||
|
comments. If not, just ask your wife/mother/mother-in-law/child to help.
|
||||||
|
|
||||||
|
Once all that is nicly mixed together transfer it to a tin lined with
|
||||||
|
baking paper (25cm x 15cm should be a good size). Make sure it is firmly
|
||||||
|
pressed down with a metal fork. If not the bar will come apart in your
|
||||||
|
pocket (messy).
|
||||||
|
|
||||||
|
Put in the oven for about 15 minutes. When it is nicely golden, take it
|
||||||
|
out and leave it to cool before cutting it up. I find this makes 25-30
|
||||||
|
small bars (\~23-50g each), but your mileage may vary.
|
||||||
|
|
||||||
|
# Nutritional Information
|
||||||
|
|
||||||
|
Of course, this being a geeky blog I had to do some maths and
|
||||||
|
comparisons. Note that this is all calculated from the information on
|
||||||
|
the packets and searching on the internet. I am an engineer, not a
|
||||||
|
nutritionist so do not take this as gospel.
|
||||||
|
|
||||||
|
-------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||||
|
Bar weight Energy Protein Fat
|
||||||
|
(g) (kcal) (g) (g)
|
||||||
|
-------------------------------------------------------------------------------------------------------------------------- --------- -------- --------- -----
|
||||||
|
Mine \~25-30 134 1.2 6.1
|
||||||
|
|
||||||
|
[SiS 55 223 20 6.4
|
||||||
|
Rego](https://www.scienceinsport.com/sis-products/sis-rego-range/sis-rego-protein/sis-rego-protein-bar-choc-peanut-55g/)
|
||||||
|
|
||||||
|
[High5 Energy Bar](https://highfive.co.uk/product/energy/energybar) 60 194 3 2
|
||||||
|
-------------------------------------------------------------------------------------------------------------------------------------------------------------
|
||||||
|
|
||||||
|
Mine do not do too badly. Not that both those commercial options have
|
||||||
|
more everything, but they are also much bigger. Two of my bars would
|
||||||
|
beat both of them hands down in all 3 of those measures. It should also
|
||||||
|
be noted that all the fat in these come from the oil and the oats, which
|
||||||
|
is \"healthy fat\" according to High 5.
|
||||||
|
|
||||||
|
Like I said, I am an engineer, not a nutritionist. Do not take this as
|
||||||
|
nutritional advise, rather as me sharing something I find works for me.
|
||||||
|
Feel free to use this, but please share your modifications. In fact you
|
||||||
|
are legally obliged to because it is under the [Creative Commons
|
||||||
|
Attribution-NonCommercial-ShareAlike 4.0 International
|
||||||
|
License](https://creativecommons.org/licenses/by-nc-sa/4.0/) :-).
|
||||||
52
content/blog/home-made-energy-drink/index.md
Normal file
|
|
@ -0,0 +1,52 @@
|
||||||
|
---
|
||||||
|
date: 2013-08-01
|
||||||
|
title: Home-made Energy Drink
|
||||||
|
category: cycling
|
||||||
|
featured_image: https://farm8.staticflickr.com/7120/7645659336_357c65c781.jpg
|
||||||
|
---
|
||||||
|
|
||||||
|
This is a post which breaks from the normal subjects of Linux
|
||||||
|
and storage.
|
||||||
|
|
||||||
|
Today I am going to share a very simple recipe for what I drink when I
|
||||||
|
am cycling. I have some fairly simple requirements for this. 1. It must
|
||||||
|
work (it must rehydrate me effectively) 1. It must not be a rip off 1. I
|
||||||
|
want to have a at least a reasonable idea of what is in it.
|
||||||
|
|
||||||
|
You can spend a small fortune on these drinks. Exercise nutrition is big
|
||||||
|
business, but starting at roughly 1 euro a bottle (3-4 euros a day at
|
||||||
|
this time of year, plus my hay fever medicines) they can get pricey.
|
||||||
|
|
||||||
|
In reality you need 3 things:
|
||||||
|
|
||||||
|
1. Water, and plenty of it
|
||||||
|
2. Sugar to give you back the fuel you burn.
|
||||||
|
3. Salt to help you absorb the fluid
|
||||||
|
|
||||||
|
I use 500ml bottles from my [LBS](https://www.laboutiqueducycle.fr/)
|
||||||
|
that I chose for very technical reasons (they gave them to me free).
|
||||||
|
|
||||||
|
The important thing to get right is the proportions. Not enough sugar
|
||||||
|
and you will not replace the glucose that you burn, too much and you
|
||||||
|
will struggle to absorb it. Likewise with salt, not enough and you\'re
|
||||||
|
absorption rate will be to slow, too much and it will 1) taste nasty and
|
||||||
|
2) dehydrate you.
|
||||||
|
|
||||||
|
For each 500ml bottle I go for:
|
||||||
|
|
||||||
|
- 3 teaspoon sugar (15-20g)
|
||||||
|
- 2-3 pinchs of salt
|
||||||
|
|
||||||
|
That would taste disgusting, so add a touch of fruit squash to taste. I
|
||||||
|
use Grenadine, because the children love it so it always in the fridge,
|
||||||
|
but a sugar-free squash would be fine or a dash for fresh fruit juice.
|
||||||
|
To allow for the extra sugar in the Grenadine, I cut down the added
|
||||||
|
sugar by 1 teaspoon.
|
||||||
|
|
||||||
|
Finally, I use unrefined sugar and for the salt I use [Sel de
|
||||||
|
Guérande](https://en.wikipedia.org/wiki/Gu%C3%A9rande#Salt_marshes).
|
||||||
|
That way I know I am using the best quality ingredients, something I am
|
||||||
|
sure the likes of Gatorade do not do.
|
||||||
|
|
||||||
|
Final cost is minimal, but it seems to work for me. Everyone is
|
||||||
|
different, so these levels need adjusting for you.
|
||||||
126
content/blog/how-i-classify-puppet-nodes/index.md
Normal file
|
|
@ -0,0 +1,126 @@
|
||||||
|
---
|
||||||
|
date: 2015-09-10
|
||||||
|
title: How I Classify Puppet Nodes
|
||||||
|
category: devops
|
||||||
|
---
|
||||||
|
|
||||||
|
The basics of defining what modules get applied to a particular node is
|
||||||
|
really simple in Puppet. Out of the box you just use the hostname and
|
||||||
|
the FQDN and everyone is happy. You find this everywhere in
|
||||||
|
documentation, blog posts, presentations, etc. However is has a problem:
|
||||||
|
scale.
|
||||||
|
|
||||||
|
What if you have an elastic infrastructure with nodes being created and
|
||||||
|
destroyed automatically? What if you want to use the same manifests in
|
||||||
|
different environment, but use different hostnames? What if you have
|
||||||
|
stupidly complex host naming conventions that you cannot get your head
|
||||||
|
round (current day job problem for me :-( )?
|
||||||
|
|
||||||
|
In all these cases and more, using the hostname to classify the node
|
||||||
|
falls down. I like to add in Role that can then be access in 2 ways.
|
||||||
|
With Hiera, one could do something like:
|
||||||
|
|
||||||
|
```
|
||||||
|
:hierarchy:
|
||||||
|
- "nodes/%{::trusted.certname}"
|
||||||
|
- "roles/%{role}"
|
||||||
|
- "%{environment}"
|
||||||
|
- "%{osfamily}-osreleasemajor"
|
||||||
|
- global
|
||||||
|
```
|
||||||
|
|
||||||
|
And with in `site.pp` we can add in a simple `case` statement:
|
||||||
|
|
||||||
|
```
|
||||||
|
node default {
|
||||||
|
case $::role {
|
||||||
|
'loadbalancer': {
|
||||||
|
class { 'haproxy': }
|
||||||
|
}
|
||||||
|
'db': {
|
||||||
|
class { 'mysql': }
|
||||||
|
}
|
||||||
|
default: {
|
||||||
|
notify('no specific classes assigned')
|
||||||
|
}
|
||||||
|
}
|
||||||
|
class { 'security': }
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, we can still classify nodes individually but there is something in
|
||||||
|
between the wider environment and OS categories that we can define
|
||||||
|
ourselves. Of course we now need to define the role, which is everywhere
|
||||||
|
from simple to complex or even not completely clear in my head for now.
|
||||||
|
|
||||||
|
I create a custom role fact that my manifests will look at. This is
|
||||||
|
universal, no matter what mechanism is used to populate that fact that
|
||||||
|
is the only place I will search in my Puppet code.
|
||||||
|
|
||||||
|
When your nodes are under Openstack or EC2, this is simple. They both
|
||||||
|
have the concept of user-defined metadata as key-value pairs. I simple
|
||||||
|
add a role pair:
|
||||||
|
|
||||||
|
```
|
||||||
|
nova meta <instance-id> set role=loadbalancer
|
||||||
|
```
|
||||||
|
|
||||||
|
You can also set this when you create the instance.
|
||||||
|
|
||||||
|
```
|
||||||
|
nova boot --meta role=loadbalancer --<other-settings> <hostname>
|
||||||
|
```
|
||||||
|
|
||||||
|
Now we just need the fact to look it up.
|
||||||
|
|
||||||
|
```
|
||||||
|
require 'net/http'
|
||||||
|
require 'json'
|
||||||
|
require 'uri'
|
||||||
|
|
||||||
|
module RoleModule
|
||||||
|
def self.add_facts
|
||||||
|
Facter.add("role") do
|
||||||
|
productname = Facter.value(:productname)
|
||||||
|
case productname
|
||||||
|
when 'OpenStack Nova'
|
||||||
|
setcode do
|
||||||
|
url= "http://169.254.169.254/openstack/latest/meta_data.json"
|
||||||
|
uri = URI.parse(url)
|
||||||
|
http = Net::HTTP.new(uri.host,uri.port)
|
||||||
|
response = http.get(uri.path)
|
||||||
|
JSON.parse(response.body)['meta']['role']
|
||||||
|
end
|
||||||
|
when 'ProLiant MicroServer'
|
||||||
|
setcode do
|
||||||
|
'lab-compute'
|
||||||
|
end
|
||||||
|
end
|
||||||
|
end
|
||||||
|
end
|
||||||
|
end
|
||||||
|
RoleModule.add_facts
|
||||||
|
```
|
||||||
|
|
||||||
|
What is happening here? First it checks the productname fact so it can
|
||||||
|
work out what to do. If that is OpenStack Nova then it knows that is
|
||||||
|
needs to look in the Openstack Metadata service
|
||||||
|
(<http://169.254.169.254/openstack/latest/meta_data.json>). Our
|
||||||
|
key/value pair is returned as part of that JSON data and is pushed in to
|
||||||
|
the role fact.
|
||||||
|
|
||||||
|
Likewise, if the productname is an HP Microserver, it will always be a
|
||||||
|
lab compute node (in my case).
|
||||||
|
|
||||||
|
Physical machines otherwise fall down here. There is no way to
|
||||||
|
dynamically modify their role, but I have a couple of solutions:
|
||||||
|
|
||||||
|
- Part of the kickstart file for provisioning the node could populate
|
||||||
|
a configuration file (`/etc/role.conf`). If the `virtual` fact
|
||||||
|
contains `physical` the role fact goes and looks it up from there.
|
||||||
|
- A seperate node classification service that returns a role based on
|
||||||
|
the contents of various facts that are passed via the custom fact
|
||||||
|
code.
|
||||||
|
|
||||||
|
The important part with both of these is the classification is totally
|
||||||
|
seperate from my Puppet code.
|
||||||
74
content/blog/how-much-should-you-spend-on-it/index.md
Normal file
|
|
@ -0,0 +1,74 @@
|
||||||
|
---
|
||||||
|
date: 2013-02-06
|
||||||
|
title: How much should you spend on IT
|
||||||
|
category: Opinions
|
||||||
|
---
|
||||||
|
|
||||||
|
A recent discussion/argument I had on Reddit got me thinking about the
|
||||||
|
cost of solutions we put in.
|
||||||
|
|
||||||
|
In an ideal world everything would have full redundancy, and the
|
||||||
|
customer would never have any downtime. Everything would always be
|
||||||
|
up-to-date and keeping it so would require restarting. The reality is
|
||||||
|
very different unfortunately.
|
||||||
|
|
||||||
|
This potentially rambling post was inspired by someone accusing me of
|
||||||
|
having "a horrible idea" because I suggested someone put pfsense on an
|
||||||
|
Atom PC as a VPN router for a small office. He then proceeded to expain
|
||||||
|
to me how you should always buy an expensive black box from a vendor (he
|
||||||
|
didn't say black box if I am honest, I am interpreting), how you have
|
||||||
|
to always have support on absolutely everything. I called 'bullshit'
|
||||||
|
and the whole thing went round in circles a bit until we both realised
|
||||||
|
that were actually singing from the same song sheet, but from different
|
||||||
|
ends of the room.
|
||||||
|
|
||||||
|
When looking at a solution it is always necessary to
|
||||||
|
look at the actual requirements of the end-user. I had a
|
||||||
|
conversation with a Director at \$lastjob once. We had recently had a
|
||||||
|
planned outage on the website for a few minutes one Sunday night so I
|
||||||
|
could de-commission the old SAN. He said that he wanted us to get to
|
||||||
|
99.999% IT uptime. My reply after some quick calculations was that we
|
||||||
|
had actually achieved that for the last 3 years at least, but that I
|
||||||
|
would not like to guarantee it in the future with our current and
|
||||||
|
planned infrastructure. This lead to him asking me to go ahead and do
|
||||||
|
the calculations on how to guarantee it. When I went back to him with my
|
||||||
|
figure (done using lots of Open Source, and no vendor support) he
|
||||||
|
changed his mind. This was in what would be classed as an SME - heading
|
||||||
|
towards £100 million a year turnover and one of world's best in their
|
||||||
|
field. Not a small company by any means, but they could not justify that
|
||||||
|
cost.
|
||||||
|
|
||||||
|
Having said that they could justify a lot. All our servers were
|
||||||
|
clustered, storage was Fibre-channel, they had a 100TB 8Gb array for a
|
||||||
|
team of 2 people who crunched monster video files all day. All that was
|
||||||
|
justified expenditure, but they were not an internet company, so a bit
|
||||||
|
of downtime could be justified. Even when we had a major disaster and a
|
||||||
|
large swathe of Linux VMs disappeared from this world, nobody actually
|
||||||
|
had to stop working and no money was lost.
|
||||||
|
|
||||||
|
A small business is not going to dump the money for multi-thousand pound
|
||||||
|
Cisco router and a zero-contention synchronous internet connection. They
|
||||||
|
may think that they need the best of everything, they may even be
|
||||||
|
willing to pay for it if they have got enough of daddy's funding behind
|
||||||
|
them. However that would be foolish, that money would be better spent on
|
||||||
|
giving everyone a Christmas bonus.
|
||||||
|
|
||||||
|
Support contracts are another bone of contention. Now everything I have
|
||||||
|
is under one, but that is not always necessary. I once needed to get a
|
||||||
|
couple of TBs of storage into a large office asap. I happenned to have a
|
||||||
|
few FC HBAs, a couple of old Proliants and a pile of MSA1000s in a
|
||||||
|
cupboard. I built up a box with a pair of HBAs and a single MSA1000 and
|
||||||
|
sent the whole lot up to the office with strict instructions that all
|
||||||
|
the extras were for spares only. If something broke, no need for support
|
||||||
|
- just swap it out. I figured it would be good for at least another 3
|
||||||
|
years. Especially as backups were pretty reliable there. Would a new SAN
|
||||||
|
with expensive support have been more reliable, I doubt it. We would
|
||||||
|
have to wait 4 hours for a new disk, rather than the 5 minutes a took to
|
||||||
|
walk to the cupboard.
|
||||||
|
|
||||||
|
It is not always necessary to get the shiniest stuff,
|
||||||
|
with the longest/quickest support contract. We know our gear, we know
|
||||||
|
how reliable it is, we know how long it lasts. The people paying the
|
||||||
|
bills do not, they rely on us to advise them honestly and wisely. That
|
||||||
|
wisdom can fall at either end of the price-spectrum, but needs
|
||||||
|
to be based on the ACTUAL risks and their effect.
|
||||||
|
|
@ -0,0 +1,29 @@
|
||||||
|
---
|
||||||
|
date: 2016-04-14
|
||||||
|
title: I just Fixed the pro-peloton disc brake problem
|
||||||
|
category: cycling
|
||||||
|
---
|
||||||
|
|
||||||
|
There has been boo-hoo-hooing the last few days about an injury sustained by Francisco Ventoso at Paris-Roubaix.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Yes that spongey looking bit is his bone. It is seriously nasty and the UCI have [re-banned disc brakes](http://www.cyclingnews.com/news/uci-suspends-road-disc-brakes-in-races-after-ventoso-injury/) as a result.
|
||||||
|
|
||||||
|
However, the fact is that disc brakes are a **lot** better than rim brakes. Rim brakes suck - especially in the wet. On carbon rims they suck even more even in the dry. In the wet, you may as well just give up. Ok, I am exagerating, a bit. It is not power which is the big difference though, but control. With a hydraulic disc, you can dial in just the amount you want. Overall this will mean less crashes - very important when you have 200 people all trying to share the same bit of road.
|
||||||
|
|
||||||
|
There is admittedly a problem though, they are like big spinning knives. I would say that they are not the most dangerous think on a bike though. As GCN demonstrate in the video below, spokes are probably worse.
|
||||||
|
|
||||||
|
<iframe width="560" height="315" src="https://www.youtube.com/embed/JplymlruPZ8" frameborder="0" allowfullscreen></iframe>
|
||||||
|
|
||||||
|
The problem is that current disc rotors have the cross-section shown below:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
They have square corners, so yes that will be pretty sharp when it is spinning fast. I have a solution to this:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Yes, simply machine down the shoulders so they are rounded instead of square. Now you no longer have spinning knives, more like spinning spoons.
|
||||||
|
|
||||||
|
So there you go Shimano, SRAM and Campagnolo, I just fixed disc brakes for you.
|
||||||
|
|
@ -0,0 +1,134 @@
|
||||||
|
---
|
||||||
|
date: 2015-05-05
|
||||||
|
title: Identify and mounting Cinder Volumes in Openstack Heat
|
||||||
|
category: devops
|
||||||
|
---
|
||||||
|
|
||||||
|
I\'m back playing with Openstack again. The day job once again Openstack
|
||||||
|
based, and as of last week my lab is all Openstack too. While
|
||||||
|
[oVirt](http://ovirt.org) is awesome, I felt like a change.
|
||||||
|
|
||||||
|
Anyway, the meat of today\'s problem comes from the day job. I have some
|
||||||
|
instances deployed via heat that have multiple Cinder volumes attached
|
||||||
|
to them, these then need to be mounted in a certain way. The syntax for
|
||||||
|
attaching a cinder volume to an instance is:
|
||||||
|
|
||||||
|
instance_vol_att:
|
||||||
|
type: OS::Cinder::VolumeAttachment
|
||||||
|
properties:
|
||||||
|
instance_uuid: { get_resource: instance }
|
||||||
|
volume_id: { get_resource: instance_vol_data }
|
||||||
|
mountpoint: /dev/vdb
|
||||||
|
|
||||||
|
See at the end there is `mountpoint`? Awesome, my device will always
|
||||||
|
appear as /dev/vdb!
|
||||||
|
|
||||||
|
No! Unfortunately, there is no link between Cinder/Nova and *udev*
|
||||||
|
within the instance. As a result, udev will simply assign it a device
|
||||||
|
name in the same way your workstation does to a USB key: it could be
|
||||||
|
anything.
|
||||||
|
|
||||||
|
So what is a poor Openstack admin to do?
|
||||||
|
|
||||||
|
Each volume has a UUID, which in the example above. Lets start with a
|
||||||
|
simple HOT template to create a single instance and volume:
|
||||||
|
|
||||||
|
heat_template_version: 2014-10-16
|
||||||
|
description: A simple server to run Jenkins
|
||||||
|
|
||||||
|
parameters:
|
||||||
|
imageid:
|
||||||
|
type: string
|
||||||
|
default: Centos-7-x64
|
||||||
|
description: Image use to boot a server
|
||||||
|
|
||||||
|
resources:
|
||||||
|
jenkins:
|
||||||
|
type: OS::Nova::Server
|
||||||
|
properties:
|
||||||
|
image: { get_param: ImageID }
|
||||||
|
flavor: m1.tiny
|
||||||
|
networks:
|
||||||
|
- network: { get_param: NetID }
|
||||||
|
jenkins_data:
|
||||||
|
type: OS::Cinder::Volume
|
||||||
|
properties:
|
||||||
|
size: 50G
|
||||||
|
jenkins_data_att:
|
||||||
|
type: OS::Cinder::VolumeAttachment
|
||||||
|
properties:
|
||||||
|
instance_uuid: { get_resource: jenkins }
|
||||||
|
volume_id: { get_resource: jenkins_data}
|
||||||
|
|
||||||
|
That will create everything we need. The rest we need to pass though
|
||||||
|
from Nova to the instance somehow. While Nova does not talk to udev, it
|
||||||
|
does pass the `volume_id` though, albeit with a caveat. the ID is
|
||||||
|
truncated to **20** characters and is available as
|
||||||
|
`/dev/disk/by-id/virtio-volid20chars`. We can now access this using the
|
||||||
|
userdata property and `cloud-init`.
|
||||||
|
|
||||||
|
I actually create a small bash script then run it later, so now my
|
||||||
|
*Server* resource will look like:
|
||||||
|
|
||||||
|
jenkins:
|
||||||
|
type: OS::Nova::Server
|
||||||
|
properties:
|
||||||
|
image: { get_param: ImageID }
|
||||||
|
flavor: m1.tiny
|
||||||
|
networks:
|
||||||
|
- network: { get_param: NetID }
|
||||||
|
user_data_format: RAW
|
||||||
|
user_data:
|
||||||
|
str_replace:
|
||||||
|
template: |
|
||||||
|
#cloud-config
|
||||||
|
write_files:
|
||||||
|
- content: |
|
||||||
|
#!/bin/bash
|
||||||
|
voldata_id="%voldata_id%"
|
||||||
|
voldata_dev="/dev/disk/by-id/virtio-$(echo ${voldata_id} | cut -c -20)"
|
||||||
|
mkfs.ext4 ${voldata_dev}
|
||||||
|
mkdir -pv /var/lib/jenkins
|
||||||
|
echo "${voldata_dev} /var/lib/jenkins ext4 defaults 1 2" >> /etc/fstab
|
||||||
|
mount /var/lib/jenkins
|
||||||
|
path: /tmp/format-disks
|
||||||
|
permissions: '0700'
|
||||||
|
runcmd:
|
||||||
|
- /tmp/format-disks
|
||||||
|
params:
|
||||||
|
"%voldata_id%": { get_resource: jenkins_data }
|
||||||
|
jenkins_data:
|
||||||
|
type: OS::Cinder::Volume
|
||||||
|
properties:
|
||||||
|
size: 50
|
||||||
|
jenkins_data_att:
|
||||||
|
type: OS::Cinder::VolumeAttachment
|
||||||
|
properties:
|
||||||
|
instance_uuid: { get_resource: jenkins }
|
||||||
|
volume_id: { get_resource: jenkins_data}
|
||||||
|
|
||||||
|
What is happenning here? I create 3 resources:
|
||||||
|
|
||||||
|
- a server
|
||||||
|
- a volume
|
||||||
|
- a volume attachment
|
||||||
|
|
||||||
|
Within the server there is a *cloud-init* script passed in via
|
||||||
|
*user*data\_. This cloud-init script is created using a template which
|
||||||
|
has a single parameter. This parameter is `%voldata_id%` - I put `%`
|
||||||
|
symbols around all my variables in this context, it makes false matches
|
||||||
|
pretty much impossible. The `get_resource` command collects the ID of
|
||||||
|
the Cinder volume I created.
|
||||||
|
|
||||||
|
Now we move into the *cloud-init* script created which does 2 things:
|
||||||
|
|
||||||
|
- creates a bash script, including the variable for the ID
|
||||||
|
- launches that scripts
|
||||||
|
|
||||||
|
The Bash script calculates what the device will be (`$voldata_dev`),
|
||||||
|
formats it and mounts it at the mountpoint it creates. It also adds this
|
||||||
|
into `/etc/fstab` for the future.
|
||||||
|
|
||||||
|
This can easily be used for multiple volumes. All one does is add an
|
||||||
|
extra parameter to collect the extra resources, then extend the Bash
|
||||||
|
script to do them too.
|
||||||
|
|
@ -0,0 +1,25 @@
|
||||||
|
---
|
||||||
|
date: 2016-03-03
|
||||||
|
title: If you are affected by DROWN you are an idiot
|
||||||
|
category: Opinions
|
||||||
|
featured_image: http://i.imgur.com/3ARTSc7.jpg
|
||||||
|
---
|
||||||
|
|
||||||
|
[Drown](https://drownattack.com/) is the latest vulnerability in OpenSSL.
|
||||||
|
Essentially it allows an attacker to decrypt your TLS session and get data out
|
||||||
|
of that session.
|
||||||
|
|
||||||
|
The thing is, it is based on a vulnerability in SSLv**2**! Here lies my
|
||||||
|
problem with this: SSLv2 has been known to be insecure for 20 years. Not only
|
||||||
|
that, but SSLv3 also and even TLS1.0 (effectively SSLv4).
|
||||||
|
|
||||||
|
The number of clients requiring even support for TLS1.0 is miniscule now, so
|
||||||
|
anyone who has still got those algos enabled is clearly an idiot. They
|
||||||
|
should be fired for gross-incompetence quite honestly.
|
||||||
|
|
||||||
|
Those using Nginx (that would be me) who are affected are even worse. Since 2009, SSLv2 is disabled by default in Nginx, so they would have had to actively enable an already broken protocol.
|
||||||
|
|
||||||
|
Anyone who sees DROWN and does anything other than yawn and shrug is
|
||||||
|
a blithering idiot who should not be in IT. I could however do with some
|
||||||
|
cheap (€1/hr at best) labour to clear the ditch at the end of my garden.
|
||||||
|
Maybe they will at least be able to manage that.
|
||||||
78
content/blog/in-praise-of-old-school-unix/index.md
Normal file
|
|
@ -0,0 +1,78 @@
|
||||||
|
---
|
||||||
|
date: 2013-02-05
|
||||||
|
title: In praise of old school UNIX
|
||||||
|
category: linux
|
||||||
|
---
|
||||||
|
|
||||||
|
What am I doing today? Documentation that is what. I am writing a
|
||||||
|
document on how to do
|
||||||
|
[this](https://www.chriscowley.me.uk/blog/2012/11/19/sftp-chroot-on-centos/).
|
||||||
|
To any Linux user it is a very simple process and I could just give them
|
||||||
|
a link to my own website.
|
||||||
|
|
||||||
|
I am not writing this for a technical audience though. The people who
|
||||||
|
are going to perform this work will be the 'Level 1 operatives'. This
|
||||||
|
translates roughly to "anyone we can find on the street corners of some
|
||||||
|
Far East city". If I tell them to press the red button labelled "press
|
||||||
|
me" and it turns out to be orange, they will stop. I cannot assume the
|
||||||
|
ability to edit a file in Vi. How can you work around this, well you
|
||||||
|
need to make everything a copy and paste operation. This is easily done
|
||||||
|
in Bash thanks to IO redirection and of course Sed.
|
||||||
|
|
||||||
|
Now, a brief recap may be in order, as there are some perfectly
|
||||||
|
knowledgable Linux users who do not know what Sed is. Really, one of
|
||||||
|
them sits behind me. Sed stands for Stream EDitor, and it parses text
|
||||||
|
and applies transformations to it. It was one of the first UNIX
|
||||||
|
utilities. It kind of sits between
|
||||||
|
[Grep](https://en.wikipedia.org/wiki/Grep) and
|
||||||
|
[Awk](https://en.wikipedia.org/wiki/AWK_programming_language) and is
|
||||||
|
[surprisingly powerful](https://uuner.doslash.org/forfun/).
|
||||||
|
|
||||||
|
Anyway, I need to edit a line in a file then add a block of code at the
|
||||||
|
end.
|
||||||
|
|
||||||
|
cp -v /etc/ssh/sshd_config{,.dist}
|
||||||
|
sed -i ''/^Subsystem/s#/usr/libexec/openssh/sftp-server#internal-sftp#g' \
|
||||||
|
/etc/ssh/sshd_config
|
||||||
|
|
||||||
|
First line obviously is a contracted cp line which puts the suffix
|
||||||
|
*.dist* on the copy.
|
||||||
|
|
||||||
|
The basic idea is that it runs through the file (/etc/ssh/sshd\_config)
|
||||||
|
and looks for any line that starts with "Subsystem" (`/^Subsystem/`).
|
||||||
|
If it finds a line that matches it then will perform a "substituion"
|
||||||
|
(`/s#`). The next 2 blocks tell it what the substitution will be in the
|
||||||
|
order "\#From\#To\#". The reason for the change from `/` to `#` is
|
||||||
|
because of the / in the path name (thanks to
|
||||||
|
[Z0nk](https://www.reddit.com/user/z0nk) for reminding me that you can
|
||||||
|
use arbitary seperators). The "\#g" tells Sed to perform the
|
||||||
|
substituion on every instance it finds on the line, rather than just the
|
||||||
|
first one. It is completely superfluous in this example, but I tend to
|
||||||
|
put it in from force of habit. Finally the "-i" tells Sed to perform
|
||||||
|
the edit in place, rather than outputing to Stdout.
|
||||||
|
|
||||||
|
The next bit is a bit cleverer. With a single command I want to add a
|
||||||
|
block of text to the file.
|
||||||
|
|
||||||
|
cat <<EOF | while read inrec; do echo $inrec >> /etc/ssh/sshd_config; done
|
||||||
|
Match Group transfer
|
||||||
|
ChrootDirectory /var/local/
|
||||||
|
ForceCommmand internal-sftp
|
||||||
|
X11Forwarding no
|
||||||
|
AllowTcpForwarding no
|
||||||
|
|
||||||
|
EOF
|
||||||
|
|
||||||
|
Here `cat <<EOF` tells it send everything you type to Stdout until it
|
||||||
|
sees the string EOF. This then gets piped to a `while` loop that appends
|
||||||
|
each line of that Stdout to the file we want to extend
|
||||||
|
(*/etc/ssh/sshd*config\_ in this case).
|
||||||
|
|
||||||
|
Using these old tools and a bit of knowledge of how redirection works
|
||||||
|
has enabled me to make a document that anyone who can copy/paste can
|
||||||
|
follow. It is very easy for technical people to forget that not everyone
|
||||||
|
has the knowledge we have. To us opening Vi is perfectly obvious, but to
|
||||||
|
others maybe it isn't and they are not being paid enough to know. They
|
||||||
|
are just being paid to follow a script. I may not like it, but it is the
|
||||||
|
case - it also helped turn a boring documentation session into something
|
||||||
|
a little more interesting. Which is nice!
|
||||||
|
|
@ -0,0 +1,37 @@
|
||||||
|
---
|
||||||
|
date: 2014-07-28
|
||||||
|
title: Install Microsoft TrueType fonts on Fedora
|
||||||
|
category: linux
|
||||||
|
featured_image: https://i.imgur.com/IVNu1pf.png
|
||||||
|
---
|
||||||
|
|
||||||
|
Fedora do not bundle Microsoft's core Truetype fonts for licensing
|
||||||
|
reasons. Normallly I do not care, personally I prefer [Liberation
|
||||||
|
fonts](https://fedorahosted.org/liberation-fonts/) anyway. However,
|
||||||
|
today I needed Verdana.
|
||||||
|
|
||||||
|
Traditionally, the way to install these on RPM based distributions has
|
||||||
|
been:
|
||||||
|
|
||||||
|
1. Grab the RPM spec file
|
||||||
|
2. Build an RPM from the spec file
|
||||||
|
3. Install RPM using the `rpm` command.
|
||||||
|
|
||||||
|
All well and good, however there are a couple of problems.
|
||||||
|
|
||||||
|
- Using RPM directly is frowned upon
|
||||||
|
|
||||||
|
Nowadays, Yum does various bits of house keeping in addition to RPM, so
|
||||||
|
this can lead to the `rpm` and `yum` databases getting their knickers in
|
||||||
|
a twist.
|
||||||
|
|
||||||
|
I get around this with a simple piece of `sed`/`grep`:
|
||||||
|
|
||||||
|
curl https://corefonts.sourceforge.net/msttcorefonts-2.0-1.spec | grep -v 'Prereq: /usr/sbin/chkfontpath' > msttcorefonts-2.0-1.spec
|
||||||
|
|
||||||
|
Now you can do all the usual stuff:
|
||||||
|
|
||||||
|
rpmbuild -ba msttcorefonts-2.0-1.spec
|
||||||
|
yum --nogpgcheck ~/rpmbuild/RPMS/noarch/msttcorefonts-2.0-1.noarch.rpm
|
||||||
|
|
||||||
|
Relogin and you will have access to Microsoft\'s fonts.
|
||||||
168
content/blog/installing-and-managing-sensu-with-puppet/index.md
Normal file
|
|
@ -0,0 +1,168 @@
|
||||||
|
---
|
||||||
|
date: 2014-12-18
|
||||||
|
title: Installing and Managing Sensu with Puppet
|
||||||
|
category: devops
|
||||||
|
---
|
||||||
|
|
||||||
|
As promised in the [previous
|
||||||
|
post](/blog/2014/11/18/installing-rabbitmq-on-centos-7/), I thought I
|
||||||
|
would share my Sensu/Puppet config. This is based on the Puppet
|
||||||
|
infrastucture I decribed
|
||||||
|
[here](/blog/2014/06/25/super-slick-agile-puppet-for-devops/) so
|
||||||
|
everything goes into Hiera.
|
||||||
|
|
||||||
|
<!-- more -->
|
||||||
|
For reasons best known to me (or my DHCP server) my Sensu host is on
|
||||||
|
192.168.1.108.
|
||||||
|
|
||||||
|
First your `Puppetfile` tells R10k to install the Sensu module, plus a
|
||||||
|
few more:
|
||||||
|
|
||||||
|
mod 'nanliu/staging'
|
||||||
|
mod 'puppetlabs/rabbitmq'
|
||||||
|
mod 'sensu/sensu'
|
||||||
|
|
||||||
|
mod 'redis',
|
||||||
|
:git => 'https://github.com/chriscowley/chriscowley-redis.git',
|
||||||
|
:commit => '208c01aaf2435839ada26d3f7187ca80517fa2a8
|
||||||
|
|
||||||
|
I tend to put my classes and their parameters in Hiera. My
|
||||||
|
`hieradata/common.yaml` contains:
|
||||||
|
|
||||||
|
---
|
||||||
|
classes:
|
||||||
|
- rabbitmq
|
||||||
|
- redis
|
||||||
|
- sensu
|
||||||
|
rabbitmq::port: '5672'
|
||||||
|
sensu::install_repo: true
|
||||||
|
sensu::purge_config: true
|
||||||
|
sensu::rabbitmq_host: 192.168.1.108
|
||||||
|
sensu::rabbitmq_password: password
|
||||||
|
sensu::rabbitmq_port: 5672
|
||||||
|
sensu::rabbitmq_vhost: '/sensu'
|
||||||
|
sensu::use_embedded_ruby: true
|
||||||
|
sensu::subscriptions:
|
||||||
|
- base
|
||||||
|
|
||||||
|
This will do all the configuration for all your nodes. More
|
||||||
|
specifically:
|
||||||
|
|
||||||
|
- tells RabbitMQ to communicate on 5672/TCP
|
||||||
|
- Installs Sensu from their own repo
|
||||||
|
- All Sensu config will be controlled by Puppet
|
||||||
|
- Configures the Sensu client:
|
||||||
|
- RabbitMQ host is 192.168.1.108
|
||||||
|
- password is `password`
|
||||||
|
- RabbitMQ server is listening on 5672/TCP
|
||||||
|
- RabbitMQ vhost is /sensu
|
||||||
|
- Run plugins using Ruby embedded with Sensu, not system. This comes
|
||||||
|
with the *sensu-plugins* gem which is required by any community
|
||||||
|
plugins.
|
||||||
|
- Subscribe to the `base` set of plugins
|
||||||
|
|
||||||
|
Next up, to configure your master, ensure that
|
||||||
|
`hieradata/nodes/monitor.whatever.com.yaml` contains:
|
||||||
|
|
||||||
|
---
|
||||||
|
classes:
|
||||||
|
sensu::server: true
|
||||||
|
sensu::api: true
|
||||||
|
|
||||||
|
This does not do everything though. All we have done here is install and
|
||||||
|
enable the Sensu server and API. Unfortunately, I have not really
|
||||||
|
settled on a good way of getting defined types into Hiera, so now we
|
||||||
|
jump into `manifests/site.pp`.
|
||||||
|
|
||||||
|
node default inherits basenode {
|
||||||
|
package { 'wget':
|
||||||
|
ensure => installed,
|
||||||
|
}
|
||||||
|
package { 'bind-utils':
|
||||||
|
ensure => installed,
|
||||||
|
}
|
||||||
|
file { '/opt/sensu-plugins':
|
||||||
|
ensure => directory,
|
||||||
|
require => Package['wget']
|
||||||
|
}
|
||||||
|
staging::deploy { 'sensu-community-plugins.tar.gz':
|
||||||
|
source => 'https://github.com/sensu/sensu-community-plugins/archive/master.tar.gz',
|
||||||
|
target => '/opt/sensu-plugins',
|
||||||
|
require => File['/opt/sensu-plugins'],
|
||||||
|
}
|
||||||
|
sensu::handler { 'default':
|
||||||
|
command => 'mail -s \'sensu alert\' ops@foo.com',
|
||||||
|
}
|
||||||
|
sensu::check { 'check_cron':
|
||||||
|
command => '/opt/sensu-plugins/sensu-community-plugins-master/plugins/processes/check-procs.rb -p crond -C 1',
|
||||||
|
handlers => 'default',
|
||||||
|
subscribers => 'base',
|
||||||
|
require => Staging::Deploy['sensu-community-plugins.tar.gz'],
|
||||||
|
}
|
||||||
|
sensu::check { 'check_dns':
|
||||||
|
command => '/opt/sensu-plugins/sensu-community-plugins-master/plugins/dns/check-dns.rb -d google-public-dns-a.google.com -s 192.168.1.2 -r 8.8.8.8',
|
||||||
|
handlers => 'default',
|
||||||
|
subscribers => 'base',
|
||||||
|
require => Staging::Deploy['sensu-community-plugins.tar.gz'],
|
||||||
|
}
|
||||||
|
sensu::check { 'check_disk':
|
||||||
|
command => '/opt/sensu-plugins/sensu-community-plugins-master/plugins/system/check-disk.rb',
|
||||||
|
handlers => 'default',
|
||||||
|
subscribers => 'base',
|
||||||
|
require => Staging::Deploy['sensu-community-plugins.tar.gz'],
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
This actually does quite a lot (halleluiah for CM). Each host will get:
|
||||||
|
|
||||||
|
- Ensures `wget` is installed and that a directory exists to hold the plugins
|
||||||
|
- Deploys those plugins, and follows HEAD. Do not do this in production - change the URL to use a particular commit/tag/whatever.
|
||||||
|
- Configures a simple handler to email alerts.
|
||||||
|
- Finally we configure a few basic plugins
|
||||||
|
- check `crond` is running
|
||||||
|
- Check name resolution works by looking up Google's public DNS server
|
||||||
|
- Check disk space
|
||||||
|
|
||||||
|
Finally, the Sensu server needs RabbitMQ configured:
|
||||||
|
|
||||||
|
node 'monitor.whatever.com' inherits default {
|
||||||
|
rabbitmq_user { 'sensu':
|
||||||
|
admin => false,
|
||||||
|
password => 'password',
|
||||||
|
}
|
||||||
|
rabbitmq_vhost { '/sensu':
|
||||||
|
ensure => present,
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
If you use Puppet agent with its defaults everything should now kind of
|
||||||
|
pull together over the next hour.
|
||||||
|
|
||||||
|
One final stage is to have some way of visualising your Sensu data.
|
||||||
|
There is a great dashboard called
|
||||||
|
[Uchiwa](https://github.com/sensu/uchiwa) for that. In the
|
||||||
|
`monitor.whatever.com` node in `manifests/site.pp` add:
|
||||||
|
|
||||||
|
$uchiwa_api_config = [{
|
||||||
|
host => 'monitor.whatever.lan',
|
||||||
|
name => 'Site 1',
|
||||||
|
port => '4567',
|
||||||
|
timeout => '5',
|
||||||
|
}]
|
||||||
|
|
||||||
|
class { 'uchiwa':
|
||||||
|
install_repo => false,
|
||||||
|
sensu_api_endpoints => $uchiwa_api_config,
|
||||||
|
user => 'admin',
|
||||||
|
pass => 'secret',
|
||||||
|
}
|
||||||
|
|
||||||
|
You could put this anywhere, but the Sensu host is as pretty logical
|
||||||
|
place to my mind.
|
||||||
|
|
||||||
|
I am not 100% happy with this, particularly some of the dependency
|
||||||
|
(packages and folders) is quite messy. It is fine for now as my lab is
|
||||||
|
very much centred around CentOS. I do have some projects on the todo
|
||||||
|
list for which I may use Debian/Ubuntu. As such I will be breaking a lot
|
||||||
|
of that out into a *localdata* module. I\'ll post details about how I do
|
||||||
|
that when I get round to it.
|
||||||
47
content/blog/installing-rabbitmq-on-centos-7/index.md
Normal file
|
|
@ -0,0 +1,47 @@
|
||||||
|
---
|
||||||
|
date: 2014-11-18
|
||||||
|
title: Installing RabbitMQ on CentOS 7
|
||||||
|
category: devops
|
||||||
|
---
|
||||||
|
|
||||||
|
Very quick as I did not find any good solutions to this on Google. This
|
||||||
|
is actually an interim post as I ran across this while configuring
|
||||||
|
[Sensu](https://sensuapp.org/) in my lab. A full post on that, along
|
||||||
|
with configuring it with [my Puppet set
|
||||||
|
up](https://www.chriscowley.me.uk/blog/2014/06/25/super-slick-agile-puppet-for-devops/)
|
||||||
|
is coming.
|
||||||
|
|
||||||
|
RabbitMQ is in EPEL (slightly old, but not drastically) so install that
|
||||||
|
first, then install from `yum`.
|
||||||
|
|
||||||
|
yum -y install https://mirrors.ircam.fr/pub/fedora/epel/7/x86_64/e/epel-release-7-2.noarch.rpm
|
||||||
|
yum -y install rabbitmq-server
|
||||||
|
|
||||||
|
Well that was easy, so just start it with
|
||||||
|
|
||||||
|
systemctl rabbitmq-server start
|
||||||
|
|
||||||
|
And it starts
|
||||||
|
|
||||||
|
\...
|
||||||
|
|
||||||
|
except it does not :-(
|
||||||
|
|
||||||
|
In fact it is blocked by 2 things:
|
||||||
|
|
||||||
|
- Firewall
|
||||||
|
- SELinux
|
||||||
|
|
||||||
|
I found an answer on
|
||||||
|
[StackOverflow](https://stackoverflow.com/questions/25816918/not-able-to-start-rabbitmq-server-in-centos-7-using-systemctl)
|
||||||
|
which was basically \"Turn it all off\". This is quite frankly an answer
|
||||||
|
for the weak! How about actually solving the problem people!
|
||||||
|
|
||||||
|
firewall-cmd --permanent --add-port=5672/tcp
|
||||||
|
firewall-cmd --reload
|
||||||
|
setsebool -P nis_enabled 1
|
||||||
|
|
||||||
|
Now you can start the service and enable it:
|
||||||
|
|
||||||
|
systemctl enable rabbitmq-server
|
||||||
|
systemctl start rabbitmq-server
|
||||||
259
content/blog/integrating-rhel-with-active-directory/index.md
Normal file
|
|
@ -0,0 +1,259 @@
|
||||||
|
---
|
||||||
|
date: 2013-12-16
|
||||||
|
title: Integrating RHEL with Active Directory
|
||||||
|
category: linux
|
||||||
|
---
|
||||||
|
|
||||||
|
I had a request on Reddit to share a document I wrote about connect Red
|
||||||
|
Hat Enterprise Linux with Active Directory. The original document I
|
||||||
|
wrote is confidential, but I said I would write it up.
|
||||||
|
|
||||||
|
This works for both Server 2008(R2) and 2012. If I recall correctly it
|
||||||
|
will also work with 2003, but may need to minor terminology changes on
|
||||||
|
the Windows side. From the Linux side, it should be fine with RHEL 6 and
|
||||||
|
similar (CentOS and Scientific Linux). It should also apply to Fedora,
|
||||||
|
but your mileage may vary.
|
||||||
|
|
||||||
|
<!-- more -->
|
||||||
|
So without further ado, let\'s dive in. To do this you need to know what
|
||||||
|
is actually happening under the surface when you authenticate to AD from
|
||||||
|
a client. The basic idea looks something like this:
|
||||||
|
|
||||||
|
{% img center
|
||||||
|
<https://docs.google.com/drawings/d/1tjaacfXrTJtOZCREonoXzdHfgZQHssQ2zkDzFpLGeX0/pub?w=960&h=720>
|
||||||
|
%}
|
||||||
|
|
||||||
|
Integration with AD requires the installation of a few services in Red
|
||||||
|
Hat, along with some minor modifications on the Windows Domain
|
||||||
|
Controllers. On the Linux side, everything revolves around the System
|
||||||
|
Security Services Daemon (SSSD). All communication between the PAM and
|
||||||
|
the various possible back-ends is brokered through this daemon. This is
|
||||||
|
only one solution, there are several. The others involve Winbind (which
|
||||||
|
I have found problematic), or LDAP/Kerberos directly (no offline
|
||||||
|
authentication, more difficult to set up). Note that this does not give
|
||||||
|
you any file sharing, but can easily be extended to do so using Samba.
|
||||||
|
|
||||||
|
PAM communicates with SSSD, which in turn talks to Active Directory via
|
||||||
|
LDAP and Kerberos. Identification is performed via LDAP, with the user
|
||||||
|
is authenticated using Kerberos. These different components have some
|
||||||
|
prerequisites on Windows.
|
||||||
|
|
||||||
|
- DNS must be working fully - both forward and reverse lookups should
|
||||||
|
be functional. If the Kerberos server (Windows Domain Controller)
|
||||||
|
cannot identify the client via DNS, Kerberos will fail.
|
||||||
|
- Accurate time is essential -- if the two systems have too larger
|
||||||
|
difference in time (about 5 minutes), Kerberos will fail.
|
||||||
|
- The Active Directory needs to be extended to include the relevant
|
||||||
|
information for \*NIX systems (home directory, shell, UUID/GUID
|
||||||
|
primarily).
|
||||||
|
- They are actually there, but empty and uneditable. The necessary GUI
|
||||||
|
fields are part of "Identity Management for UNIX"
|
||||||
|
- It must be possible for the Linux client to perform an LDAP search.
|
||||||
|
This could be either via an anonymous bind or authenticated.
|
||||||
|
- Anonymous is obviously not recommended.
|
||||||
|
- Simple binds (username/password) do work but are not recommended.
|
||||||
|
Although I am not one to practise what I preach (see below).
|
||||||
|
- The best option is SASL/GSSAPI, using a keytab generated by Samba.
|
||||||
|
This does not require Admin privileges on Windows, only permissions
|
||||||
|
to join computers to the domain.
|
||||||
|
|
||||||
|
For both DNS and NTP I\'m assuming that you are using the services
|
||||||
|
provided by Active Directory. It is possible to break those out to other
|
||||||
|
boxes, but it beyond my Windows Admin ability/desire to do so.
|
||||||
|
|
||||||
|
Preparing Active Directory
|
||||||
|
--------------------------
|
||||||
|
|
||||||
|
In Server Manager, add the Role Service \"Identity Management for
|
||||||
|
UNIX\". This is under the Role \"Active Directory Domain Services\"
|
||||||
|
(took me a while to find that). When it asks, use your AD domain name as
|
||||||
|
the NIS name. For example, with a AD domain of *chriscowley.lab*, use
|
||||||
|
*chriscowley*.
|
||||||
|
|
||||||
|
Once that is installed, create a pair of groups. For the sake of
|
||||||
|
argument, lets call them *LinuxAdmin* and *LinuxUser*. The intended
|
||||||
|
roles of these 2 groups is left as an exercise for the reader. When you
|
||||||
|
create these groups, you will see a new tab in the properties window for
|
||||||
|
both groups and users: \"UNIX Attributes\".
|
||||||
|
|
||||||
|
Now go ahead and create a user (or edit an existing one). Go into the
|
||||||
|
UNIX tab and set the configure the user for UNIX access: {% img right
|
||||||
|
<https://i.imgur.com/Ox9kuAy.png> %}
|
||||||
|
|
||||||
|
- Select the NIS domain you created earlier
|
||||||
|
- Set an approprate UUID (default should be fine)
|
||||||
|
- Set the login shell as `/bin/bash`, `/bin/sh` should be fine most of
|
||||||
|
the time, but I have seen a few odd things happen (details escape
|
||||||
|
me)
|
||||||
|
- Set the home directory. I seperate them out from local users to
|
||||||
|
something like `/home/<DOMAIN>/<username>`
|
||||||
|
|
||||||
|
Open up one of your groups (let\'s start with LinuxAdmin) and add the
|
||||||
|
user to that group. Note you have to do it 2 places (don\'t blame me, I
|
||||||
|
am just the messenger). Both in the standard Groups tab, but also in the
|
||||||
|
UNIX attributes tab.
|
||||||
|
|
||||||
|
That should be everything on the Windows side.
|
||||||
|
|
||||||
|
Configure RHEL as a client
|
||||||
|
--------------------------
|
||||||
|
|
||||||
|
Most of the heavy lifting is done by the *System Security Service
|
||||||
|
Daemon* (SSSD).
|
||||||
|
|
||||||
|
yum install sssd sssd-client krb5-workstation samba openldap-clients policycoreutils-python
|
||||||
|
|
||||||
|
This should also pull in all the dependencies.
|
||||||
|
|
||||||
|
### Configure Kerberos
|
||||||
|
|
||||||
|
I\'ve already said, this but I will repeat myself as getting it wrong
|
||||||
|
will cause many lost hours.
|
||||||
|
|
||||||
|
- DNS must be working for both forward and reverse lookups
|
||||||
|
- Time must be in sync accross all the clients
|
||||||
|
|
||||||
|
Make sure that /etc/resolv.conf contains your domain controllers.
|
||||||
|
|
||||||
|
**Gotcha**: In RHEL/Fedora the DNS setting are defined in
|
||||||
|
/etc/sysconfig/network-settings/ifcfg-eth0 (or whichever NIC comes
|
||||||
|
first) by Anaconda. This will over-write /etc/resolv.conf on reboot. For
|
||||||
|
no good reason other than stubbornness I tend to remove these entries
|
||||||
|
and define resolv.conf myself (or via configuration management).
|
||||||
|
Alternatively put DNS1 and DNS2 entries in the network configuration
|
||||||
|
files.
|
||||||
|
|
||||||
|
In `/etc/krb5.conf` change you servers to point at your Domain
|
||||||
|
Controllers.
|
||||||
|
|
||||||
|
[logging]
|
||||||
|
default = FILE:/var/log/krb5libs.log
|
||||||
|
|
||||||
|
[libdefaults]
|
||||||
|
default_realm = AD.EXAMPLE.COM
|
||||||
|
dns_lookup_realm = true
|
||||||
|
dns_lookup_kdc = true
|
||||||
|
ticket_lifetime = 24h
|
||||||
|
renew_lifetime = 7d
|
||||||
|
rdns = false
|
||||||
|
forwardable = yes
|
||||||
|
|
||||||
|
[realms]
|
||||||
|
AD.EXAMPLE.COM = {
|
||||||
|
# Define the server only if DNS lookups are not working
|
||||||
|
# kdc = server.ad.example.com
|
||||||
|
# admin_server = server.ad.example.com
|
||||||
|
}
|
||||||
|
|
||||||
|
[domain_realm]
|
||||||
|
.ad.example.com = AD.EXAMPLE.COM
|
||||||
|
ad.example.com = AD.EXAMPLE.COM
|
||||||
|
|
||||||
|
You should now be able to run:
|
||||||
|
|
||||||
|
kinit aduser@AD.EXAMPLE.COM
|
||||||
|
|
||||||
|
That should obtain a kerberos ticket (check with `klist`) and you can
|
||||||
|
move on. If it does not work fix it now - Kerberos is horrible to debug
|
||||||
|
later.
|
||||||
|
|
||||||
|
### Enable LDAP Searches
|
||||||
|
|
||||||
|
The best way to bind to AD is using SASL/GSSAPI as no passwords are
|
||||||
|
needed.
|
||||||
|
|
||||||
|
kinit Administrator@AD.EXAMPLE.COM
|
||||||
|
net ads join createupn=host/client.ad.example.com@AD.EXAMPLE.COM –k
|
||||||
|
net ads keytab create
|
||||||
|
net ads keytab add host/client.ad.example.com@AD.EXAMPLE.COM
|
||||||
|
|
||||||
|
You should now be able to get information about yourself from AD using
|
||||||
|
ldapsearch:
|
||||||
|
|
||||||
|
ldapsearch -H ldap://server.ad.example.com/ -Y GSSAPI -N -b "dc=ad,dc=example,dc=com" "(&(objectClass=user)(sAMAccountName=aduser))"
|
||||||
|
|
||||||
|
### Configure SSSD
|
||||||
|
|
||||||
|
Everything in SSSD revolves around a single config file
|
||||||
|
(/etc/sssd/ssd.conf).
|
||||||
|
|
||||||
|
[sssd]
|
||||||
|
config_file_version = 2
|
||||||
|
domains = ad.example.com
|
||||||
|
services = nss, pam
|
||||||
|
debug_level = 0
|
||||||
|
|
||||||
|
[nss]
|
||||||
|
|
||||||
|
[pam]
|
||||||
|
|
||||||
|
[domain/ad.example.com]
|
||||||
|
id_provider = ldap
|
||||||
|
auth_provider = krb5
|
||||||
|
chpass_provider = krb5
|
||||||
|
access_provider = ldap
|
||||||
|
|
||||||
|
# To use Kerberos, un comment the next line
|
||||||
|
#ldap_sasl_mech = GSSAPI
|
||||||
|
|
||||||
|
# The following 3 lines bind to AD. Comment them out to use Kerberos
|
||||||
|
ldap_default_bind_dn = CN=svc_unix,OU=useraccounts,DC=ad,DC=example,DC=com
|
||||||
|
ldap_default_authtok_type = password
|
||||||
|
ldap_default_authtok = Welcome_2014
|
||||||
|
|
||||||
|
ldap_schema = rfc2307bis
|
||||||
|
|
||||||
|
ldap_user_search_base = ,dc=ad,dc=example,dc=com
|
||||||
|
ldap_user_object_class = user
|
||||||
|
|
||||||
|
ldap_user_home_directory = unixHomeDirectory
|
||||||
|
ldap_user_principal = userPrincipalName
|
||||||
|
|
||||||
|
ldap_group_search_base = ou=groups,dc=ad,dc=example,dc=com
|
||||||
|
ldap_group_object_class = group
|
||||||
|
|
||||||
|
ldap_access_order = expire
|
||||||
|
ldap_account_expire_policy = ad
|
||||||
|
ldap_force_upper_case_realm = true
|
||||||
|
|
||||||
|
krb5_realm = AD.EXAMPLE.COM
|
||||||
|
|
||||||
|
There is something wrong here. Note the lines:
|
||||||
|
|
||||||
|
# To use Kerberos, un comment the next line
|
||||||
|
#ldap_sasl_mech = GSSAPI
|
||||||
|
|
||||||
|
# The following 3 lines bind to AD. Comment them out to use Kerberos
|
||||||
|
ldap_default_bind_dn = CN=svc_unix,OU=useraccounts,DC=ad,DC=example,DC=com
|
||||||
|
ldap_default_authtok_type = password
|
||||||
|
ldap_default_authtok = Welcome_2014
|
||||||
|
|
||||||
|
Instead of doing the SASL/GSSAPI bind I would prefer to do I have
|
||||||
|
chickened out and done a simple bind. Why? Because I am weak\... :-(
|
||||||
|
|
||||||
|
Try with kerberos first, if it works then awesome, if not then create a
|
||||||
|
service account in AD that can do nothing other than perform a search
|
||||||
|
and use that to perform the bind. Make sure its path matches that of the
|
||||||
|
*ldap\_default\_bind\_dn* path, also make sure the password is more
|
||||||
|
complex than \"Welcome\_2014\".
|
||||||
|
|
||||||
|
For now this does nothing, we need to tell PAM to use it. The easiest
|
||||||
|
way to enable this on RHEL is to use the authconfig command:
|
||||||
|
|
||||||
|
authconfig --enablesssd --enablesssdauth --enablemkhomedir –update
|
||||||
|
|
||||||
|
This will update `/etc/nsswitch.conf` and various files in `/etc/pam.d`
|
||||||
|
to tell the system to authenticate against SSSD. SSSD will in turn talk
|
||||||
|
to Active Directory, using LDAP for Identification and Kerberos for
|
||||||
|
authentication. Finally you can enable your LinuxAdmin's to use sudo.
|
||||||
|
Run the command visudo and add the line:
|
||||||
|
|
||||||
|
%LinuxAdmin ALL=(ALL) ALL
|
||||||
|
# note the % sign, the defines it as a group not a user
|
||||||
|
|
||||||
|
Now your admin's can run commands as root by prefacing them with sudo.
|
||||||
|
For an encore, I would suggest disabling root login via SSH. Log in as
|
||||||
|
your AD user (leave your root session open, just in case) and run:
|
||||||
|
|
||||||
|
sudo sed -i 's/PermitRootLogin no/PermitRootLogin yes/' /etc/ssh/sshd_config
|
||||||
|
sudo service sshd reload
|
||||||
15
content/blog/isle-of-wight-ride/index.md
Normal file
|
|
@ -0,0 +1,15 @@
|
||||||
|
---
|
||||||
|
date: 2012-07-27
|
||||||
|
title: Isle of Wight Ride
|
||||||
|
category: cycling
|
||||||
|
---
|
||||||
|
|
||||||
|
Last week I successfully did my first 65 mile ride. Of course it was not
|
||||||
|
a race, but that never stopped a group of men being over competitive - I
|
||||||
|
won by the way. I do not own a cycle computer, nor did I remember to run
|
||||||
|
My Tracks. However, a colleague did record it on his Garmin GPS:
|
||||||
|
|
||||||
|
<iframe width='465' height='548' frameborder='0' src='https://connect.garmin.com:80/activity/embed/203587506'></iframe>
|
||||||
|
|
||||||
|
<object width="400" height="300">
|
||||||
|
<embed type="application/x-shockwave-flash" src="https://www.flickr.com/apps/slideshow/show.swf?v=109615" allowFullScreen="true" flashvars="offsite=true&lang=en-us&page_show_url=%2Fphotos%2F83132329%40N04%2Fsets%2F72157630749918206%2Fshow%2F&page_show_back_url=%2Fphotos%2F83132329%40N04%2Fsets%2F72157630749918206%2F&set_id=72157630749918206&jump_to=" width="400" height="300"></embed></object>
|
||||||
23
content/blog/kubernetes-metrics-server-problem/index.md
Normal file
|
|
@ -0,0 +1,23 @@
|
||||||
|
---
|
||||||
|
date: 2019-02-01
|
||||||
|
title: Kubernetes Metrics Server Problem
|
||||||
|
category: devops
|
||||||
|
featured_image: /images/kubernetes.png
|
||||||
|
---
|
||||||
|
|
||||||
|
A simple fix for something quite annoying. I set up HPA on some deployments and it did not work.
|
||||||
|
|
||||||
|
HPA uses the [metrics-server](https://github.com/helm/charts/tree/master/stable/metrics-server) to decide when to scale a deployment, but the logs for the metrics-server pod were saying:
|
||||||
|
|
||||||
|
```
|
||||||
|
unable to fully collect metrics: unable to fully scrape metrics from source kubelet_summary:kube: unable to fetch metrics from Kubelet kube (kube): Get https://kube:10250/stats/summary/: x509: certificate signed by unknown authority
|
||||||
|
```
|
||||||
|
|
||||||
|
I have seen this on Kubernetes 1.10 at work, and 1.12 and 1.13 in my lab, so it is an on-going problem. Basically it was missing the CA certificate. The correct fix is to add this certificate into the metrics-server pod. However, for now, I have not investigated where that is. My dirty fix is to install the metrics-server Helm chart with the following values file:
|
||||||
|
|
||||||
|
```
|
||||||
|
args:
|
||||||
|
- --kubelet-insecure-tls
|
||||||
|
```
|
||||||
|
|
||||||
|
This is the equivalent of add `-k` to a `curl` command - it will ignore the CA problem. Given this is purely internal traffic I am not overly concerned. Proper fix in the comments would be welcome however.
|
||||||
59
content/blog/lezyne-minigps-review/index.md
Normal file
|
|
@ -0,0 +1,59 @@
|
||||||
|
---
|
||||||
|
date: 2019-01-21
|
||||||
|
title: Lezyne MiniGPS Review
|
||||||
|
category: cycling
|
||||||
|
featured_image: /images/Product-gps-minigpsY12-zoom2.png
|
||||||
|
---
|
||||||
|
|
||||||
|
Surprisingly for someone that is a professional geek, I actually do not really like having stats in front of me when I ride my bike. As such for years I have been happilly using a basic wireless computer from Decathlon. It was small, simple, cheap and I only changed the battery once in a blue moon. It told me how fast I was going, and the time. That is all I need and I was happy. I like to geek out, but I do that afterwards - my phone and [Strava](https://www.strava.com/athletes/1988717) work fine for that.
|
||||||
|
|
||||||
|
However, a while ago someone went past my bike and stole the computer, lights and multi-tool while it was locked up outside my office.
|
||||||
|
|
||||||
|
Aside: To the Gendermarie, if some pulls up alongside one of your officers and tells them that their lights have been stolen, they will get upset if you then try and book them for riding without lights. Especially if the remnants of the light mounts are clear to see and they are expensively dressed, you can assume they do not make habit of it.
|
||||||
|
|
||||||
|
Anyway, after a bit of riding without a computer, I decided that not having the time on bars was actually quite frustrating. I looked at a new cheapy wireless computer, but then decided that the minimal extra cost of a basic GPS was worth it.
|
||||||
|
|
||||||
|
I looked at a few:
|
||||||
|
|
||||||
|
- [Wahoo Element Mini](https://eu.wahoofitness.com/devices/bike-computers/elemnt-mini)
|
||||||
|
- [Garmin Edge 20](https://buy.garmin.com/en-US/US/p/508487)
|
||||||
|
- [Lezyne MiniGPS](https://www.lezyne.com/product-gps-minigpsY10.php)
|
||||||
|
|
||||||
|
I discounted the Garmin quite fast - it is really very limited (not even HR monitor support) and quite a bit mor expensive. Choosing between the Wahoo and the Lezyne was harder, both have a lot of features for the price, but in the end the decider was that the Lezyne charges via USB instead of the CR2032 battery the Wahoo needs. Also, it does not rely on my phone which more an observation than an advantage. I also knew from my various Lezyne lights that they know how to make something waterproof. I live in Brittany so that is pretty important.
|
||||||
|
|
||||||
|
<img class='image-process-article-image' src='/images/FNGMpcr.jpg' />
|
||||||
|
|
||||||
|
|
||||||
|
TL;DR: I am mostly happy with it, but not without reservation
|
||||||
|
|
||||||
|
## What works?
|
||||||
|
|
||||||
|
It is nice and small, which is cool. Ugly, but small enough that I don't really care. The screen is small but, as long as you are reasonable, usable. I mainly use a single screen with 2 metrics on it (speed in a large font, a time below it) and am perfectly happy. You can have up to 4 metrics at once, but that is mostly unreadable at a glance.
|
||||||
|
|
||||||
|
It records everything I want and plenty that I don't. Unlike Garmin, all Leynze units support everything irrespective of price. If I were to buy a dual-sided power meter, I am ready for it. I can record and see it on the screen. I don't see it happening, but the option is there.
|
||||||
|
|
||||||
|
The battery lasts ages, and I can just plug it in to a computer to charge it.
|
||||||
|
|
||||||
|
Syncing with my phone (via bluetooth) and uploading to Strava works pretty well. I could also do it via the computer if I wanted to use something other than Strava/TrainingPeaks. When plugged in it appears as a standard USB storage device. This means that, while Leynze only support MacOS and Windows, I have no problems getting GPX files off it in Linux (Fedora 27+ is all I have tested).
|
||||||
|
|
||||||
|
The Android app looks dated but it mostly works pretty well. At least for syncing rides.
|
||||||
|
|
||||||
|
## The fails
|
||||||
|
|
||||||
|
Upgrading firmware is awkward - you have to use either Windows or MacOS. I have done this via a Windows VM passing the USB device through and it works fine. The problem is that I always have to put it into [Bootloader mode](https://support.lezyne.com/hc/en-us/articles/360001314914-Bootloader-Mode). According to the [official video](https://www.youtube.com/watch?v=aNXobu2jocA), I have the impression this should not be necessary, but it is is.
|
||||||
|
|
||||||
|
The navigation sucks! The page to build routes is clunky and would felt old-fashioned 10 years ago. Compared to Strava's route builder, it is painful to use. It will route you down woodland tracks and roads that just do not exist. I understand that they do not have as much data as Strava do, so Lezyne should just drop that feature from GPSRoot and import routes from your Strava directly. They have a Strava Routes section on GPSRoot, but it is perpetually "in development".
|
||||||
|
|
||||||
|
If you do manage to create a route, then the actual navigation is awful anyway. It is breadcrumbs only, but that is not the problem. On a screen this size I would not expect anything different. The problem is that it is just awful. If you do a point-to-point route, then it mostly works. Even so it has a tendency to think you have gone off route, which it then tries to recalculate and never manages. Much worse is if you try and put in a loop (as most people will do most of the time). In this case it will decide you have already finished as soon as you start.
|
||||||
|
|
||||||
|
I said the Android app mostly works, but there are things that do not work. When I got it in August sending a route to the GPS from the app worked OK. But since the update 26/10/2018 (version 6.90) this fails. You send the route and the app just sits there then gives up after a couple of minutes - the GPS does nothing.
|
||||||
|
|
||||||
|
The _GPS Settings_ page in the app has never worked for me. It will eventually tell me "There is an update available" (there isn't, I am on the latest firmware) then just sit there. It may go back to reading the settings, but never actually seems to read them.
|
||||||
|
|
||||||
|
Intervals are another things, you are obliged to have a paid Training Peaks or Todays Plan account. I do not, nor do I want to. I just want to be able to put in a collection of intervals and have it time them for me. I can kind of do this with the lap timer, but I would have prefered to have this automatic.
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
As I said I am mostly happy with it. In reality it is does everthing I really need (speed, time and post-ride geeking) and it does it well. For someone who has the same needs as me, I can heartily recommend it. It does have some major bugs though - especially with routing and comms with the Android app. These are not deal breakers for me, but they may be for someone else. Especially someone who has bought one of the larger devices.
|
||||||
|
|
||||||
|
I'll give it 4/5 for me, but for many this would drop to 2/5.
|
||||||
167
content/blog/logstash-on-centos-6/index.md
Normal file
|
|
@ -0,0 +1,167 @@
|
||||||
|
---
|
||||||
|
date: 2014-03-21
|
||||||
|
title: Logstash on CentOS 6
|
||||||
|
category: devops
|
||||||
|
featured_image: /images/20140911103132_272.png
|
||||||
|
---
|
||||||
|
|
||||||
|
It's been a while since I last posted anything, but it is time to.
|
||||||
|
I've been playing around a lot with various tools for gathering
|
||||||
|
information about my environment recently. One of the most important
|
||||||
|
tools for storing that information is decent logging. Syslog is proven
|
||||||
|
and solid, but a little creaky. For storing everything it is fine, but
|
||||||
|
getting anything out is not so great.
|
||||||
|
|
||||||
|
Logstash is an awesome tool written by [Jordan
|
||||||
|
Sissel](https://twitter.com/jordansissel) that is used to "collect
|
||||||
|
logs, parse them, and store them for later use (like, for searching)".
|
||||||
|
It has an excellent howto, but I have one problem with it: the use of a
|
||||||
|
tar file rather than packages. This easily worked around though, as
|
||||||
|
Elasticsearch have it in their Yum repository.
|
||||||
|
|
||||||
|
First up, define that repository in the file
|
||||||
|
`/etc/yum.repos.d/logstash.repo`:
|
||||||
|
|
||||||
|
[logstash-1.4]
|
||||||
|
name=logstash repository for 1.4.x packages
|
||||||
|
baseurl=https://packages.elasticsearch.org/logstash/1.4/centos
|
||||||
|
gpgcheck=1
|
||||||
|
gpgkey=https://packages.elasticsearch.org/GPG-KEY-elasticsearch
|
||||||
|
enabled=1
|
||||||
|
|
||||||
|
[elasticsearch-1.0]
|
||||||
|
name=Elasticsearch repository for 1.0.x packages
|
||||||
|
baseurl=https://packages.elasticsearch.org/elasticsearch/1.0/centos
|
||||||
|
gpgcheck=1
|
||||||
|
gpgkey=https://packages.elasticsearch.org/GPG-KEY-elasticsearch
|
||||||
|
enabled=1
|
||||||
|
|
||||||
|
The rpm does not create its user and group, nor does it create the PID
|
||||||
|
directory for Kibana. Create those then install Łogstash:
|
||||||
|
|
||||||
|
mkdir /var/run/logstash-web
|
||||||
|
yum -y install logstash elasticsearch logstash-contrib.noarch mcollective-logstash-audit.noarch
|
||||||
|
chkconfig --add elasticsearch
|
||||||
|
chkconfig elasticsearch on
|
||||||
|
service elasticsearch start
|
||||||
|
|
||||||
|
For the installation that is it. When you reboot the services will start
|
||||||
|
and you are good to go. Before rebooting though it is worth playing
|
||||||
|
around a little. So lets blatantly rip off the
|
||||||
|
[Quickstart](https://logstash.net/docs/1.4.0/tutorials/getting-started-with-logstash).
|
||||||
|
Run:
|
||||||
|
|
||||||
|
sudo -u logstash /opt/logstash/bin/logstash -e 'input { stdin { } } output { stdout { codec => rubydebug } }'
|
||||||
|
|
||||||
|
Logstash takes a while to get going as it needs to fire up the JRE
|
||||||
|
(hint: run `htop` in another terminal to see when the Java process calms
|
||||||
|
down). When it is happy type (in the same console you started it in)
|
||||||
|
`hello`. You should see something like:
|
||||||
|
|
||||||
|
hello
|
||||||
|
{
|
||||||
|
"message" => "hello",
|
||||||
|
"@version" => "1",
|
||||||
|
"@timestamp" => "2014-03-21T20:56:58.439Z",
|
||||||
|
"host" => "monitor.chriscowley.lan"
|
||||||
|
}
|
||||||
|
|
||||||
|
That is not very interesting unfortunately. It just takes STDIN, the
|
||||||
|
logs it to STDOUT in a funky format. This all gets more interesting when
|
||||||
|
you start storing your logs somewhere. A good choice is (funnily enough)
|
||||||
|
Elasticsearch. This time run Logstash with this as the output:
|
||||||
|
|
||||||
|
sudo -u logstash /opt/logstash/bin/logstash -e 'input { stdin { } } output { elasticsearch { host => localhost } }'
|
||||||
|
|
||||||
|
Now if you type something in that same console (we're still taking the
|
||||||
|
input from STDIN) the output will be written to Elasticsearch.
|
||||||
|
|
||||||
|
To test that run `curl 'https://localhost:9200/_search?pretty'` in
|
||||||
|
another console and you should see something like:
|
||||||
|
|
||||||
|
{
|
||||||
|
"took" : 11,
|
||||||
|
"timed_out" : false,
|
||||||
|
"_shards" : {
|
||||||
|
"total" : 5,
|
||||||
|
"successful" : 5,
|
||||||
|
"failed" : 0
|
||||||
|
},
|
||||||
|
"hits" : {
|
||||||
|
"_index" : "logstash-2014.03.21",
|
||||||
|
"_type" : "logs",
|
||||||
|
"_id" : "aRFzhx-4Ta-jy_PC50U7Lg",
|
||||||
|
"_score" : 1.0, "_source" : {"message":"you know, for logs","@version":"1","@timestamp":"2014-03-21T21:01:17.766Z","host":"monitor.chriscowley.lan"}
|
||||||
|
}, {
|
||||||
|
"_index" : "logstash-2014.03.21",
|
||||||
|
"_type" : "logs",
|
||||||
|
"_id" : "VP8WcqOYRuCbpYgGA5S1oA",
|
||||||
|
"_score" : 1.0, "_source" : {"message":"another one for the logs","@version":"1","@timestamp":"2014-03-21T21:03:42.480Z","host":"monitor.chriscowley.lan"}
|
||||||
|
} ]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
Now that does not persist when you kill Logstash. To do that create a
|
||||||
|
file in `/etc/logstash/conf.d/` that contains this:
|
||||||
|
|
||||||
|
input {
|
||||||
|
file {
|
||||||
|
path => "/var/log/messages"
|
||||||
|
start_position => beginning
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
filter {
|
||||||
|
if [type] == "syslog" {
|
||||||
|
grok {
|
||||||
|
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
|
||||||
|
add_field => [ "received_at", "%{@timestamp}" ]
|
||||||
|
add_field => [ "received_from", "%{host}" ]
|
||||||
|
}
|
||||||
|
syslog_pri { }
|
||||||
|
date {
|
||||||
|
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
output {
|
||||||
|
elasticsearch {
|
||||||
|
host => localhost
|
||||||
|
}
|
||||||
|
stdout { codec => rubydebug }
|
||||||
|
}
|
||||||
|
|
||||||
|
That gives you a simple setup for storing everything in that systems'
|
||||||
|
syslog. The logical next step from there is to enable that host a
|
||||||
|
central syslogger. This well documented elsewhere, but simplistically
|
||||||
|
you need to add the following to `/etc/rsyslog.conf`:
|
||||||
|
|
||||||
|
# Provides UDP syslog reception
|
||||||
|
$ModLoad imudp
|
||||||
|
$UDPServerRun 514
|
||||||
|
|
||||||
|
# Provides TCP syslog reception
|
||||||
|
$ModLoad imtcp
|
||||||
|
$InputTCPServerRun 514
|
||||||
|
|
||||||
|
There is a single final step due to the fact that /var/log/messages is
|
||||||
|
only readable by *root*. Normally this is a big faux pas, but I am
|
||||||
|
putting my trust in Jordan Sissel not to have sold his soul to the NSA.
|
||||||
|
To read this (and connect to ports below 1024) Logstash needs to run as
|
||||||
|
*root*. Edit `/etc/sysconfig/logstash` and change the line:
|
||||||
|
|
||||||
|
LS_USER=logstash
|
||||||
|
|
||||||
|
to read:
|
||||||
|
|
||||||
|
LS_USER=root
|
||||||
|
|
||||||
|
Now you can start Logstash and it will pull in `/var/log/messages`:
|
||||||
|
|
||||||
|
service logstash start
|
||||||
|
|
||||||
|
There are loads of configuration options for Logstash, so have a look in
|
||||||
|
the [main documentation](https://logstash.net/docs/1.4.0/) and the
|
||||||
|
[Cookbook](https://cookbook.logstash.net/) for more.
|
||||||
116
content/blog/magicforce-smart-keyboard-review/index.md
Normal file
|
|
@ -0,0 +1,116 @@
|
||||||
|
---
|
||||||
|
date: 2019-04-17
|
||||||
|
title: Magicforce Smart Keyboard Review
|
||||||
|
category: devops
|
||||||
|
featured_image: /images/IMG_20190227_104927822.jpg
|
||||||
|
---
|
||||||
|
|
||||||
|
I've got myself a new toy - a mechanical keyboard. More specifically it is a
|
||||||
|
69-key Magicforce Smart, with Gateron MX Brown switches. I choose for a few
|
||||||
|
reasons:
|
||||||
|
|
||||||
|
- I have colleague with one, so I know it is good.
|
||||||
|
- It was the a good price - I paid about €70
|
||||||
|
- It was one of the few QWERTY UK layout keyboards I found on Amazon France.
|
||||||
|
|
||||||
|
I've fancied a mechanical keyboard for a while, but could never really justify
|
||||||
|
it. For work I always took what I was given as long as it was QWERTY, and for
|
||||||
|
home I did not use it enough to justify spending the money. However, since I
|
||||||
|
work from home for [Oxalide](https://www.oxalide.com) they give me a monthly
|
||||||
|
budget to spend on these things, so I decided to use it.
|
||||||
|
|
||||||
|
The Magicforce is made in China and gets sold under many names I believe.
|
||||||
|
Amazon describe mine as Qisan for what that is worth.
|
||||||
|
|
||||||
|
## What actually is a mechanical keyboard?
|
||||||
|
|
||||||
|
I've blabbered on a bit without explaining what this actually is. Most budget
|
||||||
|
keyboards use what is interchangably called *rubber-dome* or *membrane-switch*,
|
||||||
|
which are inexpensive to build and easy to design. These need a fairly large
|
||||||
|
force to activate and tend to have a slightly "mushy" feel. They also have a
|
||||||
|
limited lifespan - many will not outlive the computer itself.
|
||||||
|
|
||||||
|
By contrast, a mechanical keyboard activates real, physical switches.
|
||||||
|
Underneath each key you have something like this:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
There are a few different types of switch, most by Cherry:
|
||||||
|
|
||||||
|
- Black: Heavyweight feel and obnoxiously loud. The original from 1984 and
|
||||||
|
really only used in POS systems now.
|
||||||
|
- Red: Light feel and fairly quiet and aimed at gamers.
|
||||||
|
- Brown: Faily light, still tactile, but not to loud
|
||||||
|
- Blue: Mid weight, tactile and a loud click - your colleagues will hate you.
|
||||||
|
|
||||||
|
Plus a few more, but those are the major ones.
|
||||||
|
|
||||||
|
## What have I actually bought
|
||||||
|
|
||||||
|
This being a 69 key (or 65%) keyboard it is lacking a few things. There is no
|
||||||
|
numberpad and the Fn keys are hidden behind the, err, `fn` key. What does have
|
||||||
|
though is Gateron MX Browns. These are a copy of the Cherry MX Browns but a bit
|
||||||
|
cheaper. Personally I cannot really feel any difference, so I think it is worth
|
||||||
|
the money saved.
|
||||||
|
|
||||||
|
It is also fully backlit which means you can do this:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
and this:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
and this:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
and more.
|
||||||
|
|
||||||
|
I definitely like the 65% layout. There are some terminal snobs, with much
|
||||||
|
longer beards than mine, who totally shun the mouse. I am not among them,
|
||||||
|
so I do use the mouse. Having no numberpad means that the mouse is close to
|
||||||
|
my hands. I have definitely noticed an improvement in my comfort using the
|
||||||
|
mouse. It also makes it quite compact, so it will happily fit in my back pack
|
||||||
|
alongside my laptop - pretty cool because I like to go to a [co-working](https://eebr.fr/coworking/)
|
||||||
|
from time to time and I can take it with me when I go to Paris.
|
||||||
|
|
||||||
|
There are couple of issues I have with the layout. While I spend most of my
|
||||||
|
time in `vi`, it is certainly not 100%. This means I do use the `home` and
|
||||||
|
`end` keys fairly regularly. Both of these are hidden behind the `fn` key which
|
||||||
|
bugs me a little. Also, the \` is over on the far right; I keep wanting it to
|
||||||
|
be where the `esc` key is - especially as I switch `caps lock` to be `esc`.
|
||||||
|
There is a small amount of instability in the spacebar, but not enough to
|
||||||
|
really trouble me.
|
||||||
|
|
||||||
|
Balanced against this is the fact that is is UK layout. Thus `"` and `@` are
|
||||||
|
in the right place (for me) and I have a proper `enter` key.
|
||||||
|
|
||||||
|
Aesthetically, I think it looks great in white. I have a colleague who bought
|
||||||
|
it in black, and I personally prefer the white. I was expecting it to look cool
|
||||||
|
and retro, but it is more clean and functional. It is definitely white, not
|
||||||
|
the beige of my chldhood/early career.
|
||||||
|
|
||||||
|
Ergo-wise, the feel is excellent. I have tried real Cherry Browns, and I
|
||||||
|
cannot feel the difference with the Gaterons, so I am happy to have saved that
|
||||||
|
money. I do have 1 slight critism though. Because of the extra height of the
|
||||||
|
switches compared to a rubber-dome, you need a wrist rest in my opinion. For
|
||||||
|
now I use a mole-skin note-book. I am thinking I may make myself something out
|
||||||
|
of wood - or perhaps [throw money at the problem](https://www.massdrop.com/buy/npkc-wooden-wrist-rests).
|
||||||
|
|
||||||
|
Another thing I do not like (or perhaps love, I am not sure) is that this has
|
||||||
|
now opened me out to the [wider mechanical keyboards community](https://www.reddit.com/r/MechanicalKeyboards/).
|
||||||
|
Add this to my minor razor obsession, cycling and my wife's photography and I
|
||||||
|
do wonder how we will eat.
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
The Magicforce 69 feels great, albeit not perfect. For the price, I would not
|
||||||
|
expect perfection and it is is genuinely excellent value. It has a really nice
|
||||||
|
touch and feels like it will last a lifetime. To someone who types all day it
|
||||||
|
is worth every penny. The 65% layout may get some getting used to. I am already
|
||||||
|
considering getting a [tenkeyleys](https://www.massdrop.com/buy/keycool-84-2s-mechanical-keyboard)
|
||||||
|
board, as an addition *not* as a replacement.
|
||||||
|
|
||||||
|
Or perhaps [build an ergo](https://www.ergodox.io/)
|
||||||
23
content/blog/my-new-job/index.md
Normal file
|
|
@ -0,0 +1,23 @@
|
||||||
|
---
|
||||||
|
date: 2012-10-01
|
||||||
|
title: My new job
|
||||||
|
category: Opinions
|
||||||
|
---
|
||||||
|
|
||||||
|
I have now got new challenges and am designing much bigger systems.
|
||||||
|
Whereas before I would have take one of these: {% img center
|
||||||
|
/images/p2000-g3-sff.png 250 400 %} Plugged it into a pair of these: {%
|
||||||
|
img center /images/silkworm.jpg 250 450 %} And finally plugged in a pair
|
||||||
|
of these: {% img center /images/dl380g7.jpg 200 400 %}
|
||||||
|
|
||||||
|
Now I do not actually do the plugging in - that is not part of the
|
||||||
|
documented process. Also, the system I am designing is on the other side
|
||||||
|
of the world. However I now take one of these, a couple of these and add
|
||||||
|
a couple of racks of these. Finally it all plugs into a couple of these.
|
||||||
|
|
||||||
|
True I am not as hand-ons as I would like to be (for now). However, I am
|
||||||
|
getting exposed to a the real big boys kit with systems that are used by
|
||||||
|
100k+ users, as opposed to 100 users. The challenge is very real, but
|
||||||
|
exciting. As we quite often said at Snell:
|
||||||
|
|
||||||
|
\"Challenge accepted\...\"
|
||||||
50
content/blog/my-new-life/index.md
Normal file
|
|
@ -0,0 +1,50 @@
|
||||||
|
---
|
||||||
|
date: 2012-10-01
|
||||||
|
title: My new life
|
||||||
|
category: Opinions
|
||||||
|
---
|
||||||
|
|
||||||
|
I am now a month in to life in France. Make no mistake I am so far very
|
||||||
|
happy that we have made the right decision, even though not everything
|
||||||
|
is perfect. The biggest beef is without a doubt the paperwork! For
|
||||||
|
example, it took us a month to get a phone line and the stumbling block
|
||||||
|
was not having the right piece of paper. To get onto the system you have
|
||||||
|
to have a bill, but to get a bill you need a bill. Call it a catch-22 or
|
||||||
|
a chicken-egg take your pick, but french beaurocrats love that.
|
||||||
|
|
||||||
|
Working in France is a little different to England. Add to that the fact
|
||||||
|
that I am going from a small company to working on a project for a much
|
||||||
|
larger one and you have quite a culture shock.
|
||||||
|
|
||||||
|
The attitude to lunch is probably the biggest single
|
||||||
|
change of all that can only be attributed to country. All my
|
||||||
|
colleagues take a 2 hour lunch religiously, during which they go
|
||||||
|
elsewhere. I am used to taking a 30 minute break to read the Register
|
||||||
|
with a sandwhich/salad at my desk. For now, past an hour, I get bored an
|
||||||
|
return to work. Maybe I will extend my lunch as I get used to it, but
|
||||||
|
maybe not - shorter lunch means I get to go home earlier.
|
||||||
|
|
||||||
|
|
||||||
|
# Commuting
|
||||||
|
|
||||||
|
My commute is quite a lot further than when I was at Snell:
|
||||||
|
|
||||||
|
<iframe width="500" height="300" scrolling="no" frameborder="no" src="https://www.google.com/fusiontables/embedviz?viz=MAP&q=select+col2+from+1J0AXs2Oyzs-J9ChL5U7hgKWkHX-HimQZ699VSO4&h=false&lat=50.820603567709554&lng=-1.011776909545925&z=13&t=1&l=col2"></iframe>
|
||||||
|
That was quite a nice route once you got to Langston harbour. What I do
|
||||||
|
now is very different. For a start I have not cycled all the way yet.
|
||||||
|
Partly because it it a lot further, but also because trains are a *lot*
|
||||||
|
cheaper here. I pay 80 euros for a month, half of which gets
|
||||||
|
re-imbursed. When your train costs less than 2 euros a day, it does not
|
||||||
|
even make sense to take a car.
|
||||||
|
|
||||||
|
The actual cycling is a lot more pleasant as well. I live in a hamlet,
|
||||||
|
and my route take me past the *le lac tranquille* (the calm lake). In
|
||||||
|
the morning it gets very cold and misty, which is very nice.
|
||||||
|
|
||||||
|
Drivers are about the same. The vast majority give me plenty of space,
|
||||||
|
but obviously you get the odd idiot. Just today someone shouted "Je
|
||||||
|
vais te touer" so some things are pretty universal it would appear.
|
||||||
|
|
||||||
|
I have also found that the paint on the roads (at least in Rennes) is
|
||||||
|
more slippery in the wet. The simple answer has been to avoid the cycle
|
||||||
|
lanes - no real change there then.
|
||||||
41
content/blog/my-openstack-clients-stopped-working/index.md
Normal file
|
|
@ -0,0 +1,41 @@
|
||||||
|
---
|
||||||
|
date: 2015-09-09
|
||||||
|
title: My Openstack clients stopped working
|
||||||
|
category: devops
|
||||||
|
Summary: My Openstack CLI clients stopped working, this is how I fixed them
|
||||||
|
---
|
||||||
|
|
||||||
|
A quicky, possibly note to self. The other day I ran `nova list` and
|
||||||
|
instead of getting a list of the instances in my lab I got:
|
||||||
|
|
||||||
|
Traceback (most recent call last):
|
||||||
|
File "/usr/bin/nova", line 6, in <module>
|
||||||
|
from novaclient.shell import main
|
||||||
|
File "/usr/lib/python2.7/site-packages/novaclient/shell.py", line 33, in <module>
|
||||||
|
from oslo.utils import strutils
|
||||||
|
File "/usr/lib/python2.7/site-packages/oslo/utils/strutils.py", line 26, in <module>
|
||||||
|
from oslo.utils._i18n import _
|
||||||
|
File "/usr/lib/python2.7/site-packages/oslo/utils/_i18n.py", line 21, in <module>
|
||||||
|
from oslo import i18n
|
||||||
|
File "/usr/lib/python2.7/site-packages/oslo/i18n/__init__.py", line 13, in <module>
|
||||||
|
from ._factory import *
|
||||||
|
File "/usr/lib/python2.7/site-packages/oslo/i18n/_factory.py", line 26, in <module>
|
||||||
|
from oslo.i18n import _message
|
||||||
|
File "/usr/lib/python2.7/site-packages/oslo/i18n/_message.py", line 30, in <module>
|
||||||
|
class Message(six.text_type):
|
||||||
|
File "/usr/lib/python2.7/site-packages/oslo/i18n/_message.py", line 159, in Message
|
||||||
|
if six.PY2:
|
||||||
|
AttributeError: 'module' object has no attribute 'PY2'
|
||||||
|
|
||||||
|
A bit of DDGing did not reveal anyone else having this problem. A few
|
||||||
|
Python developers had come accross it, but the fixes were not really
|
||||||
|
relevant to me. The fix is quite simple though. Basically the Python
|
||||||
|
[Six](https://pypi.python.org/pypi/six) module got corrupted somehow.
|
||||||
|
|
||||||
|
I am using Fedora 22, and which uses DNF as its package manager. This
|
||||||
|
depends on Six, so I had to do a reinstall of the module:
|
||||||
|
|
||||||
|
sudo dnf reinstall python-six
|
||||||
|
|
||||||
|
Fixed! I have no idea what caused it to break as I do not really pay
|
||||||
|
much attention on what is a fairly disposably workstation.
|
||||||
189
content/blog/my-pythony-puppet-ruby-ide/index.md
Normal file
|
|
@ -0,0 +1,189 @@
|
||||||
|
---
|
||||||
|
date: 2014-09-13
|
||||||
|
title: My Pythony Puppet Ruby vim IDE
|
||||||
|
category: devops
|
||||||
|
featured_image: https://i.imgur.com/0k24Ambl.png
|
||||||
|
---
|
||||||
|
|
||||||
|
Despite my penchant for tools written in Ruby (Puppet, Gitlab,
|
||||||
|
Jekyll/Octopress etc) I do not actually like Ruby. I am more of a Python
|
||||||
|
guy. I also like Vim, so whenever I use a GUI IDE I end up with
|
||||||
|
something littered with `:w` and `ZZ`.
|
||||||
|
|
||||||
|
Despite my pythonic leanings, I also need something that can handle Ruby
|
||||||
|
and Puppet's DSL. To which end, this is a bit of a mixture.
|
||||||
|
Fortunately, nothing in either world really contradicts the other, so it
|
||||||
|
works pretty nicely.
|
||||||
|
|
||||||
|
First, the basic environments. Git is needed everywhere, plus I need to
|
||||||
|
isolate the environments of the various projects.
|
||||||
|
|
||||||
|
sudo apt install git python python-dev python-virtualenv \
|
||||||
|
virtualenvwrapper curl libxml2-dev libxslt-dev zlib1g-dev ruby-dev
|
||||||
|
echo "pip install pyflakes" >> ~/.virtualenvs/postmkvirtualenv
|
||||||
|
curl -sSL https://get.rvm.io | bash -s stable --ruby
|
||||||
|
|
||||||
|
Now we have Git, Virtualenv (and virtualenvwrapper) and RVM installed.
|
||||||
|
|
||||||
|
Vim
|
||||||
|
---
|
||||||
|
|
||||||
|
This the core of everything. I use quite a few plugins:
|
||||||
|
|
||||||
|
- [Autoclose](https://github.com/andrewle/vim-autoclose): Inserts
|
||||||
|
matching bracket, paren, brace or quote
|
||||||
|
- [Colour Sampler
|
||||||
|
Pack](https://github.com/vim-scripts/Colour-Sampler-Pack): Gives me
|
||||||
|
a nice colour scheme
|
||||||
|
- [Gundo](https://github.com/sjl/gundo.vim): Visualise the undo tree
|
||||||
|
- [Lusty](https://github.com/sjbach/lusty): Manage files within Vim
|
||||||
|
- [PEP-8](https://github.com/cburroughs/pep8): Validate the style of
|
||||||
|
Python files
|
||||||
|
- [PyDoc](https://github.com/vim-scripts/pydoc.vim): Python
|
||||||
|
documentation view- and search-tool (uses pydoc)
|
||||||
|
- [Pathogen](https://github.com/tpope/vim-pathogen): Plugin Manager
|
||||||
|
- [Scroll Colours](https://github.com/vim-scripts/ScrollColors):
|
||||||
|
Colorsheme Scroller, Chooser, and Browser
|
||||||
|
- [Supertab](https://github.com/ervandew/supertab): Tab completion
|
||||||
|
- [VirtualEnv](https://github.com/jmcantrell/vim-virtualenv): Works
|
||||||
|
with Virtualenvs
|
||||||
|
- [Vim Puppet](https://github.com/rodjek/vim-puppet): Puppet niceties
|
||||||
|
- [Tabular](https://github.com/godlygeek/tabular): Text filtering and
|
||||||
|
alignment
|
||||||
|
- [Markdown](https://github.com/hallison/vim-markdown): Markdown
|
||||||
|
syntax highlighter with snippets support
|
||||||
|
|
||||||
|
I keep all this under Git control (available
|
||||||
|
[here](https://gitlab.chriscowley.me.uk/chriscowleyunix/vim-configuration)).
|
||||||
|
You can just clone my repo and create a symlink for your `.vimrc`. If
|
||||||
|
you would rather see what you are doing, then you can replicate my set
|
||||||
|
up like this:
|
||||||
|
|
||||||
|
mkdir -p ${HOME}/.vim/{autoload,bundle}
|
||||||
|
cd ${HOME}/.vim/
|
||||||
|
git init
|
||||||
|
git submodule add https://github.com/andrewle/vim-autoclose.git bundle/vim-autoclose
|
||||||
|
git submodule add https://github.com/vim-scripts/Colour-Sampler-Pack.git bundle/colour-sampler-pack
|
||||||
|
git submodule add https://github.com/sjl/gundo.vim.git bundle/gundo
|
||||||
|
git submodule add https://github.com/sjbach/lusty.git bundle/lusty
|
||||||
|
git submodule add https://github.com/cburroughs/pep8.git bundle/pep8
|
||||||
|
git submodule add https://github.com/vim-scripts/pydoc.vim.git bundle/pydoc
|
||||||
|
git submodule add https://github.com/tpope/vim-pathogen.git bundle/pathogen
|
||||||
|
git submodule add https://github.com/vim-scripts/ScrollColors.git bundle/scrollColors
|
||||||
|
git submodule add https://github.com/ervandew/supertab.git bundle/supertab
|
||||||
|
git submodule add https://github.com/jmcantrell/vim-virtualenv.git bundle/vim-virtualenv
|
||||||
|
git submodule add https://github.com/rodjek/vim-puppet.git bundle/puppet
|
||||||
|
git submodule add https://github.com/godlygeek/tabular.git bundle/tabular
|
||||||
|
git submodule add https://github.com/hallison/vim-markdown.git bundle/markdown
|
||||||
|
git submodule init
|
||||||
|
git submodule update
|
||||||
|
git submodule foreach git submodule init
|
||||||
|
git submodule foreach git submodule update
|
||||||
|
ln -s ../bundle/pathogen/autoload/pathogen.vim autoload/pathogen.vim
|
||||||
|
mv $HOME/.vimrc .
|
||||||
|
ln -s '$HOME/.vim/.vimrc' $HOME/.vimrc
|
||||||
|
|
||||||
|
Add the following to your `.vimrc`:
|
||||||
|
|
||||||
|
" pathogen
|
||||||
|
let g:pathogen_disabled = [ 'pathogen' ] " don't load self
|
||||||
|
call pathogen#infect() " load everyhting else
|
||||||
|
call pathogen#helptags() " load plugin help files
|
||||||
|
|
||||||
|
" code folding
|
||||||
|
set foldmethod=indent
|
||||||
|
set foldlevel=2
|
||||||
|
set foldnestmax=4
|
||||||
|
|
||||||
|
" indentation
|
||||||
|
set autoindent
|
||||||
|
set softtabstop=4 shiftwidth=4 expandtab
|
||||||
|
|
||||||
|
" visual
|
||||||
|
highlight Normal ctermbg=black
|
||||||
|
set background=dark
|
||||||
|
set cursorline
|
||||||
|
set t_Co=256
|
||||||
|
|
||||||
|
" syntax highlighting
|
||||||
|
syntax on
|
||||||
|
filetype on " enables filetype detection
|
||||||
|
filetype plugin indent on " enables filetype specific plugins
|
||||||
|
|
||||||
|
" colorpack
|
||||||
|
colorscheme vibrantink
|
||||||
|
|
||||||
|
" gundo
|
||||||
|
nnoremap <F5> :GundoToggle<CR>
|
||||||
|
|
||||||
|
" lusty
|
||||||
|
set hidden
|
||||||
|
let g:LustyJugglerSuppressRubyWarning = 1"
|
||||||
|
|
||||||
|
" pep8
|
||||||
|
let g:pep8_map='<leader>8'
|
||||||
|
|
||||||
|
" supertab
|
||||||
|
au FileType python set omnifunc=pythoncomplete#Complete
|
||||||
|
let g:SuperTabDefaultCompletionType = "context"
|
||||||
|
set completeopt=menuone,longest,preview
|
||||||
|
|
||||||
|
There's quite a lot going on there. Refer to the various plugin docs
|
||||||
|
linked above to find what it all does. This would be a good moment to
|
||||||
|
commit all that.
|
||||||
|
|
||||||
|
git add .
|
||||||
|
git commit -m "Initial commit"
|
||||||
|
|
||||||
|
Tmux
|
||||||
|
----
|
||||||
|
|
||||||
|
I use this so I can have a single console window, with multiple panes.
|
||||||
|
Tmux is configured with the file `$HOME/.tmux.conf`, mine contains:
|
||||||
|
|
||||||
|
set-window-option -g mode-keys vi
|
||||||
|
bind h select-pane -L
|
||||||
|
bind j select-pane -D
|
||||||
|
bind k select-pane -U
|
||||||
|
bind l select-pane -R
|
||||||
|
unbind -n C-b
|
||||||
|
set -g prefix C-a
|
||||||
|
|
||||||
|
# easy-to-remember split pane commands
|
||||||
|
bind h split-window -h
|
||||||
|
bind v split-window -v
|
||||||
|
unbind '"'
|
||||||
|
unbind %
|
||||||
|
|
||||||
|
bind -n M-Left select-pane -L
|
||||||
|
bind -n M-Right select-pane -R
|
||||||
|
bind -n M-Up select-pane -U
|
||||||
|
bind -n M-Down select-pane -D
|
||||||
|
set-window-option -g window-status-current-bg yellow
|
||||||
|
|
||||||
|
# Just click it
|
||||||
|
set-option -g mouse-select-pane on
|
||||||
|
set-option -g mouse-select-window on
|
||||||
|
set-option -g mouse-resize-pane on
|
||||||
|
|
||||||
|
# Scroll your way into copy mode (scrollback buffer)
|
||||||
|
# and select text for copying with the mouse
|
||||||
|
setw -g mode-mouse on
|
||||||
|
|
||||||
|
set -g set-titles on
|
||||||
|
set -g set-titles-string "#T"
|
||||||
|
|
||||||
|
Now I can use `Ctrl+a` instead of `Ctrl+b`. You may not need to do this,
|
||||||
|
but I have little hands.I also change the kes for splitting my windows
|
||||||
|
(*'h'* horizontally, *v* vertically). I make a few changes from the
|
||||||
|
defaults:
|
||||||
|
|
||||||
|
- `Ctrl+a` instead of `Ctrl+b` is my prefix. This matches `screen`,
|
||||||
|
plusI am more comfortable as I have small hands.
|
||||||
|
- I can move around panes with either `vi` keys, arrows or just with
|
||||||
|
the mouse.
|
||||||
|
- I change the keys to split windows to `h` (horizontal) and `v`
|
||||||
|
(vertical).
|
||||||
|
|
||||||
|
This all works pretty well for me, although not perfectly. At the moment
|
||||||
|
my clipboard gets intercepted by Tmux,which is top of my my list to fix.
|
||||||
78
content/blog/new-linux-active-directory-integration/index.md
Normal file
|
|
@ -0,0 +1,78 @@
|
||||||
|
---
|
||||||
|
date: 2014-06-17
|
||||||
|
title: New Linux Active Directory Integration
|
||||||
|
category: devops
|
||||||
|
---
|
||||||
|
|
||||||
|
This used to be quite complex, but now is astoundingly simple. Now there
|
||||||
|
is a new project call
|
||||||
|
[realmd](https://freedesktop.org/software/realmd/). It is in recent
|
||||||
|
version of Debian (Jessie and Sid) and Ubuntu (since 13.04). For Red Hat
|
||||||
|
types, it is RHEL7 and Fedora (since 18).
|
||||||
|
|
||||||
|
If you\'re on Debian/Ubuntu, install with:
|
||||||
|
|
||||||
|
apt-get install realmd
|
||||||
|
|
||||||
|
For RHEL/Fedora:
|
||||||
|
|
||||||
|
sudo yum install realmd
|
||||||
|
|
||||||
|
Now you can go ahead and join the domain:
|
||||||
|
|
||||||
|
sudo realm join --user=<admin-user> example.com
|
||||||
|
|
||||||
|
That is it, you can check this by running `sudo realm list`, which will
|
||||||
|
give you something like:
|
||||||
|
|
||||||
|
example.com
|
||||||
|
type: kerberos
|
||||||
|
realm-name: EXAMPLE.COM
|
||||||
|
domain-name: example.com
|
||||||
|
configured: kerberos-member
|
||||||
|
server-software: active-directory
|
||||||
|
client-software: sssd
|
||||||
|
required-package: oddjob
|
||||||
|
required-package: oddjob-mkhomedir
|
||||||
|
required-package: sssd
|
||||||
|
required-package: adcli
|
||||||
|
required-package: samba-common
|
||||||
|
login-formats: %U@example.com
|
||||||
|
login-policy: allow-realm-logins
|
||||||
|
|
||||||
|
The last step is `sudo`. If you want to have everyone in *Domain Admins*
|
||||||
|
have permission to run everything as root, then add the following to
|
||||||
|
`sudoers`:
|
||||||
|
|
||||||
|
%domain\ admins@example.com ALL=(ALL) ALL
|
||||||
|
|
||||||
|
By default `realmd` used SSSD to perform the authentication. This in
|
||||||
|
turn configures Kerberos and LDAP.
|
||||||
|
|
||||||
|
My initial testing has been performed with an Active Directory that has
|
||||||
|
"Identity Managment for UNIX" installed. However, I forgot to actually
|
||||||
|
enable my user for UNIX. Even so, it worked perfectly. It sees my
|
||||||
|
Windows groups and defines a home directory of
|
||||||
|
`/home/example.com/<username>`. I am pretty certain that you do not need
|
||||||
|
to extend AD, it should work out of the box from what I can see.
|
||||||
|
|
||||||
|
As a bonus, it seems to respect nested groups, something that has always
|
||||||
|
been a bug bear in these things.
|
||||||
|
|
||||||
|
# Edit (18/6/2014)
|
||||||
|
|
||||||
|
It has been bought to my attention that there is dependency problems in
|
||||||
|
Ubuntu 14.04. The [work
|
||||||
|
around](https://funwithlinux.net/2014/04/join-ubuntu-14-04-to-active-directory-domain-using-realmd)
|
||||||
|
is to not let `realm` install the dependencies. To `/etc/realmd.conf`
|
||||||
|
add:
|
||||||
|
|
||||||
|
[service]
|
||||||
|
automatic-install = no
|
||||||
|
|
||||||
|
Now you need to install the necessary packages yourself:
|
||||||
|
|
||||||
|
sudo apt install samba-common-bin, samba-libs sssd-tools krb5-user adcli
|
||||||
|
|
||||||
|
You will need to enter your kerberos domain (e.g. EXAMPLE.COM) during
|
||||||
|
the install. You should be able to get a ticket and join the domain.
|
||||||
88
content/blog/nfs-with-puppet-and-an-enc/index.md
Normal file
|
|
@ -0,0 +1,88 @@
|
||||||
|
---
|
||||||
|
date: 2014-01-24
|
||||||
|
TItle: NFS with Puppet and an ENC
|
||||||
|
category: devops
|
||||||
|
Thumbnails: https://puppetlabs.com/sites/default/files/PL_logo_horizontal_RGB_0.svg
|
||||||
|
---
|
||||||
|
|
||||||
|
Ages ago (it seems) I posted a
|
||||||
|
[howto](https://www.chriscowley.me.uk/blog/2013/04/11/using-hiera-with-puppet/)
|
||||||
|
on configure NFS using Puppet and Hiera. I have been using this happily
|
||||||
|
for several months and adding a new share was is as simple as adding a
|
||||||
|
line to a YAML file. I was never completely happy with it though,
|
||||||
|
especially after I decided to deploy [The
|
||||||
|
Foreman](https://www.theforeman.org) in my lab.
|
||||||
|
|
||||||
|
The reason I was never satisfied is because The Foreman makes a really
|
||||||
|
good ENC. I wanted to use this, so I have modified my module to use an
|
||||||
|
ENC rather than Hiera directly.
|
||||||
|
|
||||||
|
OK, first I we need to get the module into a position where it uses
|
||||||
|
parameterized classes. This is actually quite simple.
|
||||||
|
|
||||||
|
My original manifest is
|
||||||
|
[here](https://github.com/chriscowley/chriscowley-nfs/blob/b5d5fe6eba75379fad37255ceddb55208cbe7208/manifests/server.pp).
|
||||||
|
The key item is the *\$exports* variable, which is hiera data. All I did
|
||||||
|
was create a class parameter called *exports* and removed the variable
|
||||||
|
within the class. You can see the new code
|
||||||
|
[here](https://github.com/chriscowley/chriscowley-nfs/blob/ab9627cf920f3a87986aa7379168572ca3a55f7e/manifests/server.pp).
|
||||||
|
I have also moved the `list_exports` function out into a [seperate
|
||||||
|
file](https://github.com/chriscowley/chriscowley-nfs/blob/ab9627cf920f3a87986aa7379168572ca3a55f7e/manifests/list_exports.pp).
|
||||||
|
Apparently this makes it more readable, although I am not convinced in
|
||||||
|
this instance.
|
||||||
|
|
||||||
|
I also took the chance to update my module a bit so that it was not
|
||||||
|
hard-coded to my own lab network. To that end, it will automatically
|
||||||
|
pull out the IP address and netmask of eth0. You can edit this easily
|
||||||
|
enough using your ENC.
|
||||||
|
|
||||||
|
`manifests/server.pp class nfs::server ( $exports = [ '/srv/share'], $networkallowed = $::network_eth0, $netmaskallowed = $::netmask_eth0, ) { // Code here }`
|
||||||
|
|
||||||
|
Next we need a simple ENC to supply the data. An ENC is actually just
|
||||||
|
any script that returns YAML. It has a single parameter, which is the
|
||||||
|
FQDN of the node. I use this:
|
||||||
|
|
||||||
|
#!/bin/bash
|
||||||
|
DATADIR="/var/local/enc"
|
||||||
|
NODE=$1
|
||||||
|
|
||||||
|
cat "${DATADIR}/${NODE}.yaml"
|
||||||
|
|
||||||
|
Next you need a YAML file that looks like:
|
||||||
|
|
||||||
|
---
|
||||||
|
environment: production
|
||||||
|
classes:
|
||||||
|
nfs::server:
|
||||||
|
exports:
|
||||||
|
- /srv/share1
|
||||||
|
- /srv/share3
|
||||||
|
networkallowed: 192.168.0.0
|
||||||
|
netmaskallowed: 255.255.255.0
|
||||||
|
parameters:
|
||||||
|
|
||||||
|
Finally, you need to enable this on your Puppet master. Add this to
|
||||||
|
`/etc/puppet/puppet.conf`:
|
||||||
|
|
||||||
|
[master]
|
||||||
|
node_terminus = exec
|
||||||
|
external_nodes = /usr/local/bin/simple-enc.sh
|
||||||
|
|
||||||
|
Now whenever a node with the FQDN nfs.example.lan syncs with the master
|
||||||
|
it runs `/usr/local/bin/simple-enc.sh nfs.examle.lan.yaml`. This returns
|
||||||
|
the contents of the YAML file above. The layout of it is pretty logical,
|
||||||
|
but I suggest reading Puppetlabs
|
||||||
|
[docs](https://docs.puppetlabs.com/guides/external_nodes.html).
|
||||||
|
|
||||||
|
How is this better than the previous Hiera setup? First I can now use my
|
||||||
|
module with The Foreman which answers my immediate need. Second I can
|
||||||
|
now submit this module to the Forge with a warm fuzzy feeling inside as
|
||||||
|
I am a good citizen. not only does it work with Puppet 3, but also
|
||||||
|
really old versions of Puppet that do not support an ENC or Hiera. It
|
||||||
|
can do this because the user can still edit the class parameters
|
||||||
|
directly, or set the in `site.pp` (**DON\'T DO THAT**).
|
||||||
|
|
||||||
|
You can install the module on your own Puppet master with:
|
||||||
|
|
||||||
|
git clone https://gitlab.chriscowley.me.uk/puppet/chriscowley-nfs.git \
|
||||||
|
/etc/puppet/modules/nfs/
|
||||||
40
content/blog/open-source-and-cycling/index.md
Normal file
|
|
@ -0,0 +1,40 @@
|
||||||
|
---
|
||||||
|
date: 2016-05-29
|
||||||
|
title: Open Source and Cycling
|
||||||
|
category: cycling
|
||||||
|
---
|
||||||
|
|
||||||
|
|
||||||
|
I love both Open Source and Cycling, but the 2 do not ofen meet. In fact the cycling industry is incredibly secretive and dominated by patents. It is one of the major reasons that it is very hard to enter the groupset market (for roadies there are 3 major brands, for MTBers only 2). SRAM recently completely changed the way derailleur shifting worked with their new eTap electronic groupset, basically to work around Shimano's patent library. I haven't tried it, but by all accounts it is excellent (for the price it should be), but still it is a little silly.
|
||||||
|
|
||||||
|
Also, the GPS market is really dominated by Garmin, for the simple reason that that they make an excellent product. Many people record their rides on a Garmin, then upload it to Strava - also closed source.
|
||||||
|
|
||||||
|
The FLOSS world has been quite slow on the uptake with all this. There is [Golden Cheetah](http://www.goldencheetah.org), but that is a desktop program that uses QT. That is fine for those that use KDE, but for anyone that uses a GTK based DE then it sets the OCD twitching (maybe that is just me). Also, it is tied to a single machine. I like to upload my rides both at work and at home, so a web-based solution is ideal. There was [Openfit-API](https://groups.drupal.org/node/217829), but that is now dead - the name has even been taken by some US government initiative.
|
||||||
|
|
||||||
|
The next problem is the GPS devices themselves. These devices, but their very definition, track you everywhere you go. In many cases they are also cloud-enabled, so are broadcasting your position too. I am not saying for a minute that Garmin, Mio, Strava et al are selling constant updates of our position to taxi companies so they can run us over, but the fact is we have no idea what they are doing in reality. In fact, Runkeeper have been caught doing [nefarious things](http://arstechnica.co.uk/tech-policy/2016/05/runkeeper-fitnesskeeper-breaches-data-protection-law-norway/).
|
||||||
|
|
||||||
|
The fact is that Strava and co offer an excellent service - [I myself use it regularly](https://www.strava.com/athletes/1988717). Even the free tier is plenty good enough for the keen (or even competetive) cyclist. One has to remember though why they are able to offer such a service for free - the product is you and me.
|
||||||
|
|
||||||
|
So what solutions are there? At the moment none really. An open source GPS does not exist. I have found [one open source sports tracker](https://github.com/jonasoreland/runnerup/) for Android, but so far have found it a bit underwhelming. It certainly does not offer any self-hosted analysis, which is why one would want to record the rides in the first place. I am hopeful that is could work though - maybe I will insist with it.
|
||||||
|
|
||||||
|
What is missing is a web-based analysis tool that I can host myself. I have a project on the backburner to fill this hole. Its working title is Ryder, which I admit is a crap name so any suggestions would be welcome. Currently I am ashamed to put it in the public eye, but watch this space...
|
||||||
|
|
||||||
|
The next thing missing is a device for recording the rides. Why not use a phone? Well GPS hits the battery hard. I have on a couple of occassions been a few hours in a ride that I am recording on my phone. I have had a problem and have needed to call my wife for help or just tell her I'm going to be late, only to find that the battery is dead. Also, I do not like having my phone on my handlebars, so I cannot see what it happening.
|
||||||
|
|
||||||
|
What is needed is a truly open source device that can:
|
||||||
|
|
||||||
|
- Collect and store my position from GPS
|
||||||
|
- Display basic data on a screen
|
||||||
|
- Survive a torrential downpour
|
||||||
|
- At the end send the collected data somewhere
|
||||||
|
|
||||||
|
A few years ago, this would have been a challenge. Nowadays, thanks to the Raspberry Pi the choices are plenty. In fact, I have been looking at [Olimex](https://www.olimex.com) who seem to do everything that I need.
|
||||||
|
|
||||||
|
- [Allwinner A20 based board](https://www.olimex.com/Products/OLinuXino/A20/A20-OLinuXino-MICRO-4GB/open-source-hardware)
|
||||||
|
- [GPS module](https://www.olimex.com/Products/Modules/GPS/MOD-GPS/)
|
||||||
|
- [Bluetooth](https://www.olimex.com/Products/USB-Modules/USB-BT4/)
|
||||||
|
- [Really small, low power screen](https://www.olimex.com/Products/Modules/LCD/MOD-OLED-128x64/open-source-hardware)
|
||||||
|
|
||||||
|
All those parts are completely open source. In theory they could be used to build a complete GPS that can track your rides, then send them to whatever you want over Bluetooth.
|
||||||
|
|
||||||
|
Am I going to take this on? Perhaps, although right now I do not have time, but maybe ... I hope so at least.
|
||||||
200
content/blog/open-source-hyper-converged-infrastructure/index.md
Normal file
|
|
@ -0,0 +1,200 @@
|
||||||
|
---
|
||||||
|
date: 2014-09-19
|
||||||
|
title: Open Source Hyper-converged Infrastructure
|
||||||
|
category: devops
|
||||||
|
---
|
||||||
|
|
||||||
|
Hyper-converged seems to be all the rage at the moment. VMware\'s
|
||||||
|
announcement of the [EVO:RAIL](https://www.vmware.com/products/evorail/)
|
||||||
|
has naturally got lots of tongues wagging. They are jumping into a
|
||||||
|
market already well populated.
|
||||||
|
|
||||||
|
I was looking at the pricing/features and though it all looks a little
|
||||||
|
expensive. Nutanix for example, will sell you the following:
|
||||||
|
|
||||||
|
- NX-1000: \$80k+ (4 little nodes)
|
||||||
|
- NX-3000: \$144k+ (4 big nodes)
|
||||||
|
- NX-6000: \$120k+ (2 massive nodes)
|
||||||
|
|
||||||
|
I'd imagine that, once you include licensing, EVO:RAIL systems will
|
||||||
|
come in similar. What do you get for your case:
|
||||||
|
|
||||||
|
- A COTS server (dual E5-26x0 Xeon, 64GB+ RAM)
|
||||||
|
- Networking (at least 2x 1Gb, but most are 10Gb)
|
||||||
|
- A few TB Storage
|
||||||
|
- Tend to rely on the customer to supply the network infrastructure,
|
||||||
|
but I see no real problem with that. If I had all HP Procurves in my
|
||||||
|
DC, I would pretty annoyed if I suddenly had a pair of Cisco\'s to
|
||||||
|
worry about
|
||||||
|
- The while system is built on top of architectually identical
|
||||||
|
building blocks
|
||||||
|
|
||||||
|
That last one does not necessarily mean that all the boxes are the same.
|
||||||
|
It means there is no concept of a \"storage node\" or a \"compute
|
||||||
|
node\". You just have \"nodes\" that all contain compute, storage,
|
||||||
|
networking, whatever. You may have some that are bigger than others, but
|
||||||
|
they all do the same job.
|
||||||
|
|
||||||
|
On top of that, you get some software special sauce to tie it all
|
||||||
|
together. For EVO::RAIL, that looks something like this:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
and this:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
[Which is nice](https://youtu.be/XOhZgAPn_CU)
|
||||||
|
|
||||||
|
I decided to play a little game, a bit like when you want to buy a new
|
||||||
|
computer: you go online, put together all the parts you want in a
|
||||||
|
basket, look at, dream a little. After a few rounds of this you start
|
||||||
|
justifying it to yourself, then you wife/accountant. Eventually, you
|
||||||
|
build one final basket pull out the credit card an pull the trigger.
|
||||||
|
Well, this is like that, but more expensive.
|
||||||
|
|
||||||
|
I think that we now have everything we need in the FLOSS world to
|
||||||
|
impliment a Hyper-converged architecture. I suppose this is my attempt
|
||||||
|
to document that as a some sort of reference architecture. A key
|
||||||
|
component will be Openstack, but not necessarily everywhere.
|
||||||
|
|
||||||
|
# Hardware
|
||||||
|
|
||||||
|
<img class='image-process-article-image' src='images/SYS-2027PR-HTR_25.jpg' />
|
||||||
|
|
||||||
|
The easy bit is the CPU and RAM: plenty (at least 6 cores with 64GB of
|
||||||
|
RAM). Networking, surprisingly is also relatively simple. Anything will
|
||||||
|
do (2x 1Gb will be fine an entry level node), but 2x 10Gb is preferable,
|
||||||
|
Infiniband would also be great (Linux works beautifully with
|
||||||
|
Infiniband). All this would (ideally) be put into a box that has
|
||||||
|
[multiple nodes in one
|
||||||
|
box](https://www.supermicro.com.tw/products/system/2U/2028/SYS-2028TP-HTR.cfm).
|
||||||
|
|
||||||
|
Storage is more complex. Tiering is essential, and I personally am not a
|
||||||
|
fan of hardware RAID. Additionally, this needs to be replicated. The
|
||||||
|
overall architecture would look something like:
|
||||||
|
|
||||||
|
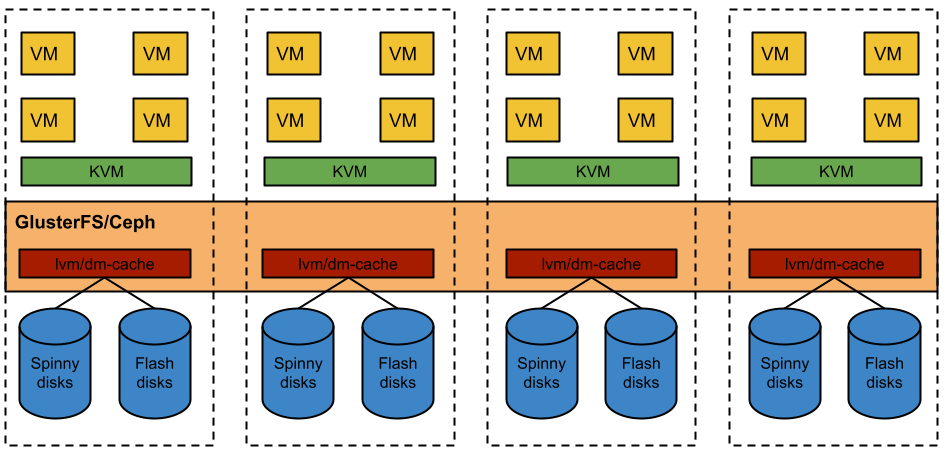
|
||||||
|
|
||||||
|
Each node would have to at least an SSD, plus a decent number of spinny
|
||||||
|
disks to get a sensible capacity. The spinners have no need for RAID
|
||||||
|
-data protection is done on a cluster level higher up the stack. I think
|
||||||
|
right now, I would probably run with Gluster, for reasons which I will
|
||||||
|
revisit later. Ceph is probably where is till be at in the future
|
||||||
|
though.
|
||||||
|
|
||||||
|
A good rule of thumb when using tiering is that your SSD should be
|
||||||
|
roughly 10% of your spinning rust. So lets say a single 400-500GB SSD,
|
||||||
|
along side 5TB of spinning disk.
|
||||||
|
|
||||||
|
For the clustering, you would need at least 2x 1Gb NICs dedicated to
|
||||||
|
this. If one could dedicate a pair of 10Gb NICs then that would be
|
||||||
|
awesome.
|
||||||
|
|
||||||
|
Finally, the OS needs to be installed on something, but a USB key or SD
|
||||||
|
card is more than sufficient for that.
|
||||||
|
|
||||||
|
The complex bit is the initial configuration. What really makes the
|
||||||
|
likes of Nutanix and EVO:RAIL stand out is the simplicity of install.
|
||||||
|
The images above our the 4 steps it takes to get an EVO:RAIL cluster
|
||||||
|
running and I have to admit it pretty darn good.
|
||||||
|
|
||||||
|
# Software
|
||||||
|
|
||||||
|
What we need to aim at is that you:
|
||||||
|
|
||||||
|
1. download an image
|
||||||
|
2. burn on to USB keys/SD cards
|
||||||
|
3. boot all the nodes
|
||||||
|
4. it works!
|
||||||
|
|
||||||
|
I think all the parts to auto-configure a cluster exist in the FOSS
|
||||||
|
world. The problem is making it 100% plug and play. I would say that
|
||||||
|
this is finally a genuine use for IPv6 and mDNS. Let\'s dedicate a pair
|
||||||
|
of 1Gb/s NICs to cluster communications and do all that over IPv6.
|
||||||
|
|
||||||
|
This enables to get a fully working network going with no intervention
|
||||||
|
from the user. Now we can have a Config Management system running over
|
||||||
|
said network. If we use Puppet, then our secret sauce can be used as an
|
||||||
|
ENC to configure all the nodes.
|
||||||
|
|
||||||
|
What this means is that amount of new code that needs to be written is
|
||||||
|
relatively small. All we need is that initial configuration utility. To
|
||||||
|
make it super simple, this could even be in \"the cloud\" and each
|
||||||
|
cluster registers itself with a UUID. I suppose this would work in much
|
||||||
|
the same way as `etcd`. I suppose this interface could also be where the
|
||||||
|
user downloads their image files, thus the UUID could be part of said
|
||||||
|
image. Make all that FLOSS, and people can host their own management
|
||||||
|
portal if they prefer. It would function in much the same way as
|
||||||
|
RHN/Satellite.
|
||||||
|
|
||||||
|
Anyway, once that is all done, Puppet can then go and do all the
|
||||||
|
necessary configuration. There is quite a bit of integration that needs
|
||||||
|
to happen here.
|
||||||
|
|
||||||
|
There are 2 obvious choices for the virtualisation layer:
|
||||||
|
|
||||||
|
- oVirt
|
||||||
|
- Openstack
|
||||||
|
|
||||||
|
These are necessarily mutually exclusive. The oVirt team are build in
|
||||||
|
support for various Openstack technologies:
|
||||||
|
|
||||||
|
- Neutron for networking
|
||||||
|
- Cinder for block storage
|
||||||
|
- Glance for template storage
|
||||||
|
|
||||||
|
Different hosts could be tagged as either oVirt or Nova nodes depending
|
||||||
|
on the type of app they are running. They all then share the same pool
|
||||||
|
of storage.
|
||||||
|
|
||||||
|
The configuration would then be dealt with using Puppet roles.
|
||||||
|
|
||||||
|
When you need to add a new appliance, you just download an image with
|
||||||
|
the correct UUID and it will add itself to the cluster.
|
||||||
|
|
||||||
|
# The bottom line
|
||||||
|
|
||||||
|
Of course, the important bit is the price. This is very much back of
|
||||||
|
envelope, but something like a Supermicro quad-node, where each node
|
||||||
|
consists of:
|
||||||
|
|
||||||
|
- 1x Xeon E5-2620V2 (6C, HT 2.1GHz)
|
||||||
|
- 64GB RAM
|
||||||
|
- 1x 240GB SSD
|
||||||
|
- 2x 1TB 10k SATA
|
||||||
|
- 4x 1Gb NIC
|
||||||
|
|
||||||
|
comes to \~£8500. This compares pretty well with a Nutanix NX-1000, for
|
||||||
|
10% of the price.
|
||||||
|
|
||||||
|
Something comparable to a the NX-3000 would again be 4 nodes, each
|
||||||
|
consisting of:
|
||||||
|
|
||||||
|
- 2x Xeon E5-2620V2 (6C, HT 2.1GHz)
|
||||||
|
- 128GB RAM
|
||||||
|
- 1x 480GB SSD
|
||||||
|
- 4x 1TB 10k SATA
|
||||||
|
- 4x 1Gb NIC
|
||||||
|
- 4x 10Gb NIC
|
||||||
|
|
||||||
|
would come to \~£15000. Again, this is 10% of the the price of the
|
||||||
|
commercial solution.
|
||||||
|
|
||||||
|
These are 90% markups! **90%!!!** Even when you add in the vSphere
|
||||||
|
licensing, that is still 70%. I have not seen any prices for any of the
|
||||||
|
EVO::RAIL vendors, but I do not see that it will be much different. Why
|
||||||
|
should it be?
|
||||||
|
|
||||||
|
Yes they are supported, but that is a lot to pay. I do not mean to pick
|
||||||
|
on Nutanix, they make a fantastic product - one that I have proposed to
|
||||||
|
customers on multiple occasions. The only reason I have used them is
|
||||||
|
because it is relatively easy to find pricing.
|
||||||
|
|
||||||
|
Is this a statement of intent? I do not know. For now I do not have the
|
||||||
|
time to run with this, but that does not mean I will not find the time.
|
||||||
|
It does give a good reference architecture that will work for 95% of use
|
||||||
|
cases with the above mentioned virtualisation/cloud platforms.
|
||||||
|
|
@ -0,0 +1,37 @@
|
||||||
|
---
|
||||||
|
date: 2013-09-05
|
||||||
|
title: Open Source Virtual SAN thought experiment
|
||||||
|
category: Opinions
|
||||||
|
---
|
||||||
|
|
||||||
|
Okay, I know I am little slow on the uptake here, but I was on holiday
|
||||||
|
at the time. The announcement of [Virtual
|
||||||
|
SAN](https://www.vmware.com/products/virtual-san/) at VMWorld the last
|
||||||
|
week got me thinking a bit.
|
||||||
|
|
||||||
|
Very briefly, Virtual SAN takes locally attached storage on you
|
||||||
|
hypervisors. It then turns it into a distributed object storage system
|
||||||
|
which you can use to store your VMDKs.
|
||||||
|
[Plenty](https://www.yellow-bricks.com/2013/09/05/how-do-you-know-where-an-object-is-located-with-virtual-san/)
|
||||||
|
[of](https://www.computerweekly.com/news/2240166057/VMware-Virtual-SAN-vision-to-disrupt-storage-paradigm)
|
||||||
|
[other](https://chucksblog.emc.com/chucks_blog/2013/08/considering-vsan.html)
|
||||||
|
[people](https://architecting.it/2013/08/29/reflections-on-vmworld-2013/)
|
||||||
|
have gone into a lot more detail. Unlike other systems that did a
|
||||||
|
similar job previously this is not a Virtual Appliance, but runs on the
|
||||||
|
hypervisors themselves.
|
||||||
|
|
||||||
|
The technology to do this sort of thing using purely Open Source exists.
|
||||||
|
All this has added is a distributed storage layer on each hypervisor.
|
||||||
|
There are plenty of these exist for Linux, with my preference probably
|
||||||
|
being for GlusterFS. Something like this is what I would have in mind:
|
||||||
|
|
||||||
|
{% img center <https://i.imgur.com/NHYdf78.png> %}
|
||||||
|
|
||||||
|
Ceph is probably the closest to Virtual SAN, as it is fundamentally
|
||||||
|
object-based. Yes there would be CPU and RAM overhead, but that also
|
||||||
|
exists for Virtual SAN too. Something like DRBD/GFS2 is not really
|
||||||
|
suitable here, because it will not scale-out as much. You would not have
|
||||||
|
to have local storage in all your hypervisor nodes (as with Virtual SAN)
|
||||||
|
too.
|
||||||
|
|
||||||
|
I honestly do not see any real problems with this.
|
||||||
81
content/blog/openstack-neutron-performance-problems/index.md
Normal file
|
|
@ -0,0 +1,81 @@
|
||||||
|
---
|
||||||
|
date: 2014-03-31
|
||||||
|
title: Openstack Neutron Performance problems
|
||||||
|
category: devops
|
||||||
|
featured_image: https://i.imgur.com/fSMzOUE.jpg
|
||||||
|
---
|
||||||
|
|
||||||
|
For the last few weeks I have been consulting on a private cloud project
|
||||||
|
for a local company. Unsurprisingly this has been based around the
|
||||||
|
typical Openstack setup.
|
||||||
|
|
||||||
|
- Nova - KVM
|
||||||
|
- Neutron - Openvswitch
|
||||||
|
- Cinder - LVM
|
||||||
|
- Glance - local files
|
||||||
|
|
||||||
|
My architecture is nothing out of the ordinary. A pair of hosts each
|
||||||
|
with 2 networks that look something like this:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
All this is configured using Red Hat RDO. I had done all this under both
|
||||||
|
Grizzly and, using RDO, it was 30 minutes to set up.
|
||||||
|
|
||||||
|
Given how common and simple the setup, imagine my surprise when it did
|
||||||
|
not work. What do I mean did not work? From the outset I was worried
|
||||||
|
about Neutron. While I am fairly up to date with SDN in theory, I am
|
||||||
|
fairly green in practise. Fortunately, while RDO does not automate it's
|
||||||
|
configuration, there is at least an [accurate
|
||||||
|
document](https://openstack.redhat.com/Neutron_with_existing_external_network)
|
||||||
|
in how to configure it.
|
||||||
|
|
||||||
|
Now, if I was just using small images that would probably be fine,
|
||||||
|
however this project required Windows images. As a result some problems
|
||||||
|
quickly surfaced. Each time I deployed a new Windows image, everything
|
||||||
|
would lock up:
|
||||||
|
|
||||||
|
- no network access to VM's
|
||||||
|
- Openvswitch going mad (800-1000% CPU)
|
||||||
|
- SSH access via eth0 completely dead
|
||||||
|
|
||||||
|
It has to be said that I initially barked up the wrong tree, pointing
|
||||||
|
the finger at disk access (usually the problem with shared systems).
|
||||||
|
However it turned out I was wrong.
|
||||||
|
|
||||||
|
A brief Serverfault/Twitter with \@martenhauville brought up a few
|
||||||
|
suggestions, one of which caught my eye:
|
||||||
|
|
||||||
|
> <https://ask.openstack.org/en/question/25947/openstack-neutron-stability-problems-with-openvswitch/>
|
||||||
|
> there are known Neutron configuration challenges to overcome with GRE
|
||||||
|
> and MTU settings
|
||||||
|
|
||||||
|
This is where my problem lay: the external switch had an MTU of 1500,
|
||||||
|
Openvswitch also. Finally, `ip link` in a VM would give you
|
||||||
|
|
||||||
|
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master br-ex state UP mode DEFAULT qlen 1000
|
||||||
|
|
||||||
|
Everything matches, however I was using GRE tunnels, which add a header
|
||||||
|
to each frame. This was pushing them over 1500 on entry to `br-tun`
|
||||||
|
causing massive network fragmentation, which basically destroyed
|
||||||
|
Openvswitch every time I performed a large transfer. It showed up when
|
||||||
|
deploying an image, because that is hitting the Glance API over http.
|
||||||
|
|
||||||
|
Once armed with this knowledge, the fix is trivial. Add the following to
|
||||||
|
`/etc/neutron/dhcp_agent.ini`:
|
||||||
|
|
||||||
|
dnsmasq_config_file=/etc/neutron/dnsmasq-neutron.conf
|
||||||
|
|
||||||
|
Now create the file `/etc/neutron/dnsmasq-neutron.conf` which contains
|
||||||
|
the following:
|
||||||
|
|
||||||
|
dhcp-option-force=26,1454
|
||||||
|
|
||||||
|
Now you can restart the DHCP agent and all will be well:
|
||||||
|
|
||||||
|
service neutron-dhcp-agent restart
|
||||||
|
|
||||||
|
I've gone on a bit in this post, as I feel the background is important.
|
||||||
|
By far the hardest part was diagnosing the problem, without knowing what
|
||||||
|
my background was it would be much harder to narrow down your problem to
|
||||||
|
being the same as mine.
|
||||||
100
content/blog/playing-with-docker-swarm-mode/index.md
Normal file
|
|
@ -0,0 +1,100 @@
|
||||||
|
---
|
||||||
|
date: 2016-07-10
|
||||||
|
title: Playing with Docker Swarm Mode
|
||||||
|
category: devops
|
||||||
|
---
|
||||||
|
|
||||||
|
|
||||||
|
The big announcement of the recent DockerCon was 1.12 integrating Swarm. As far the as the ecosystem goes that is quite a game changer, but I will not be dwelling on that. I am just going to regurgitate what others have said and add a few bit of my own.
|
||||||
|
|
||||||
|
I am going to build a simple cluster that looks like this:
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
What we have here is 2 nodes running Centos 7 which run Docker 1.12-rcX in swarm mode. I am actually only going to create a single manager and a worker. For a bonus, I am going to touch on a subject that has been ignored a little: storage.
|
||||||
|
|
||||||
|
Many will say that your application should use S3, or whatever. The fact is that POSIX storage is really useful though. So, we need a way of having storage at the same place on each node that can be used as a volume in our application containers. In keeping with the principles of Swarm, this storage needs to be distributed, replicated and scalable. In the Open Source world we have 2 major players (and plenty of others) in [Ceph](https://ceph.com) and [Gluster](https://www.gluster.org/). They are both awesome, scalable, stable, blahblahblah. Either would be a great choice, but I am going to use Gluster because, err, reasons. Basically I flipped a coin.
|
||||||
|
|
||||||
|
I will make each of the 2 nodes a Gluster server with a replicated volume. I will then mount the volume on each node.
|
||||||
|
|
||||||
|
I am assuming that you have a pair of clean, and up-to-date, CentOS 7 nodes. I also assume that they have a single NIC (not best-practise, but we are playing here) and can resolve each other by name (either by DNS or `/etc/hosts`).
|
||||||
|
|
||||||
|
## Gluster
|
||||||
|
|
||||||
|
See the main docs for more info, but the *very* basic process is (on each node):
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo yum install centos-release-gluster epel-release
|
||||||
|
sudo yum install glusterfs-server
|
||||||
|
sudo systemctl enable glusterd
|
||||||
|
sudo systemctl start glusterd
|
||||||
|
```
|
||||||
|
|
||||||
|
Now create the cluster. From node1 run:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo gluster peer probe node2
|
||||||
|
```
|
||||||
|
|
||||||
|
Next, from node2 run
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo gluster peer probe node1
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, we have our storage cluster setup we need to create a volume. On each node create a folder to store the data:
|
||||||
|
|
||||||
|
```
|
||||||
|
mkdir -pv /data/brick1/gv0
|
||||||
|
```
|
||||||
|
|
||||||
|
As an aside, I mount a seperate disk at `/data/brick1` formatted with XFS. This is not essential for our purposes though.
|
||||||
|
|
||||||
|
Now, from `node1` (because it will be our master, so my OCD dictates it is also our admin node) create the volume:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo gluster volume create gv0 replica 2 node1:/data/brick1/gv0 node2:/data/brick1/gv0
|
||||||
|
sudo gluster volume start gv0
|
||||||
|
```
|
||||||
|
|
||||||
|
Now on each node mount the volume:
|
||||||
|
|
||||||
|
```
|
||||||
|
echo "$(hostname -s):/gv0 /mnt glusterfs defaults,_netdev 0 0" | sudo tee -a /etc/fstab
|
||||||
|
sudo mount /mnt
|
||||||
|
```
|
||||||
|
|
||||||
|
## Docker
|
||||||
|
|
||||||
|
We'll install Docker using `docker-machine`. I do it from an admin machine, but you could use one of your cluster nodes. You need to have [passwordless root SSH access](http://bfy.tw/2AYK) to your nodes.
|
||||||
|
|
||||||
|
Install `docker-engine` and `docker-machine` as root on the admin node:
|
||||||
|
|
||||||
|
```
|
||||||
|
curl -fsSL https://experimental.docker.com/ | sudo sh
|
||||||
|
curl -L https://github.com/docker/machine/releases/download/v0.8.0-rc2/docker-machine-`uname -s`-`uname -m` > docker-machine && \
|
||||||
|
chmod +x docker-machine
|
||||||
|
sudo mv -v docker-machine /usr/local/bin/
|
||||||
|
```
|
||||||
|
|
||||||
|
Now you can go ahead and install docker-engine on the cluster nodes:
|
||||||
|
|
||||||
|
```
|
||||||
|
docker-machine create --engine-install-url experimental.docker.com \
|
||||||
|
-d generic --generic-ip-address=node-1 \
|
||||||
|
--generic-ssh-key /root/.ssh/id_rsa node-1
|
||||||
|
docker-machine create --engine-install-url experimental.docker.com \
|
||||||
|
-d generic --generic-ip-address=node-2 \
|
||||||
|
--generic-ssh-key /root/.ssh/id_rsa node-2
|
||||||
|
```
|
||||||
|
|
||||||
|
Now you can enable Swarm mode:
|
||||||
|
|
||||||
|
```
|
||||||
|
eval $(docker-machine env node1)
|
||||||
|
docker swarm init
|
||||||
|
eval $(docker-machine env node2)
|
||||||
|
docker swarm join node1:2377
|
||||||
|
```
|
||||||
|
|
||||||
|
That is it - you now have a swarm cluster. I have another post coming where I will describe a method I use for collecting metrics about the cluster. That will also include deploying an application on the cluster too.
|
||||||
91
content/blog/replace-failed-kubernetes-etcd-member/index.md
Normal file
|
|
@ -0,0 +1,91 @@
|
||||||
|
---
|
||||||
|
date: 2019-03-28
|
||||||
|
title: Replace Failed Kubernetes Etcd Member
|
||||||
|
category: devops
|
||||||
|
featured_image: /images/kubernetes.png
|
||||||
|
---
|
||||||
|
|
||||||
|
I had a pretty knotty problem in my homelab. I am running a Kubernetes cluster in the with 3 masters and an embeded Etcd cluster.
|
||||||
|
That means that the Etcd cluster runs on the same nodes as the K8s API and scheduler pods. Like them, it is running as Pods controlled directly by Kubelet (magic! except it isn't). The data on one of those members (node3) got corrupted, so naturally it would no longer join the cluster.
|
||||||
|
|
||||||
|
What you need to do is remove that (etcd) node from the cluster and recreate it. This is pretty simple, but needs a bit of under-the-bonnet knowledge. So how is this Pod configurered?
|
||||||
|
|
||||||
|
I hinted at a bit of magic earlier. These pods are running in K8s, and visible in the `kube-system` namespace, but are not actually manged by the Kubernetes scheduler. They are managed by the Kubelet itself. Kubelet on each master watches `/etc/kubernetes/manifests` and will action any valid manifest files you place in that folder. When I installed the cluster with `kubeadm` it did the following:
|
||||||
|
|
||||||
|
```
|
||||||
|
$ ls /etc/kubernetes/manifests/
|
||||||
|
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
|
||||||
|
```
|
||||||
|
|
||||||
|
The part which interests me is in the `spec.volumes` key of `etcd.yaml`:
|
||||||
|
|
||||||
|
```
|
||||||
|
spec:
|
||||||
|
volumes:
|
||||||
|
- hostPath:
|
||||||
|
path: /etc/kubernetes/pki/etcd
|
||||||
|
type: DirectoryOrCreate
|
||||||
|
name: etcd-certs
|
||||||
|
- hostPath:
|
||||||
|
path: /var/lib/etcd
|
||||||
|
type: DirectoryOrCreate
|
||||||
|
name: etcd-data
|
||||||
|
```
|
||||||
|
|
||||||
|
This tells me 2 things:
|
||||||
|
|
||||||
|
1. The actual cluster data is store in `/var/lib/etcd` on my physical node
|
||||||
|
2. The certificates for cluster comms are in `/etc/kubernetes/pki/etcd`
|
||||||
|
|
||||||
|
So now I need `etcdctl` that I can use which can access both the kube masters and those certificates. I actually had it on another machine in the lab, so I copied the `pki/etcd` contents to that machine, but you could put `etcdctl` on the broken master, it is just a binary.
|
||||||
|
|
||||||
|
You will need the UUID for your failed node:
|
||||||
|
|
||||||
|
```
|
||||||
|
export ETCDCTL="etcdctl --endpoints=https://<node1>:2379,https://<node2>:2379,https://<node3>:2379 \
|
||||||
|
--cert /etc/kubernetes/pki/etcd/server.crt \
|
||||||
|
--key /etc/kubernetes/pki/etcd/server.key \
|
||||||
|
--cacert /etc/kubernetes/pki/etcd/ca.crt
|
||||||
|
${ETCDCTL} member list
|
||||||
|
```
|
||||||
|
|
||||||
|
Remove the failed node from the Etcd cluster:
|
||||||
|
|
||||||
|
```
|
||||||
|
${ETCDCTL} remove <uuid-of-failed-node>
|
||||||
|
```
|
||||||
|
|
||||||
|
The simple move the `etcd.yaml` to one side:
|
||||||
|
|
||||||
|
```
|
||||||
|
mv /etc/kubernetes/manifests/etcd.yaml .
|
||||||
|
```
|
||||||
|
|
||||||
|
The kubelet wil then stop the Etcd pod and you can clean up its corrupted data dir:
|
||||||
|
|
||||||
|
```
|
||||||
|
rm -rf /var/lib/etcd/member
|
||||||
|
```
|
||||||
|
|
||||||
|
Re-start the pod:
|
||||||
|
|
||||||
|
```
|
||||||
|
mv etcd.yaml /etc/kubernetes/manifests/
|
||||||
|
```
|
||||||
|
|
||||||
|
That will restart the pod, but you still need to add it to the cluster:
|
||||||
|
|
||||||
|
```
|
||||||
|
${ETCDCTL} member add --peer-urls=https://<node3>:2380 <node3>
|
||||||
|
```
|
||||||
|
|
||||||
|
It will probably take a couple of restarts before it is properly healthy, but Kubelet will take care of that.
|
||||||
|
|
||||||
|
Before long you can run `${ETCDCTL} endpoint health` and all will return good.
|
||||||
|
|
||||||
|
## Conclusion
|
||||||
|
|
||||||
|
Nothing was actually that complex, but I needed to know a couple of things about how K8s does things:
|
||||||
|
|
||||||
|
1. Where `kubeadm` put the certificates
|
||||||
|
2. That Kubelet watches `/etc/kubernetes/manifests` for static Pods (defined by `staticPodPath`).
|
||||||
143
content/blog/rhel-and-centos-joining-forces/index.md
Normal file
|
|
@ -0,0 +1,143 @@
|
||||||
|
---
|
||||||
|
date: 2014-01-08
|
||||||
|
title: RHEL and CentOS joining forces
|
||||||
|
category: Opinions
|
||||||
|
featured_image: https://i.imgur.com/3colCNj.png
|
||||||
|
---
|
||||||
|
|
||||||
|
Yesterday saw probably the biggest FLOSS news in recent times. Certainly
|
||||||
|
the biggest news of 2014 so far :-) By some freak of overloaded RSS
|
||||||
|
readers, I missed the announcement, but I did see this:
|
||||||
|
|
||||||
|
<blockquote class="twitter-tweet" lang="en"><p>
|
||||||
|
Day 1 at the new job. Important stuff first.. Where do I get my Red Hat
|
||||||
|
?
|
||||||
|
|
||||||
|
</p>
|
||||||
|
--- Karanbir Singh (\@CentOS) January 8, 2014
|
||||||
|
|
||||||
|
</blockquote>
|
||||||
|
<script async src="//platform.twitter.com/widgets.js" charset="utf-8"></script>
|
||||||
|
<!-- more -->
|
||||||
|
It did not take long to dig up
|
||||||
|
[this](https://community.redhat.com/centos-faq/?utm_content=buffer6403d&utm_source=buffer&utm_medium=twitter&utm_campaign=Buffer)
|
||||||
|
and
|
||||||
|
[this](https://lists.centos.org/pipermail/centos-announce/2014-January/020100.html),
|
||||||
|
where Red Hat and CentOS respectively announce that they have joined
|
||||||
|
forces. Some things from the announcement struck me:
|
||||||
|
|
||||||
|
> Some of us now work for Red Hat, but not RHEL
|
||||||
|
|
||||||
|
That is important! This says to me that Red Hat see the value of CentOS
|
||||||
|
as an entity in itself. By not linking the CentOS developers to RHEL in
|
||||||
|
anyway, they are not going to be side-tracking them. Instead, they are
|
||||||
|
simple freeing them up to work more effectively on CentOS.
|
||||||
|
|
||||||
|
> we are now able to work with the Red Hat legal teams
|
||||||
|
|
||||||
|
QA was always a problem for CentOS, simply because it took place
|
||||||
|
effectively in secret. Now they can just walk down the corridor to talk
|
||||||
|
to the lawyers who would have previously (potentially) sued them, all
|
||||||
|
the potential problems go away.
|
||||||
|
|
||||||
|
# The RHEL Ecosystem
|
||||||
|
|
||||||
|
In the beginning there is [Fedora](https://fedoraproject.org)), where
|
||||||
|
the RHEL developers get to play. Here is where they can try new things
|
||||||
|
and make mistakes. In Fedora things can break without people really
|
||||||
|
worrying (especially in Rawhide). The exception to this is my wife as we
|
||||||
|
run it on the family PC and she gets quite frustrated with its foibles.
|
||||||
|
However, she knew she was marrying a geek from the outset, so I will not
|
||||||
|
accept any blame for this.
|
||||||
|
|
||||||
|
Periodically, the the Fedora developers will pull everything together
|
||||||
|
and create a release that has the potential to be transformed into RHEL.
|
||||||
|
Here they pull together all the things that have be learnt over the last
|
||||||
|
few releases. I consider this an Alpha release of RHEL. At this point,
|
||||||
|
behind the scenes, the RHEL developers will take those packages and
|
||||||
|
start work on the next release of RHEL.
|
||||||
|
|
||||||
|
{% pullquote %} On release of RHEL, Red Hat make the source code
|
||||||
|
available, as required by the terms of the GPL (and other relevant
|
||||||
|
licenses).The thing is, {\"Red Hat as a company are built on Open
|
||||||
|
Source\"} principles, they firmly believe in them and, best of all, they
|
||||||
|
practise what the preach. They would still be within the letter of the
|
||||||
|
law if the just dumped a bunch of apparently random scripts on a web
|
||||||
|
server. Instead, they publish the SRPM packages used to build RHEL. {%
|
||||||
|
endpullquote %}
|
||||||
|
|
||||||
|
CentOS then take these sources and get to work. By definition they are
|
||||||
|
always beind RHEL. As many know this got pretty bad at one point:
|
||||||
|
|
||||||
|
{% img <https://www.standalone-sysadmin.com/~matt/centos-delays.jpg>
|
||||||
|
center %}
|
||||||
|
|
||||||
|
(Thanks to Matt Simmons, aka [Standalone
|
||||||
|
Sysadmin](https://www.standalone-sysadmin.com), from whom I blatantly
|
||||||
|
stole that graph, I'll ask permission later)
|
||||||
|
|
||||||
|
Since then, things have got better, with new point releases coming hot
|
||||||
|
on the heels of RHEL. Certainly preparations for EL7 seemed to be going
|
||||||
|
on nicely even before this announcement.
|
||||||
|
|
||||||
|
# how does this now affect the two projects
|
||||||
|
|
||||||
|
Both CentOS and Red Hat have a lot to gain from this alliance. <img
|
||||||
|
src='https://i.imgur.com/qbKvXko.jpg' class='image-process-article-image' />I am sure that there
|
||||||
|
are few people in the wider community who will be upset, but I think
|
||||||
|
that it is a good thing. The reality is that CentOS and RHEL have never
|
||||||
|
been enemies. The people that are using CentOS are just simply never
|
||||||
|
going to pay Red Hat for support they do not need.
|
||||||
|
|
||||||
|
When I started at Snell (then Snell & Wilcox), the official line was to
|
||||||
|
use RHEL for all our Linux servers. They had everything paid up for a
|
||||||
|
couple of years at the time. By the time renewal came around the global
|
||||||
|
financial crisis had hit, we had used the support two or three times and
|
||||||
|
each time I had solved the problem before Red Hat answered the ticket.
|
||||||
|
So, we decided to switch to CentOS (which was trivial).
|
||||||
|
|
||||||
|
At the other end of the scale you have the web-scale people. For them,
|
||||||
|
paying Red Hat for support is both unnecessary (they have the right
|
||||||
|
people on staff) and prohibitively expensive. When you have tens of
|
||||||
|
thousands of nodes you cannot use a licensing model that support each
|
||||||
|
one.
|
||||||
|
|
||||||
|
In the cloud model you also have a problem, in that you are effectively
|
||||||
|
renting an OS. Microsoft and Red Hat you have an administrative overhead
|
||||||
|
of ensuring you have the right licenses available. In my experience Red
|
||||||
|
Hat make it a lot easier, but it is an overhead none the less.
|
||||||
|
|
||||||
|
All three of these will get a huge benefit. Now that the CentOS
|
||||||
|
developers are on staff at Red Hat they have direct access to the source
|
||||||
|
code. There should no longer be any need to wait for RHEL to drop before
|
||||||
|
they start building. Red Hat will be supplying infrastructure and
|
||||||
|
community support, which will also be a massive bonus.
|
||||||
|
|
||||||
|
So what do Red Hat gain? In terms of new customers, they may get some of
|
||||||
|
that first group. These are the people that may well do their testing
|
||||||
|
with CentOS, but may now choose to go production with RHEL. I certainly
|
||||||
|
would be more willing to now that XFS is not in a separate (expensive)
|
||||||
|
RAN channel. I do not see the cloud or web-scale people changing to a
|
||||||
|
paid support model. It will remain prohibitively expensive for them.
|
||||||
|
|
||||||
|
I think they biggest thing that Red Hat will gain is that get to give
|
||||||
|
Oracle a good kicking. Oracle basically do the same thing as CentOS, but
|
||||||
|
they stick a thumping great big support charge on it. To be honest I
|
||||||
|
have never really worked out why anyone would use it. Yes they are
|
||||||
|
cheaper than Red Hat, but not by much. A couple of years ago Red Hat
|
||||||
|
took steps to [make life
|
||||||
|
harder](https://www.theregister.co.uk/2011/03/04/red_hat_twarts_oracle_and_novell_with_change_to_source_code_packaging/).
|
||||||
|
That had an unfortunate knock-on effect on CentOS, causing the huge
|
||||||
|
delay in CentOS 6. Now CentOS should not have that problem as they are
|
||||||
|
closer to source.
|
||||||
|
|
||||||
|
TL;DR
|
||||||
|
-----
|
||||||
|
|
||||||
|
CentOS and RHEL joining forces is in my opinion a really good thing,
|
||||||
|
with both parties getting significant benefits. Granted they are bit
|
||||||
|
less tangible for Red Hat, but that does not make them any less
|
||||||
|
significant.
|
||||||
|
|
||||||
|
Personally I am really excited to see what it is in store - especially
|
||||||
|
from CentOS. I even have a couple of SIG ideas too.
|
||||||
|
|
@ -0,0 +1,64 @@
|
||||||
|
---
|
||||||
|
date: 2015-06-01
|
||||||
|
title: Send mail from Gitlab through Mandrill using Postfix
|
||||||
|
slug: send-mail-from-gitlab-through-mandrill-using-postfix
|
||||||
|
category: linux
|
||||||
|
featured_image: http://i.imgur.com/W709cC9m.png
|
||||||
|
---
|
||||||
|
|
||||||
|
I am a fan of Gitlab. While Github is great, and I [use it
|
||||||
|
heavily](https://github.com/chriscowley), one should never be 100%
|
||||||
|
reliant on the whims of a for-profit company. After all, their agenda is
|
||||||
|
not the same as mine and could chang in the future. I also use it for
|
||||||
|
projects at work where we do not necessarily want to allow public
|
||||||
|
access.
|
||||||
|
|
||||||
|
Sending emails however is a little complicated. A good email server
|
||||||
|
needs DNS and and SMTP properly configured. You then spend all your
|
||||||
|
waking hours ensuring that you are not on any blacklists. Once you have
|
||||||
|
done that you may even have to time to do the rest of your job.
|
||||||
|
|
||||||
|
[Mandrill](https://mandrillapp.com/) takes care of all this for you,
|
||||||
|
then provides both SMTP and REST access. Gitlab, by default, uses SMTP
|
||||||
|
to send its emails, so you simply configure your SMTP server of choice
|
||||||
|
to use Mandrill to relay its messages. Personally I use Postfix as it is
|
||||||
|
installed by default on RHEL/CentOS.
|
||||||
|
|
||||||
|
In Gitlab, there is nothing to do on a default install. It will use
|
||||||
|
whatever your servers install MTA is. This actually means that this post
|
||||||
|
is actually in no way related to Gitlab - Postfix/Mandrill only.
|
||||||
|
|
||||||
|
You will need to install `cyrus-sasl-plain`:
|
||||||
|
|
||||||
|
sudo yum install cyrus-sasl-plain`
|
||||||
|
|
||||||
|
Modify the file /etc/postfix/main.cf to contain:
|
||||||
|
|
||||||
|
myorigin = example.com
|
||||||
|
smtp_sasl_auth_enable = yes
|
||||||
|
smtp_sasl_password_maps = hash:/etc/postfix/sasl_passwd
|
||||||
|
smtp_sasl_security_options = noanonymous
|
||||||
|
smtp_use_tls = yes
|
||||||
|
relayhost = [smtp.mandrillapp.com]
|
||||||
|
|
||||||
|
Next you need to get the credentials Postfix will use to connect to
|
||||||
|
Mandrill. Go into \"Settings\" -\> \"SMTP & API Info\". Create a new API
|
||||||
|
key for Gitlab. You account name is your username, and this API key will
|
||||||
|
be your password. You can use any API key or a single API key for many
|
||||||
|
services, but I use a separate key for each service. That way, if a
|
||||||
|
service is compromised, I can just delete the key to block it.
|
||||||
|
|
||||||
|
<img src="/images/GYvvKrx.png" class='image-process-article-image' />
|
||||||
|
|
||||||
|
Create the file `/etc/postfix/sasl_passwd` containing:
|
||||||
|
|
||||||
|
[smtp.mandrillapp.com] <your-account-name>:<a-long-key>
|
||||||
|
|
||||||
|
You need to secure that, so run `chmod 600 /etc/postfix/sasl_passwd`.
|
||||||
|
|
||||||
|
Finally, you need to map that file and restart Postfix:
|
||||||
|
|
||||||
|
sudo /etc/postfix/sasl_passwd
|
||||||
|
sudo systemctl restart postfix
|
||||||
|
|
||||||
|
Voila, now you should be able to send emails from the CLI and Gitlab.
|
||||||
80
content/blog/sftp-chroot-on-centos/index.md
Normal file
|
|
@ -0,0 +1,80 @@
|
||||||
|
---
|
||||||
|
date: 2012-11-19
|
||||||
|
title: SFTP Chroot on CentOS
|
||||||
|
category: linux
|
||||||
|
---
|
||||||
|
|
||||||
|
This came up today where I needed to give secure file transfer to
|
||||||
|
customers. To complicate things I had to use an out-of-the-box RHEL6
|
||||||
|
system. The obvious answer was to use SSH and limit those users to SFTP
|
||||||
|
only. Locking them into a chroot was not a requirement, but it seemed
|
||||||
|
like a good idea to me. I found plenty of docs that got 80% of the way,
|
||||||
|
or took a shortcut, but this should be complete.
|
||||||
|
|
||||||
|
The basic steps are:
|
||||||
|
|
||||||
|
1. Create a group and the users to that group
|
||||||
|
2. Modify the SSH daemon configuration to limit a group to sftp only
|
||||||
|
3. Setup file system permissions
|
||||||
|
4. Configure SELinux
|
||||||
|
5. Test (of course)
|
||||||
|
|
||||||
|
Without further ado, lets get started. It should only take about 10
|
||||||
|
minutes, nothing here is especially complex.
|
||||||
|
|
||||||
|
Create a group that is limited to SFTP only and a user to be in that
|
||||||
|
group.
|
||||||
|
|
||||||
|
groupadd sftponly
|
||||||
|
useradd sftptest
|
||||||
|
usermod -aG sftponly sftptest
|
||||||
|
|
||||||
|
Now you need to make a little change to `/etc/ssh/sshd_config`. There
|
||||||
|
will be a *Subsystem* line for `sftp` which you need to change to read:
|
||||||
|
|
||||||
|
Subsystem sftp internal-sftp
|
||||||
|
|
||||||
|
Now you need to create a block at the end to limit members of a group
|
||||||
|
(ie the sftponly group you created above) and chroot them. Simply add
|
||||||
|
the following to the end of the file:
|
||||||
|
|
||||||
|
Match Group sftponly
|
||||||
|
ChrootDirectory %h
|
||||||
|
ForceCommand internal-sftp
|
||||||
|
X11Forwarding no
|
||||||
|
AllowTcpForwarding no
|
||||||
|
|
||||||
|
These changes will require a reload of the SSH daemon:
|
||||||
|
`service sshd reload`
|
||||||
|
|
||||||
|
Now you need to make some file permission changes. For some reason which
|
||||||
|
I cannot work out for now, the home directory must be owned by root and
|
||||||
|
have the permissions 755. So we will also need to make a folder in the
|
||||||
|
home directory to upload to and make that owned by the user.
|
||||||
|
|
||||||
|
sudo -u sftptest mkdir -pv /home/sftptest/upload
|
||||||
|
chown root. /home/sftptest
|
||||||
|
chmod 755 /home/sftptest
|
||||||
|
chgrp -R sftponly /home/sftptest
|
||||||
|
|
||||||
|
The last thing we need to do is tell SELinux that we want to upload
|
||||||
|
files via SFTP to a chroot as it is read-only by default. Of course you
|
||||||
|
are running SELinux in enforcing mode aren\'t you :)
|
||||||
|
|
||||||
|
setsebool -P ssh_chroot_rw_homedirs on
|
||||||
|
|
||||||
|
Now from another console you can sftp to your server
|
||||||
|
|
||||||
|
sftp sftptest@<server>
|
||||||
|
|
||||||
|
You should then be able to put a file in your upload folder. However if
|
||||||
|
you try to ssh to the server as the user *sftptest* it should tell you
|
||||||
|
to go away. Of course you should be able to *ssh* as your normal user
|
||||||
|
with no problem. Pro tip: make sure to leave a root terminal open just
|
||||||
|
in case.
|
||||||
|
|
||||||
|
Required reading:
|
||||||
|
|
||||||
|
- [CentOS Wiki SELinux](https://wiki.centos.org/HowTos/SELinux)
|
||||||
|
- [CentOS Wiki
|
||||||
|
SELinuxBooleans](https://wiki.centos.org/TipsAndTricks/SelinuxBooleans)
|
||||||
39
content/blog/something-from-the-shadows/index.md
Normal file
|
|
@ -0,0 +1,39 @@
|
||||||
|
---
|
||||||
|
date: 2013-02-21
|
||||||
|
title: Something from the shadows
|
||||||
|
category: Opinions
|
||||||
|
---
|
||||||
|
|
||||||
|
An intriguing startup came out of stealth mode a few days ago. [Pernix
|
||||||
|
Data](https://pernixdata.com/) was founded by Pookan Kumar and Satyam
|
||||||
|
Vaghani, both of who were pretty near top of the pile in VMware\'s
|
||||||
|
storage team.
|
||||||
|
|
||||||
|
What they are offering is, to me at least, a blinding flash of the
|
||||||
|
obvious. It is a softweare layer that runs on a VMware hypervisor that
|
||||||
|
uses local flash as a cache for whatevery is coming off your main
|
||||||
|
storage array. {% img right
|
||||||
|
[https://pernixdata.com/images/home\\\_graphic3.png](https://pernixdata.com/images/home\_graphic3.png)
|
||||||
|
300 217 %}. That could be an SSD (or multiple) or a PCI-e card.
|
||||||
|
|
||||||
|
Reading what they have to say, it is completely transparent to the
|
||||||
|
hypervisor, so everything just works. Obviously me being an Open Source
|
||||||
|
fanatic I imediately started thinking how I could do this with Linux; it
|
||||||
|
took me about 5 minutes.
|
||||||
|
|
||||||
|
You take your SAN array and give your LUN to your Hypervisors (running
|
||||||
|
KVM obviously, and with a local SSD). Normally you would stick a
|
||||||
|
clustered file system (such as GFS2) on that shared LUN. Instead you use
|
||||||
|
a tiered block device on top of that LUN. There are two that come
|
||||||
|
immediately to mind:
|
||||||
|
[Flashcache](https://github.com/facebook/flashcache/) and
|
||||||
|
[Btier](https://sourceforge.net/projects/tier/files/).
|
||||||
|
|
||||||
|
Finally, you can put your clustered file system on that tiered device. I
|
||||||
|
do not have the time or facilities to test this, but I cannot see why it
|
||||||
|
would not work. Maybe someone at Red Hat (seeing as they do the bulk of
|
||||||
|
KVM and GFS2 development) can run with this and see what happens. What
|
||||||
|
their plans are I do not know. It is very early days, maybe they will be
|
||||||
|
a success maybe not. As they are both ex-VMware, I would not be at all
|
||||||
|
surprised if they get bought back into the VMware fold. Certainly this
|
||||||
|
is a functionality that I would have like to have seen in the past.
|
||||||
155
content/blog/stop-the-hate-on-software-raid/index.md
Normal file
|
|
@ -0,0 +1,155 @@
|
||||||
|
---
|
||||||
|
date: 2013-04-07
|
||||||
|
title: Stop the hate on software RAID
|
||||||
|
category: Opinions
|
||||||
|
featured_image: /images/3140gr.jpg
|
||||||
|
---
|
||||||
|
|
||||||
|
I've had a another bee in
|
||||||
|
my bonnet recently. Specifically, it has been to do with hardware vs
|
||||||
|
software RAID, but I think it goes deeper than that. It started a couple
|
||||||
|
of months back with a discussion on [Reddit](https://redd.it/18dp63).
|
||||||
|
Some of the comments were:
|
||||||
|
|
||||||
|
> Get out, get out now.
|
||||||
|
>
|
||||||
|
> while he still can..
|
||||||
|
>
|
||||||
|
> WHAT!? 60 TB on software raid. Jeezus.
|
||||||
|
>
|
||||||
|
> Software raid? Get rid of it.
|
||||||
|
|
||||||
|
It then got re-awakened the other day when Matt Simmons (aka [The
|
||||||
|
Standalone Sysadmin](https://www.standalone-sysadmin.com/blog/)) asked
|
||||||
|
the following question on Twitter:
|
||||||
|
|
||||||
|
<blockquote class="twitter-tweet"><p>
|
||||||
|
So what are the modern arguments for / against hardware / software RAID?
|
||||||
|
I don't get out much. #sysadmin
|
||||||
|
|
||||||
|
</p>
|
||||||
|
--- Matt Simmons (@standaloneSA) April 4, 2013
|
||||||
|
|
||||||
|
</blockquote>
|
||||||
|
<script async src="//platform.twitter.com/widgets.js" charset="utf-8"></script>
|
||||||
|
At the time of writing, 2 people replied: myself and [Chris
|
||||||
|
Siebenmann](https://utcc.utoronto.ca/~cks/space/blog/). Both of us
|
||||||
|
basically said software RAID is better, hardware is at best pointless.
|
||||||
|
|
||||||
|
First of all, I need to define what I mean by hardware RAID. First, I do
|
||||||
|
not care about what you are using for your c: drive in Windows, or your
|
||||||
|
/ partition in Linux. I am talking about the place where you store your
|
||||||
|
business critical data. If you file server goes down, that is a bad day,
|
||||||
|
but the business will live on. Lose your business data, then you will be
|
||||||
|
out of a job (most likely alongside everyone else). Hardware RAID can
|
||||||
|
thus fall into to categories:
|
||||||
|
|
||||||
|
- a bunch of disks attached to a PCI-e card in a big server
|
||||||
|
- an external storage array. This could be either SAN or NAS, once
|
||||||
|
again I do not care in this instance.
|
||||||
|
|
||||||
|
I am firmly of the opinion that hardware RAID cards should no longer
|
||||||
|
exist. They are at best pointless and at worst a liability. Modern
|
||||||
|
systems are so fast that there is no real performance hit. Also
|
||||||
|
management is a lot easier; if you have a hardware array then you will
|
||||||
|
need to load the manufacturer\'s utilities in order to manage it. By
|
||||||
|
manage, I mean to be told when a disk has failed. On Linux, there is no
|
||||||
|
guarantee that will work. There is a couple of vendors that require
|
||||||
|
packages from RHEL4 to be installed on RHEL6 systems to install their
|
||||||
|
tools. Also, they are invariable closed source, will most likely taint
|
||||||
|
my kernel with binary blobs and generally cause a mess on my previously
|
||||||
|
clean system. By contrast, using software RAID means that I can do all
|
||||||
|
the management with trivial little scripts that can easily be integrated
|
||||||
|
with any monitoring system that I choose to use.
|
||||||
|
|
||||||
|
I can understand why people are skeptical of software RAID. There have
|
||||||
|
been performance reasons and practical reasons for it not to be trusted.
|
||||||
|
I\'m not going to address the performance argument, suffice to say that
|
||||||
|
RAID is now 25 years old - CPUs have moved on a lot in that time. I
|
||||||
|
remember when the first Promise IDE controllers came out, that used a
|
||||||
|
kind of pseudo-hardware RAID - it was not pretty. The preconceptions are
|
||||||
|
compounded by the plethora of nasty controllers built in to consumer
|
||||||
|
motherboards and (possibly worst of all) Window\'s built in RAID that
|
||||||
|
was just bad.
|
||||||
|
|
||||||
|
The thing is, those days are now a long way behind us. For Linux there
|
||||||
|
is absolutely no need for hardware RAID, even Windows will be just fine
|
||||||
|
with an motherboard based RAID for its c: drive.
|
||||||
|
|
||||||
|
In fact I would say that hardware RAID is a
|
||||||
|
liability. You go to all that effort to safe-guard your data, but the
|
||||||
|
card becomes a single-point-of-failure. It dies, then you spend your
|
||||||
|
time searching Ebay for the same model of card. You buy it, then you
|
||||||
|
pray that the RAID data is stored on the disks and not the controller
|
||||||
|
(not always the case). By contrast, if you use software RAID and the
|
||||||
|
motherboard dies, then you pull the disks and plug them into whatever
|
||||||
|
box running Linux and you recover your data.
|
||||||
|
|
||||||
|
There is definitely a time and place for an external array. If you are
|
||||||
|
using virtualisation properly, you need shared storage. The best way to
|
||||||
|
do that, 9 times out of 10, is with an external array. However, even
|
||||||
|
that may well not be as it seems. There are some that still develop
|
||||||
|
dedicated hardware and come out with exciting gear (HP 3Par and Hitachi
|
||||||
|
Data Systems spring to mind). However, the majority of storage is now on
|
||||||
|
Software.
|
||||||
|
|
||||||
|
Let take a look at these things and see just how much \"hardware\" is
|
||||||
|
actually involved.
|
||||||
|
|
||||||
|
The EMC VMAX is a big, big black box of storage. Even the \"baby\" 10k
|
||||||
|
one scales up to 1.5PB and 4 engines. The 40k will go up to 3PB and 8
|
||||||
|
engines. Look a little deeper (one line further on the spec sheet) and
|
||||||
|
you find that what those engines are: quad Xeons (dual on the 10/20k).
|
||||||
|
The great big bad VMAX is a bunch of standard x86 servers running funky
|
||||||
|
software to do all the management and RAID calculations.
|
||||||
|
|
||||||
|
Like its big brother, the VNX is also a pair of Xeon
|
||||||
|
servers. Even more, it runs Windows. In fact since the Clariion CX4
|
||||||
|
EMC has been using Windows Storage Server (based on XP) Move along
|
||||||
|
to EMC's other lines we find Isilion is nothing more than a big pile of
|
||||||
|
Supermicro servers running (IIRC) FreeBSD.
|
||||||
|
|
||||||
|
Netapp's famed FAS range similarly runs on commodity hardware, OnTAP is
|
||||||
|
[BSD](https://en.wikipedia.org/wiki/NetApp_filer) based.
|
||||||
|
|
||||||
|
The list goes on, Dell Compellent? When I looked at it in early 2012, it
|
||||||
|
was still running on Supermicro dual Xeons. The plan was to move it to
|
||||||
|
Dell R-series servers as soon as possible. They were doing validation at
|
||||||
|
the time, I suspect the move is complete now. Reading between the lines,
|
||||||
|
I came away with the impression that it runs on FreeBSD, but I do not
|
||||||
|
know for sure. CoRAID use Supermicro servers, they unusually run Plan9
|
||||||
|
as their OS. HP StoreVirtual (formerly Lefthand) runs on Proliant Gen8
|
||||||
|
servers or VMware. In all these cases, there is no extra hardware
|
||||||
|
involved.
|
||||||
|
|
||||||
|
The people that write the MD stack in the Linux
|
||||||
|
kernel are not cowboys. It has proved over and over again that is
|
||||||
|
both stable and fast. I have trusted some of the most important data
|
||||||
|
under my care to their software: for many years the ERP system at
|
||||||
|
[Snell](https://www.snellgroup.com) has been running on MD devices quite
|
||||||
|
happily. We found it much faster than the P410 cards in the DL360G5
|
||||||
|
servers that host it. Additionally, you do not need to load in any funky
|
||||||
|
modules or utilities - everything you need to manage the devices is
|
||||||
|
there in the distribution.
|
||||||
|
|
||||||
|
ZFS also recommends to bypass any RAID devices and let it do everything
|
||||||
|
in software, as does Btrfs. With *Storage Spaces* in Server 2012
|
||||||
|
Microsoft is definitely angling towards software controlled storage as
|
||||||
|
well.
|
||||||
|
|
||||||
|
As with everything in IT, hardware is falling by the wayside in storage.
|
||||||
|
Modern processors can do the processing so fast that there is no
|
||||||
|
performance need for hardware in between your OS and the disks any more.
|
||||||
|
The OS layers (Storage Spaces on Windows and especially MD/LVM on Linux)
|
||||||
|
are so mature now that their reliability can be taken as a given. With
|
||||||
|
the management advantages, there really is no technical reason to stick
|
||||||
|
with hardware RAID. In fact the closer you can get the raw disks to your
|
||||||
|
OS the better.
|
||||||
|
|
||||||
|
As I said at the start, the subject here is software vs
|
||||||
|
hardware RAID, but my problem goes deeper than that particular argument.
|
||||||
|
As technology professionals, we are technical people. We need to
|
||||||
|
understand what is going on under the bonnet - that is our job! It may
|
||||||
|
be fine for a vendor to pull the wool over a CFO's eyes, but we
|
||||||
|
need to know what is inside that magic black box, especially when it is
|
||||||
|
in the spec sheet.
|
||||||
415
content/blog/super-slick-agile-puppet-for-devops/index.md
Normal file
|
|
@ -0,0 +1,415 @@
|
||||||
|
---
|
||||||
|
date: 2014-06-25
|
||||||
|
title: Super Slick Agile Puppet for Devops
|
||||||
|
category: devops
|
||||||
|
featured_image: https://i.imgur.com/3SJXbMb.jpg
|
||||||
|
---
|
||||||
|
|
||||||
|
With a superb buzzword laden title like that, then I reckon massive
|
||||||
|
traffic boost is inevitable.
|
||||||
|
|
||||||
|
Puppet is my favourite Configuration Management tool. This is not a post
|
||||||
|
to try and persuade anyone not to use Ansible, Chef or any other. What I
|
||||||
|
want to do is show I build Puppet based infrastuctures in such away that
|
||||||
|
it meets all the basic tenets of DevOps/Agile/buzzword-of-the-month.
|
||||||
|
|
||||||
|
<!-- more -->
|
||||||
|
What to we need:
|
||||||
|
|
||||||
|
- CentOS 6 - RHEL/CentOS is pretty much the defacto enterprise distro.
|
||||||
|
This will easily translate to Debian/Ubuntu or anything else.
|
||||||
|
- Puppet 3 - I like a traditional Master/Agent set up, if you prefer
|
||||||
|
master-less good for you. This is my blog, my rules.
|
||||||
|
- Git
|
||||||
|
- Dynamic Environments
|
||||||
|
- PuppetDB
|
||||||
|
- Hiera
|
||||||
|
- Jenkins
|
||||||
|
|
||||||
|
All the config is stored in Git, with Jenkins watching it.
|
||||||
|
|
||||||
|
Puppet tends to fall apart pretty quickly if you do not have DNS in
|
||||||
|
place. You can start using host files, but that will get old quickly.
|
||||||
|
Ideally, the first thing you will do with Puppet is install a DNS server
|
||||||
|
managed by Puppet. Maybe that will be the next post.
|
||||||
|
|
||||||
|
# Puppet
|
||||||
|
|
||||||
|
Starting with a base Centos 6 install, the installation is very easy:
|
||||||
|
|
||||||
|
yum -y install https://yum.puppetlabs.com/puppetlabs-release-el-6.noarch.rpm
|
||||||
|
yum -y install puppet puppet-server rubygem-activerecord
|
||||||
|
|
||||||
|
Our environments need a place to go, so create that:
|
||||||
|
|
||||||
|
mkdir /etc/puppet/environments
|
||||||
|
chgrp puppet /etc/puppet/environments
|
||||||
|
chmod 2775 /etc/puppet/environments
|
||||||
|
|
||||||
|
The configuration will look like:
|
||||||
|
|
||||||
|
[main]
|
||||||
|
logdir = /var/log/puppet
|
||||||
|
rundir = /var/run/puppet
|
||||||
|
ssldir = $vardir/ssl
|
||||||
|
trusted_node_data = true
|
||||||
|
pluginsync = true
|
||||||
|
|
||||||
|
[agent]
|
||||||
|
classfile = $vardir/classes.txt
|
||||||
|
localconfig = $vardir/localconfig
|
||||||
|
report = true
|
||||||
|
environment = production
|
||||||
|
ca_server = puppet.chriscowley.lan
|
||||||
|
server = puppet.chriscowley.lan
|
||||||
|
|
||||||
|
[master]
|
||||||
|
environmentpath = $confdir/environments
|
||||||
|
# Passenger
|
||||||
|
ssl_client_header = SSL_CLIENT_S_DN
|
||||||
|
ssl_client_verify_header = SSL_CLIENT_VERIFY
|
||||||
|
|
||||||
|
Do not use the Puppetmaster service. It uses Webrick, which is bad. Any
|
||||||
|
more than 5 agents and it will start slowing down. Puppet is a RoR app,
|
||||||
|
so stick it behind
|
||||||
|
[Apache/Passenger](https://docs.puppetlabs.com/guides/passenger.html).
|
||||||
|
We installed the `puppet-server` package for a simple reason: when you
|
||||||
|
start it the first time, it will create your SSL certificates
|
||||||
|
automatically. After that initial start you can stop it and forget it
|
||||||
|
ever existed. So just run:
|
||||||
|
|
||||||
|
service puppetmaster start
|
||||||
|
service puppetmaster stop
|
||||||
|
|
||||||
|
Unfortunately, you will need to put SELinux into Permissive mode
|
||||||
|
temporarily. Once you have fired it up you can [build a local
|
||||||
|
policy](https://wiki.centos.org/HowTos/SELinux#head-faa96b3fdd922004cdb988c1989e56191c257c01)
|
||||||
|
and re-enable it.
|
||||||
|
|
||||||
|
yum install httpd httpd-devel mod_ssl ruby-devel rubygems gcc gcc-c++ curl-devel openssl-devel zlib-devel
|
||||||
|
gem install rack passenger
|
||||||
|
passenger-install-apache2-module
|
||||||
|
|
||||||
|
Next you need to configure Apache to serve up the RoR app.
|
||||||
|
|
||||||
|
mkdir -p /usr/share/puppet/rack/puppetmasterd
|
||||||
|
mkdir /usr/share/puppet/rack/puppetmasterd/public /usr/share/puppet/rack/puppetmasterd/tmp
|
||||||
|
cp /usr/share/puppet/ext/rack/config.ru /usr/share/puppet/rack/puppetmasterd/
|
||||||
|
chown puppet:puppet /usr/share/puppet/rack/puppetmasterd/config.ru
|
||||||
|
https://gist.githubusercontent.com/chriscowley/00e75ee021ce314fab1e/raw/c87abc38182eafc6d22a80d13078ac044fdde49f/puppetmaster.conf | sed 's/puppet-server.example.com/puppet.yourlan.lan/g'
|
||||||
|
|
||||||
|
You will need to modify the `sed` command in the last line to match your
|
||||||
|
environment.
|
||||||
|
|
||||||
|
You may also need to change the Passenger paths to match what the output
|
||||||
|
of `passenger-install-apache2-module` told you. It is up to date as of
|
||||||
|
the time of writing.
|
||||||
|
|
||||||
|
# Hiera
|
||||||
|
|
||||||
|
Your config file (`/etc/puppet/hiera.yaml`) will already be created,
|
||||||
|
mine looks like this:
|
||||||
|
|
||||||
|
---
|
||||||
|
:backends:
|
||||||
|
- yaml
|
||||||
|
:hierarchy:
|
||||||
|
- defaults
|
||||||
|
- "nodes/%{clientcert}"
|
||||||
|
- "virtual/%{::virtual}"
|
||||||
|
- "%{environment}"
|
||||||
|
- "%{::osfamily}"
|
||||||
|
- global
|
||||||
|
|
||||||
|
:yaml:
|
||||||
|
:datadir: "/etc/puppet/environments/%{::environment}/hieradata"
|
||||||
|
|
||||||
|
There is also an `/etc/hiera.yaml` which Puppet does not use. change
|
||||||
|
this to a symbolic link to avoid confusion.
|
||||||
|
|
||||||
|
ln -svf /etc/puppet/hiera.yaml /etc/hiera.yaml
|
||||||
|
|
||||||
|
If you were to test it now, you will see a few errors:
|
||||||
|
|
||||||
|
Info: Retrieving pluginfacts
|
||||||
|
Error: /File[/var/lib/puppet/facts.d]: Could not evaluate: Could not retrieve information from environment production source(s) puppet://puppet/pluginfacts
|
||||||
|
Info: Retrieving plugin
|
||||||
|
Error: /File[/var/lib/puppet/lib]: Could not evaluate: Could not retrieve information from environment production source(s) puppet://puppet/plugins
|
||||||
|
|
||||||
|
Don\'t worry about that for now, the important thing is that the agent
|
||||||
|
connects to the master. If that happens the master does return an HTTP
|
||||||
|
error, then you are good.
|
||||||
|
|
||||||
|
# R10k
|
||||||
|
|
||||||
|
This is the tool I use to manage my modules. It can pull them off the
|
||||||
|
Forge, or from wherever you tell it too. Most often that will be Github,
|
||||||
|
or an internal Git repo if that\'s what you use.
|
||||||
|
|
||||||
|
You need to install it from Ruby Gems, then there is a little
|
||||||
|
configuration to do.
|
||||||
|
|
||||||
|
:
|
||||||
|
|
||||||
|
gem install r10k
|
||||||
|
mkdir /var/cache/r10k
|
||||||
|
chgrp puppet /var/cache/r10k
|
||||||
|
chmod 2775 /var/cache/r10k
|
||||||
|
|
||||||
|
The file `/etc/r10k.yaml` should contain:
|
||||||
|
|
||||||
|
# location for cached repos
|
||||||
|
:cachedir: '/var/cache/r10k'
|
||||||
|
|
||||||
|
# git repositories containing environments
|
||||||
|
:sources:
|
||||||
|
:base:
|
||||||
|
remote: '/srv/puppet.git'
|
||||||
|
basedir: '/etc/puppet/environments'
|
||||||
|
|
||||||
|
# purge non-existing environments found here
|
||||||
|
:purgedirs:
|
||||||
|
- '/etc/puppet/environments'
|
||||||
|
|
||||||
|
# Git
|
||||||
|
|
||||||
|
The core of your this process is the ubiquitous Git.
|
||||||
|
|
||||||
|
yum install git
|
||||||
|
|
||||||
|
You need a Git repo to store everything, and also launch a deploy script
|
||||||
|
when you push to it. To start with we\'ll put it on the Puppet server.
|
||||||
|
In the future I would put this on a dedicated machine, have Jenkins run
|
||||||
|
tests, then run the deploy script on success.
|
||||||
|
|
||||||
|
However, it is not a standard repository, so you cannot just run
|
||||||
|
`git init`. It needs:
|
||||||
|
|
||||||
|
- To be **bare**
|
||||||
|
- To be **shared**
|
||||||
|
- Have the **master** branch renamed to **production**
|
||||||
|
|
||||||
|
<!-- -->
|
||||||
|
|
||||||
|
mkdir -pv /srv/puppet.git
|
||||||
|
git init --bare --shared=group /srv/puppet.git
|
||||||
|
chgrp -R puppet /srv/puppet.git
|
||||||
|
cd /srv/puppet.git
|
||||||
|
git symbolic-ref HEAD refs/heads/production
|
||||||
|
|
||||||
|
Continuing to work as root is not acceptable, so create user (if you do
|
||||||
|
not already have one).
|
||||||
|
|
||||||
|
useradd <username>
|
||||||
|
usermod -G wheel,puppet <username>
|
||||||
|
visudo
|
||||||
|
|
||||||
|
Uncomment the line that reads:
|
||||||
|
|
||||||
|
%wheel ALL=(ALL) ALL
|
||||||
|
|
||||||
|
This gives your user full `sudo` privileges.
|
||||||
|
|
||||||
|
# Deploy script
|
||||||
|
|
||||||
|
This is what does the magic stuff. It needs to be
|
||||||
|
`/srv/puppet.git/hooks/post-receive` so that it runs when you push
|
||||||
|
something to this repository.
|
||||||
|
|
||||||
|
#!/bin/bash
|
||||||
|
|
||||||
|
umask 0002
|
||||||
|
|
||||||
|
while read oldrev newrev ref
|
||||||
|
do
|
||||||
|
branch=$(echo $ref | cut -d/ -f3)
|
||||||
|
echo
|
||||||
|
echo "--> Deploying ${branch}..."
|
||||||
|
echo
|
||||||
|
r10k deploy environment $branch -p
|
||||||
|
# sometimes r10k gets permissions wrong too
|
||||||
|
find /etc/puppet/environments/$branch/modules -type d -exec chmod 2775 {} \; 2> /dev/null
|
||||||
|
find /etc/puppet/environments/$branch/modules -type f -exec chmod 664 {} \; 2> /dev/null
|
||||||
|
done
|
||||||
|
|
||||||
|
Run `chmod 0775 /srv/puppet.git/hooks/post-receive` to make is
|
||||||
|
executable and writable by anyone in the `puppet` group.
|
||||||
|
|
||||||
|
# The first environment
|
||||||
|
|
||||||
|
Switch to your user
|
||||||
|
|
||||||
|
su - <username>
|
||||||
|
|
||||||
|
Clone the repository and create the necessary folder structure:
|
||||||
|
|
||||||
|
git clone /srv/puppet.git
|
||||||
|
cd puppet
|
||||||
|
mkdir -pv hieradata/nodes manifests site
|
||||||
|
|
||||||
|
Now you can create `PuppetFile` in the root of that repository. This is
|
||||||
|
what tells R10k what modules to deploy.
|
||||||
|
|
||||||
|
# Puppet Forge
|
||||||
|
mod 'puppetlabs/ntp', '3.0.0-rc1'
|
||||||
|
mod 'puppetlabs/puppetdb', '3.0.1'
|
||||||
|
mod 'puppetlabs/stdlib', '3.2.1'
|
||||||
|
mod 'puppetlabs/concat', '1.0.0'
|
||||||
|
mod 'puppetlabs/inifile', '1.0.3'
|
||||||
|
mod 'puppetlabs/postgresql', '3.3.3'
|
||||||
|
mod 'puppetlabs/firewall', '1.0.2'
|
||||||
|
mod 'chriscowley/yumrepos', '0.0.2'
|
||||||
|
|
||||||
|
# Get a module from Github
|
||||||
|
#mod 'custom',
|
||||||
|
# :git => 'https://github.com/chriscowley/puppet-pydio.git',
|
||||||
|
# :ref => 'master'
|
||||||
|
|
||||||
|
A common error I make if I am not looking properly is to put the SSH URL
|
||||||
|
from Github in there. This will not work unless you have added your SSH
|
||||||
|
key on the Puppet server. Better just to put the HTTPS URL in there,
|
||||||
|
there is need to write back to it after all.
|
||||||
|
|
||||||
|
Next you need to tell Puppet what agents should get what. To begin with,
|
||||||
|
everything will get NTP, but only the Puppetmaster will get PuppetDB. To
|
||||||
|
that end create `hieradata/common.yaml` with this:
|
||||||
|
|
||||||
|
---
|
||||||
|
classes:
|
||||||
|
- ntp
|
||||||
|
|
||||||
|
ntp::servers:
|
||||||
|
- 0.pool.ntp.org
|
||||||
|
- 1.pool.ntp.org
|
||||||
|
- 2.pool.ntp.org
|
||||||
|
- 3.pool.ntp.org
|
||||||
|
|
||||||
|
Next create `hieradata/nodes/$(hostname -s).yaml` with:
|
||||||
|
|
||||||
|
---
|
||||||
|
classes:
|
||||||
|
- puppetdb
|
||||||
|
- puppetdb::master::config
|
||||||
|
|
||||||
|
Finally, you need to tell Puppet to get the data from Hiera. Create
|
||||||
|
`manifests.site.pp` with
|
||||||
|
|
||||||
|
hiera_include('classes')
|
||||||
|
|
||||||
|
You should need nothing else.
|
||||||
|
|
||||||
|
Now you can push it to the master repository.
|
||||||
|
|
||||||
|
git add .
|
||||||
|
git commit -a -m "Initial commit"
|
||||||
|
git branch -m production
|
||||||
|
git push origin production
|
||||||
|
|
||||||
|
# Testing
|
||||||
|
|
||||||
|
Of course, the whole point of all this is that we do as much testing as
|
||||||
|
we can before any sort of deploy. We also want to keep our Git
|
||||||
|
repository nice clean (especially if you push it to Github), so if we
|
||||||
|
can avoid commits with stupid errors that would be great.
|
||||||
|
|
||||||
|
To perform your testing you need to replicate your production
|
||||||
|
environment. From now on, I\'m going to assume that you are working on
|
||||||
|
your own workstation.
|
||||||
|
|
||||||
|
Clone your repository:
|
||||||
|
|
||||||
|
git clone ssh://<username>@puppet.example.com/srv/puppet.git
|
||||||
|
cd puppet
|
||||||
|
|
||||||
|
To perform all the testing, [RVM](https://rvm.io/) is your friend. This
|
||||||
|
allows you to replicate the ruby environment on the master, have all the
|
||||||
|
necessary gems installed in a contained environment and sets you up to
|
||||||
|
integrate with Jenkins later. Install is with:
|
||||||
|
|
||||||
|
curl -sSL https://get.rvm.io | bash -s stable
|
||||||
|
|
||||||
|
Follow any instructions it gives your, then you can create your
|
||||||
|
environment. This will be using a old version of ruby as we are running
|
||||||
|
CentOS 6 on the master.
|
||||||
|
|
||||||
|
rvm install ruby-1.8.7
|
||||||
|
rvm use ruby-1.8.7
|
||||||
|
rvm gemset create puppet
|
||||||
|
rvm gemset use puppet
|
||||||
|
rvm --create use ruby-1.8.7-head@puppet --rvmrc
|
||||||
|
|
||||||
|
Create a Gemfile that contains:
|
||||||
|
|
||||||
|
source 'https://rubygems.org'
|
||||||
|
|
||||||
|
gem 'puppet-lint', '0.3.2'
|
||||||
|
gem 'puppet', '3.6.2'
|
||||||
|
gem 'kwalify', '0.7.2'
|
||||||
|
|
||||||
|
Now you can install the gems with `bundle install`.
|
||||||
|
|
||||||
|
The tests will be run by a pre-commit hook script, that looks something
|
||||||
|
like:
|
||||||
|
|
||||||
|
#!/bin/bash
|
||||||
|
# pre-commit git hook to check the validity of a puppet main manifest
|
||||||
|
#
|
||||||
|
# Prerequisites:
|
||||||
|
# gem install puppet-lint puppet
|
||||||
|
#
|
||||||
|
# Install:
|
||||||
|
# /path/to/repo/.git/hooks/pre-commit
|
||||||
|
#
|
||||||
|
# Authors:
|
||||||
|
# Chris Cowley <chris@chriscowley.me.uk>
|
||||||
|
|
||||||
|
echo "Checking style"
|
||||||
|
for file in `git diff --name-only --cached | grep -E '\.(pp)'`; do
|
||||||
|
puppet-lint ${file}
|
||||||
|
if [ $? -ne 0 ]; then
|
||||||
|
style_bad=1
|
||||||
|
else
|
||||||
|
echo "Style looks good"
|
||||||
|
fi
|
||||||
|
done
|
||||||
|
|
||||||
|
echo "Checking syntax"
|
||||||
|
for file in `git diff --name-only --cached | grep -E '\.(pp)'`; do
|
||||||
|
puppet parser validate $file
|
||||||
|
if [ $? -ne 0 ]; then
|
||||||
|
syntax_bad=1
|
||||||
|
echo "Syntax error in ${file}"
|
||||||
|
else
|
||||||
|
echo "Syntax looks good"
|
||||||
|
fi
|
||||||
|
done
|
||||||
|
|
||||||
|
for file in `git diff --name-only --cached | grep -E '\.(yaml)'`; do
|
||||||
|
echo "Checking YAML is valid"
|
||||||
|
ruby -e "require 'yaml'; YAML.parse(File.open('$file'))"
|
||||||
|
if [ $? -ne 0 ]; then
|
||||||
|
yaml_bad=1
|
||||||
|
else
|
||||||
|
echo "YAML looks good"
|
||||||
|
fi
|
||||||
|
done
|
||||||
|
|
||||||
|
if [ ${yaml_bad} ];then
|
||||||
|
exit 1
|
||||||
|
elif [ ${syntax_bad} ]; then
|
||||||
|
exit 1
|
||||||
|
elif [ ${style_bad} ]; then
|
||||||
|
exit 1
|
||||||
|
else
|
||||||
|
exit 0
|
||||||
|
fi
|
||||||
|
|
||||||
|
This should set you up very nicely. Your environments are completely
|
||||||
|
dynamic, you have a framework in place for testing.
|
||||||
|
|
||||||
|
For now the deployment is with a hook script, but that is not the
|
||||||
|
ultimate goal. This Git repo needs to be on the Puppet master. You may
|
||||||
|
well already have a Git server you want to use. TO this end, in a later
|
||||||
|
post I will be add Jenkins into the mix. As you are running the tests in
|
||||||
|
an RVM environment, it will be very easy to put into Jenkins. This can
|
||||||
|
then perform the deployment.
|
||||||
98
content/blog/the-end-of-centralised-storage/index.md
Normal file
|
|
@ -0,0 +1,98 @@
|
||||||
|
---
|
||||||
|
date: 2013-09-12
|
||||||
|
title: The End of Centralised Storage
|
||||||
|
category: Opinions
|
||||||
|
---
|
||||||
|
|
||||||
|
{% img right /images/NetappClustering.jpg %}That is a pretty drastic
|
||||||
|
title, especially given that I spend a significant part of my day job
|
||||||
|
working with EMC storage arrays. The other day I replied to a tweet by
|
||||||
|
[Scott Lowe](https://blog.scottlowe.org) :
|
||||||
|
|
||||||
|
<blockquote class="twitter-tweet"><p>
|
||||||
|
\@scott\_lowe with things like Gluster and Ceph what does shared storage
|
||||||
|
actually give apart from complications?
|
||||||
|
|
||||||
|
</p>
|
||||||
|
--- Chris Cowley (\@chriscowleyunix) September 11, 2013
|
||||||
|
|
||||||
|
</blockquote>
|
||||||
|
<script async src="//platform.twitter.com/widgets.js" charset="utf-8"></script>
|
||||||
|
<!-- more -->
|
||||||
|
Due to time-zone differences between France and the USA I missed out on
|
||||||
|
most of the heated conversation that ensued. From what I could see it
|
||||||
|
quickly got out of hand, with people replying to so many others that
|
||||||
|
they barely had any space to say anything. I am sure it has spawned a
|
||||||
|
load of blog posts, as Twitter is eminently unsuitable for that sort of
|
||||||
|
conversation (at least I have seen one by
|
||||||
|
[StorageZilla](https://storagezilla.typepad.com/storagezilla/2013/09/tomorrows-das-yesterday.html).
|
||||||
|
|
||||||
|
The boundary between DAS (Direct Attached Storage) and remote storage
|
||||||
|
(be that a SAN or NAS) is blurring. Traditionally a SAN/NAS array is a
|
||||||
|
proprietary box that gives you bits of disk space that is available to
|
||||||
|
whatever server (or servers) that you want. Conversely, DAS is attached
|
||||||
|
either inside the server or to the back of it. Sharing between multiple
|
||||||
|
servers is possible, but not very slick - no switched fabric, no
|
||||||
|
software configuration, cables have to be physically moved.
|
||||||
|
|
||||||
|
Now everything is blurring. In the FLOSS world there is the like of Ceph
|
||||||
|
and GlusterFS, which take your DAS (or whatever) and turn that into a
|
||||||
|
shared pool of storage. You can put this on dedicated boxes, depending
|
||||||
|
on your workload that may well be the best idea. However you are not
|
||||||
|
forced to. To my mind this is a more elegant solution. I have a
|
||||||
|
collection of identical servers, I use some for compute, other for
|
||||||
|
storage, others for both. You can pick and choose, even doing it live.
|
||||||
|
|
||||||
|
The thing is, even the array vendors are now using DAS. An EMC VNX is
|
||||||
|
commodity hardware, as is the VMAX (mostly, I believe there is an ASIC
|
||||||
|
used in the encryption engine), Isilion, NetApp, Dell Compellent, HP
|
||||||
|
StoreVirtual (formerly Lefthand). What is the difference in the way they
|
||||||
|
attach their disks? Technically none I suppose, it is just hidden away.
|
||||||
|
|
||||||
|
Back to the cloud providers, when you provision a VM there is a process
|
||||||
|
that happens (I am considering Openstack, as that is my area of
|
||||||
|
interest/expertise). You provision an instance and it takes the template
|
||||||
|
you select and copies it to the local storage on that host. Yes you can
|
||||||
|
short-circuit that and use shared storage, but that is unnecessarily
|
||||||
|
complex and introduces a potential failure point. OK, the disk in the
|
||||||
|
host could fail, but then so would the host and it would just go to a
|
||||||
|
new host.
|
||||||
|
|
||||||
|
With Openstack, you can use either Ceph or GlusterFS for your block
|
||||||
|
storage (amongst others). When you create block storage for your
|
||||||
|
instance it is created in that pool and replicated. Again, these will in
|
||||||
|
most cases be distributing and replicating local storage. I have known
|
||||||
|
people use SAN arrays as the back-end for Ceph, but that was because
|
||||||
|
they already had them lying around.
|
||||||
|
|
||||||
|
There have been various products around for a while to share out your
|
||||||
|
local storage on VMware hosts. VMware\'s own VSA, HP StoreVirtual and
|
||||||
|
now Virtual SAN takes this even deeper, giving tiering and tying
|
||||||
|
directly into the host rather than using a VSA. It certainly seems that
|
||||||
|
DAS is the way forward (or a hybrid approach such as PernixData FVP).
|
||||||
|
This makes a huge amount of sense, especially in the brave new world of
|
||||||
|
SSDs. The latencies involved in spinning rust effective masked those of
|
||||||
|
the storage fabric. Now though SSDs are so fast, that the time it takes
|
||||||
|
for a storage object to transverse the SAN becomes a factor. Getting at
|
||||||
|
least the performance storage layer as physically close to the computer
|
||||||
|
layer as possible is now a serious consideration.
|
||||||
|
|
||||||
|
Hadoop, the darling of the Big Data lovers, uses HDFS, which also
|
||||||
|
distributes and replicates your data across local storage. GlusterFS can
|
||||||
|
also be used too. You can use EMC arrays, but I do not hear much about
|
||||||
|
that (other than from EMC themselves). The vast majority of Hadoop users
|
||||||
|
seem to be on local storage/HDFS. On a similar note Lustre, very popular
|
||||||
|
in the HPC world, is also designed around local storage.
|
||||||
|
|
||||||
|
{% pullquote %} So what am I getting at here? To be honest I am not
|
||||||
|
sure, but I can see a general move away from centralised storage. Even
|
||||||
|
EMC noticed this ages ago - they were talking about running the
|
||||||
|
hypervisor on the VNX/VMAX. At least that is how I remember it anyway, I
|
||||||
|
may well be wrong (if I am, then it is written on the internet now, so
|
||||||
|
it must be true). Red Hat own GlusterFS and are pushing it centre stage
|
||||||
|
for Openstack, Ceph is also an excellent solution and has the weight of
|
||||||
|
Mark Shuttleworth and Canonical behind it. VMware have been pushing
|
||||||
|
Virtual SAN hard and it seems to have got a lot of people really
|
||||||
|
excited. {\" I just do not see anything really exciting in centralised
|
||||||
|
storage\"}, everything interesting is based around DAS. {% endpullquote
|
||||||
|
%}
|
||||||
72
content/blog/the-linux-to-storage/index.md
Normal file
|
|
@ -0,0 +1,72 @@
|
||||||
|
---
|
||||||
|
date: 2013-02-25
|
||||||
|
title: The Linux to Storage
|
||||||
|
category: Opinions
|
||||||
|
---
|
||||||
|
|
||||||
|
Martin "Storagebod" Glassborow recently wrote an interesting article
|
||||||
|
where he asked "Who'll do a Linux to Storage?". As someone who is
|
||||||
|
equal parts Storage and Linux, the same question runs around my head
|
||||||
|
quite often. Not just that, but how to do it. It is safe to say that all
|
||||||
|
the constituent parts are already in the Open Source Ecosystem. It just
|
||||||
|
needs someone to pull them all together wrap them up in an integrated
|
||||||
|
interface (be that a GUI, CLI, an API or all).
|
||||||
|
|
||||||
|
Linux, obviously, has excellent NFS support. Until recently it was a
|
||||||
|
little lacking in terms of block support. [iSCSI Enterprise
|
||||||
|
Target](https://sourceforge.net/projects/iscsitarget/) is ok, but is not
|
||||||
|
packaged for RHEL, which for most shops makes it a big no-no. Likewise
|
||||||
|
[TGT](https://stgt.sourceforge.net/) is not bad, I have certainly used
|
||||||
|
it to to good effect, but administering it is a bit like pulling teeth.
|
||||||
|
Additionally, neither are VMware certified and I am pretty sure that TGT
|
||||||
|
at least is missing a required feature for certification as well (may be
|
||||||
|
persistent reservations). There is a third SCSI target in Linux though:
|
||||||
|
[LIO Kernel Target](https://www.linux-iscsi.org/) by Rising Tide
|
||||||
|
Systems. This is a lot newer, but is already VMware Ready certified. Red
|
||||||
|
Hat used it in RHEL6 for FCoE target support, but not for iSCSI. in
|
||||||
|
RHEL7 they will be [using it for all block
|
||||||
|
storage](https://groveronline.com/2012/11/tgtd-lio-in-rhel-7/). It has a
|
||||||
|
much nicer interface than the other targets on Linux, using a very
|
||||||
|
intuitive CLI, nice JSON config files and a rather handy API. Rising
|
||||||
|
Tide are a bit of an unknown however, or at least I thought so. It turns
|
||||||
|
our that both QNAP and Netgear use LIO Kernel Target in their larger
|
||||||
|
devices - hence the VMware certification. In any case, Red Hat are
|
||||||
|
behind it, although I think they are working on a fork of at least the
|
||||||
|
CLI, so I think success is assured there. That solves the problem of
|
||||||
|
block storage, be it iSCSI, Fibre-Channel, FCoE, Infiniband or even USB.
|
||||||
|
|
||||||
|
Another important building block in an enterprise storage system is some
|
||||||
|
way of distributing the data for both redunancy and performance. Marin
|
||||||
|
mentions [Ceph](https://ceph.com/) which is an excellent system.
|
||||||
|
Personally I would put my money on [GlusterFS](https://www.gluster.org/)
|
||||||
|
though. I have had slightly better performance from it. Red Hat bought
|
||||||
|
Gluster about a year ago, and have put some serious development effort
|
||||||
|
into it. As well as POSIX access via Fuse, it has Object storage for use
|
||||||
|
with OpenStack, a native Qemu connector is coming in the next versions.
|
||||||
|
Hadoop can also access it directly. There is also a very good Puppet
|
||||||
|
module for it, which gets around one of Martin's critisms of Ceph.
|
||||||
|
|
||||||
|
Which brings me nicely to managing this theoretical system. Embedding
|
||||||
|
Puppet in this sort of solution would also make sense. There will be
|
||||||
|
need to a way of keep config sync'ed on all the nodes (I mentioned that
|
||||||
|
this disruptive product will be scale-out didn't I? NO? OK, it will be
|
||||||
|
-prediction for the day). Puppet does this already very well, so why
|
||||||
|
re-invent the wheel.
|
||||||
|
|
||||||
|
All this can sit on top of Btrfs allowing each node to have up to 16
|
||||||
|
exabytes of local storage. For now I am not convinced by it, at least on
|
||||||
|
RHEL 6 as I have seen numerous kernel panics, nor did I have a huge
|
||||||
|
amount of joy on Fedora 17, but there is no doubt that it will get
|
||||||
|
there. Alternatively, there is always the combination of XFS and LVM.
|
||||||
|
XFS is getting on a bit now, but it has been revived by Red Hat in
|
||||||
|
recent years and it is a proven performer with plenty of life left in it
|
||||||
|
yet.
|
||||||
|
|
||||||
|
After all that, who do I think is ripe to do some serious disrupting in
|
||||||
|
the storage market? Who will "Do a Red Hat" as Martin puts it? Simple:
|
||||||
|
it will be Red Hat! Look at the best of breed tools at every level of
|
||||||
|
the storage stack on Linux and you will find it is either from Red Hat
|
||||||
|
(Gluster) or they are heavily involved (LIO target). They have the
|
||||||
|
resources and the market/mind share to do it. Also they have a long
|
||||||
|
history of working with and feeding back to the community, so the
|
||||||
|
fortuitous circle will continue.
|
||||||
83
content/blog/thoughts-on-the-shiney-new-vmax/index.md
Normal file
|
|
@ -0,0 +1,83 @@
|
||||||
|
---
|
||||||
|
date: 2013-03-01
|
||||||
|
title: Thoughts on the shiney new VMAX
|
||||||
|
category: Opinions
|
||||||
|
---
|
||||||
|
|
||||||
|
{% img right
|
||||||
|
[https://www.emc.com/R1/images/EMC\\\_Image\\\_C\\\_1310593327367\\\_header-image-vmax-10k.png](https://www.emc.com/R1/images/EMC\_Image\_C\_1310593327367\_header-image-vmax-10k.png)
|
||||||
|
%} I've spent a significant amount of time recently swatting up on
|
||||||
|
EMC's new [VMAX Cloud
|
||||||
|
Edition](https://chucksblog.emc.com/chucks_blog/2013/02/introducing-vmax-cloud-edition.html).
|
||||||
|
It has to be said that this looks like one of the most interesting
|
||||||
|
storage announcements I have seen in a long time. In fact I have a
|
||||||
|
project coming up that I think it may well be a perfect fit for.
|
||||||
|
|
||||||
|
First a massive thanks to EMC's Matthew Yeager (\@mpyeager) who
|
||||||
|
answered a couple of questions I had. He really went the extra mile to
|
||||||
|
clarify a couple of things and the
|
||||||
|
[video](https://www.youtube.com/watch?v=WoElTAevLDs) he made is well
|
||||||
|
worth a watch. Also Martin Glassborow (\@storagebod) has [interesting
|
||||||
|
things to say](https://www.storagebod.com/wordpress/?p=1293) as well.
|
||||||
|
|
||||||
|
This is a product that could put a lot of people out of a job. If you
|
||||||
|
are the sort of person who likes to keep hold of your little castle's
|
||||||
|
of knowledge then you will not like this from what I can see. Finally we
|
||||||
|
are able to be truly customer focused, balancing cost, performance and
|
||||||
|
capacity to give them exactly what they want. EMC claim this is a world
|
||||||
|
first and to my knowledge they are right.
|
||||||
|
|
||||||
|
{% pullquote %} Storage architects put a lot of time and effort in to
|
||||||
|
tweaking quotes and systems to balance price, capacity and performance
|
||||||
|
for a given work load. However, most of this is just reading up on the
|
||||||
|
best-practises for a given array and situation and applying them. There
|
||||||
|
is nothing that clever to it - reading and practise is what it comes
|
||||||
|
down to. However, it has alway been as much an art as a science because
|
||||||
|
an individual architect does not have a very large dataset to refer to.
|
||||||
|
On the other hand EMC have got 60 million hours of metrics across more
|
||||||
|
than 7000 VMAX systems out in the field. {" With that amount of data
|
||||||
|
the amount of art involved diminishes "} and it becomes purely a
|
||||||
|
science. {% endpullquote %}
|
||||||
|
|
||||||
|
What you get is a [VMAX
|
||||||
|
10k](https://www.emc.com/storage/symmetrix-vmax/vmax-10k.htm), but
|
||||||
|
instead of defining storage pools, tiering policies, RAID levels etc you
|
||||||
|
balance 3 facters: Space, performance and cost. Need a certain
|
||||||
|
performance level for a certain amount of space no matter the cost? Just
|
||||||
|
dial it in and mail EMC a cheque. Have a certain budget, need a certain
|
||||||
|
amount of space, but performance not a problem? Same again.
|
||||||
|
|
||||||
|
No longer will we be carefully balancing the number of SATA and FC
|
||||||
|
spindles and the types of RAID level. No longer will be worrying about
|
||||||
|
what percentage of our workload we need to keep on the SSD layer to
|
||||||
|
assure the necessary number of IOPS. We will not even be calculating how
|
||||||
|
much space we have after the RAID overheads.
|
||||||
|
|
||||||
|
{% pullquote %} That is all very interesting, but so far it is just a
|
||||||
|
new approach to the UI. It is an excellent approach, but nothing
|
||||||
|
especially clever. One of things I gravitated towards was the white
|
||||||
|
paper about integrating with
|
||||||
|
[vCloud](https://www.emc.com/collateral/white-papers/h11468-vmax-cloud-edition-wp.pdf).
|
||||||
|
Despite it being geared toward VMware (I wonder why? - not!) the
|
||||||
|
principles equally apply to any situation where automation is required.
|
||||||
|
I am a huge DevOps fan (Puppet in particular). Storage arrays have never
|
||||||
|
been particularly automation friendly. In addition to the cloud portal,
|
||||||
|
the VMAX CE also has a RESTful API. Now that is awesome! {" Here we
|
||||||
|
have the abilty to easily integrate a VMAX with the likes of OpenStack
|
||||||
|
Cinder, Puppet, Libvirt, or whatever "} you want. {% endpullquote %}
|
||||||
|
|
||||||
|
Finally [Chad Sakac](https://virtualgeek.typepad.com) informs me that
|
||||||
|
VMAX CE is just the first. EMC intend to roll this management style out
|
||||||
|
to other product lines. Personally I think this would suit both Isilion
|
||||||
|
and Atmos lines very nicely.
|
||||||
|
|
||||||
|
I am really excited about this product. It brings a paradigm shift in
|
||||||
|
storage management and automation. Also I am led to believe that the
|
||||||
|
price is exceptional as well, to point that it seems EMC may even be
|
||||||
|
pushing VNX down a market level (to where it should be perhaps?). I have
|
||||||
|
been [a bit nasty](%7B%7B/blog/2012/12/10/emc-extremio-thoughts/) to EMC
|
||||||
|
in the past, but recently they are doing some stuff that has really got
|
||||||
|
me interested. This and [Razor](https://github.com/puppetlabs/Razor) are
|
||||||
|
2 projects that are definitely worth keeping an eye on.
|
||||||
|
|
||||||
|
<iframe width="420" height="315" src="https://www.youtube.com/embed/WoElTAevLDs" frameborder="0" allowfullscreen></iframe>
|
||||||
235
content/blog/upgrade-openstack-from-juno-to-kilo/index.md
Normal file
|
|
@ -0,0 +1,235 @@
|
||||||
|
---
|
||||||
|
date: 2015-08-11
|
||||||
|
title: Upgrade Openstack from Juno to Kilo
|
||||||
|
category: devops
|
||||||
|
featured_image: http://i.imgur.com/UAyzTqf.gif
|
||||||
|
---
|
||||||
|
|
||||||
|
It's a process that strikes fear into the hearts of Sysadmins
|
||||||
|
everywhere. This weekend I finally got round to upgrading the Openstack
|
||||||
|
cluster in my lab to Kilo. As I have no spare machines lying around
|
||||||
|
(Intel NUC/HP Microserver/similar donations welcome) I did it in place.
|
||||||
|
|
||||||
|
Did it go well? Mostly\...
|
||||||
|
|
||||||
|
My base was a Juno install from Packstack. If your Juno install was
|
||||||
|
different, then YMMV, but the idea should transfer. The basic process
|
||||||
|
was to install the Kilo yum repo, then run an upgrade:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo yum install http://rdo.fedorapeople.org/openstack-kilo/rdo-release-kilo.rpm
|
||||||
|
sudo yum upgrade
|
||||||
|
```
|
||||||
|
|
||||||
|
Then a reboot. Finshed\...
|
||||||
|
|
||||||
|
No, nothing is ever that simple.
|
||||||
|
|
||||||
|
In fact most of the services fail dismally due to DB schema updates.
|
||||||
|
This is relatively easily fixed though
|
||||||
|
|
||||||
|
# Keystone
|
||||||
|
|
||||||
|
```
|
||||||
|
systemctl stop httpd openstack-keystone.service
|
||||||
|
systemctl disable openstack-keystone.service
|
||||||
|
sudo -u keystone keystone-manage db_sync
|
||||||
|
```
|
||||||
|
|
||||||
|
The application itself was not updated by the packages, so I collected
|
||||||
|
the lated code from Github:
|
||||||
|
|
||||||
|
```
|
||||||
|
curl http://git.openstack.org/cgit/openstack/keystone/plain/httpd/keystone.py?h=stable/kilo \
|
||||||
|
| sudo tee /var/www/cgi-bin/keystone/main /var/www/cgi-bin/keystone/admin
|
||||||
|
```
|
||||||
|
|
||||||
|
Ensure that to Apache config files are as the should be.
|
||||||
|
|
||||||
|
`/etc/httpd/conf.d/10-keystone_wsgi_admin.conf`:
|
||||||
|
|
||||||
|
```
|
||||||
|
<VirtualHost *:35357>
|
||||||
|
ServerName keystone.example.com
|
||||||
|
WSGIDaemonProcess keystone_admin processes=5 threads=1 user=keystone group=keystone
|
||||||
|
WSGIProcessGroup keystone_admin
|
||||||
|
WSGIScriptAlias / /var/www/cgi-bin/keystone/admin
|
||||||
|
WSGIPassAuthorization On
|
||||||
|
LogLevel info
|
||||||
|
ErrorLogFormat "%{cu}t %M"
|
||||||
|
ErrorLog /var/log/httpd/keystone-error.log
|
||||||
|
CustomLog /var/log/httpd/keystone-access.log combined
|
||||||
|
</VirtualHost>
|
||||||
|
```
|
||||||
|
|
||||||
|
and `/etc/httpd/conf.d/10-keystone_wsgi_main.conf`:
|
||||||
|
|
||||||
|
```
|
||||||
|
<VirtualHost *:5000>
|
||||||
|
ServerName keystone.example.com
|
||||||
|
WSGIDaemonProcess keystone-public processes=5 threads=1 user=keystone group=keystone display-name=%{GROUP}
|
||||||
|
WSGIProcessGroup keystone-public
|
||||||
|
WSGIScriptAlias / /var/www/cgi-bin/keystone/main
|
||||||
|
WSGIApplicationGroup %{GLOBAL}
|
||||||
|
WSGIPassAuthorization On
|
||||||
|
LogLevel info
|
||||||
|
ErrorLogFormat "%{cu}t %M"
|
||||||
|
ErrorLog /var/log/httpd/keystone-error.log
|
||||||
|
CustomLog /var/log/httpd/keystone-access.log combined
|
||||||
|
</VirtualHost>
|
||||||
|
```
|
||||||
|
|
||||||
|
Now restart Apache:
|
||||||
|
|
||||||
|
```
|
||||||
|
systemctl start httpd.service
|
||||||
|
```
|
||||||
|
|
||||||
|
# Glance
|
||||||
|
|
||||||
|
There was nothing surprising here really. Stop the services, update the
|
||||||
|
database and restart the services.
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo systemctl stop openstack-glance-api.service openstack-glance-registry.service
|
||||||
|
sudo -u glance glance-manage db_sync
|
||||||
|
sudo systemctl start openstack-glance-api.service openstack-glance-registry.service
|
||||||
|
```
|
||||||
|
|
||||||
|
# Nova
|
||||||
|
|
||||||
|
Again Nova was quite simple. Stop services, update DB and start again.
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo systemctl stop openstack-nova-api.service \
|
||||||
|
openstack-nova-cert.service openstack-nova-compute.service \
|
||||||
|
openstack-nova.compute.service openstack-nova-conductor.service \
|
||||||
|
openstack-nova-consoleauth.service openstack-nova-network.service \
|
||||||
|
openstack-nova-novncproxy.service openstack-nova-objectstore.service \
|
||||||
|
openstack-nova-scheduler.service openstack-nova-volume.service
|
||||||
|
sudo -u nova nova-manage db null_instance_uuid_scan
|
||||||
|
sudo -u nova "nova-manage db sync
|
||||||
|
sudo systemctl start openstack-nova-api.service \
|
||||||
|
openstack-nova-cert.service openstack-nova-compute.service \
|
||||||
|
openstack-nova.compute.service openstack-nova-conductor.service \
|
||||||
|
openstack-nova-consoleauth.service openstack-nova-network.service \
|
||||||
|
openstack-nova-novncproxy.service openstack-nova-objectstore.service \
|
||||||
|
openstack-nova-scheduler.service openstack-nova-volume.service
|
||||||
|
```
|
||||||
|
|
||||||
|
# Neutron
|
||||||
|
|
||||||
|
This need a few tweaks in `/etc/neutron/neutron.conf`.
|
||||||
|
|
||||||
|
In the \[DEFAULT\] section, change the value of the rpc\_backend option:
|
||||||
|
`neutron.openstack.common.rpc.impl_kombu` becomes `rabbit`
|
||||||
|
|
||||||
|
In the \[DEFAULT\] section, change the value of the core\_plugin option:
|
||||||
|
`neutron.plugins.ml2.plugin.Ml2Plugin` becomes `ml2`
|
||||||
|
|
||||||
|
In the \[DEFAULT\] section, change the value or values of the
|
||||||
|
service\_plugins option to use short names. For example:
|
||||||
|
`neutron.services.l3_router.l3_router_plugin.L3RouterPlugin` becomes
|
||||||
|
`router`
|
||||||
|
|
||||||
|
In the \[DEFAULT\] section, explicitly define a value for the
|
||||||
|
`nova_region_name` option. For example:
|
||||||
|
|
||||||
|
```
|
||||||
|
[DEFAULT]
|
||||||
|
...
|
||||||
|
nova_region_name = regionOne
|
||||||
|
```
|
||||||
|
|
||||||
|
Stop the services and upgrade the DB:
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo systemctl stop neutron-dhcp-agent.service neutron-l3-agent.service \
|
||||||
|
neutron-metadata-agent.service neutron-openvswitch-agent.service \
|
||||||
|
neutron-ovs-cleanup.service neutron-server.service
|
||||||
|
sudo -u neutron neutron-db-manage --config-file /etc/neutron/neutron.conf \
|
||||||
|
--config-file /etc/neutron/plugins/ml2/ml2_conf.ini upgrade kilo
|
||||||
|
```
|
||||||
|
|
||||||
|
Now you can restart Neutron
|
||||||
|
|
||||||
|
```
|
||||||
|
sudo systemctl start neutron-dhcp-agent.service neutron-l3-agent.service \
|
||||||
|
neutron-metadata-agent.service neutron-openvswitch-agent.service \
|
||||||
|
neutron-ovs-cleanup.service neutron-server.service
|
||||||
|
```
|
||||||
|
|
||||||
|
# Horizon
|
||||||
|
|
||||||
|
This pretty much worked, but what I did see is that once mu login ticket
|
||||||
|
expired then I could not login unless I cleared the cookie out.
|
||||||
|
|
||||||
|
This is easily fixed by adding `AUTH_USER_MODEL = 'openstack_auth.User'`
|
||||||
|
to `/etc/openstack-dashboard/local_settings`.
|
||||||
|
|
||||||
|
# Cinder
|
||||||
|
|
||||||
|
This is what gave me the most problems. Basically, the database for
|
||||||
|
Cinder itself, the database for Nova volumes and the actual iSCSI target
|
||||||
|
got out of sync. I ran `nova volume-detach ...` and it got stuck in a
|
||||||
|
detaching state.
|
||||||
|
|
||||||
|
Basically, I had to go through and get it into a know state (volumes
|
||||||
|
attached to anything) via the back door.
|
||||||
|
|
||||||
|
As an admin, force the volume into \"available\" with:
|
||||||
|
|
||||||
|
```
|
||||||
|
nova volume-detach <instance_uuid> <volume_id>
|
||||||
|
cinder reset-state --state available <volume_id>
|
||||||
|
```
|
||||||
|
|
||||||
|
Using
|
||||||
|
[targetcli](http://linux-iscsi.org/wiki/Targetcli#Quick_start_guide)
|
||||||
|
ensure that there are no ACLs on the LUNs. They will be named with the
|
||||||
|
volume\_id. I\'ll not go into the details of how to use `targetcli`,
|
||||||
|
just that you remove a *file* from the virtual tree that it creates.
|
||||||
|
|
||||||
|
Next up you\'ll need to going to manipulate the Cinder database (hope
|
||||||
|
you still have your packstack file). Standard disclaimer: You can
|
||||||
|
royally screw things up here, so tread carefully, use transactions and
|
||||||
|
take a backup first.
|
||||||
|
|
||||||
|
```
|
||||||
|
update cinder.volumes set attach_status='detached',
|
||||||
|
status='available' where id ='$volume_id';
|
||||||
|
```
|
||||||
|
|
||||||
|
Now do the same in Nova.
|
||||||
|
|
||||||
|
```
|
||||||
|
delete from block_device_mapping where not deleted
|
||||||
|
and volume_id='$volume_id'
|
||||||
|
```
|
||||||
|
|
||||||
|
You should now be able re-attach the volume to the instance using the
|
||||||
|
CLI. However, I had one that persisted in playing silly buggers. I had
|
||||||
|
to manually update the Cinder DB that is in the *attached* state:
|
||||||
|
|
||||||
|
```
|
||||||
|
update cinder.volumes set attach_status='attached',
|
||||||
|
status='in-use' where id ='$volume_id';
|
||||||
|
```
|
||||||
|
|
||||||
|
Finally do a full reboot to ensure that everything comes back as you
|
||||||
|
expect.
|
||||||
|
|
||||||
|
I am pretty sure that is everything.
|
||||||
|
|
||||||
|
# Conclusion
|
||||||
|
|
||||||
|
I think this was the first time I have done an upgrade of Openstack in
|
||||||
|
place. Considering the fear that this operation puts in people, I think
|
||||||
|
it went pretty smoothly.
|
||||||
|
|
||||||
|
I started the install Friday evening, the upgrade was finished that
|
||||||
|
night. Most of my lab instances were up and running by Saturday evening
|
||||||
|
(having spent the day at the beach). All bar one were running Sunday
|
||||||
|
evening (after another trip to the beach). The last instance (with the
|
||||||
|
awkward Cinder volume) was running this morning (again, wait for it:
|
||||||
|
after a trip to the beach yesterday).
|
||||||
149
content/blog/using-eyaml-with-puppet-4/index.md
Normal file
|
|
@ -0,0 +1,149 @@
|
||||||
|
---
|
||||||
|
date: 2016-01-05
|
||||||
|
title: Using EYAML with Puppet 4
|
||||||
|
category: devops
|
||||||
|
---
|
||||||
|
|
||||||
|
|
||||||
|
Happy 2016 all
|
||||||
|
|
||||||
|
This weekend I finally got round to adding eyaml support to Puppet in my
|
||||||
|
lab. What is on earth am I talking about?
|
||||||
|
|
||||||
|
Puppet can use a thing called *Hiera* as a data source, think of it as a
|
||||||
|
database for configuraion. In an ideal world, your manifests will be
|
||||||
|
completely generic - in fact your control repo could consist of nothing
|
||||||
|
but a `Puppetfile` with a list of modules to install (if any one lives
|
||||||
|
in that ideal world, you are better than me). Hiera in turn can have
|
||||||
|
different backends for describing this data, such as:
|
||||||
|
|
||||||
|
- JSON
|
||||||
|
- YAML
|
||||||
|
- eYAML or *encrypted* YAML
|
||||||
|
|
||||||
|
So how do we use it? On my workstation (where I do my Puppet
|
||||||
|
development), I also the eyaml gem:
|
||||||
|
|
||||||
|
gem install hiera-eyaml
|
||||||
|
|
||||||
|
It should be noted that I run [RVM](https://rvm.io) and run a Ruby
|
||||||
|
environment and Gemset just for Puppet development
|
||||||
|
(https://gogs.chriscowley.me.uk/chriscowley/puppet/src/production/.rvmrc).
|
||||||
|
My Gemfile includes the *hiera-eyaml* gem, so I simply run
|
||||||
|
`bundle install`.
|
||||||
|
|
||||||
|
Next, you need to create some keys:
|
||||||
|
|
||||||
|
eyaml createkeys
|
||||||
|
|
||||||
|
This creates your key pair in `./keys`. Move this somewhere more
|
||||||
|
sensible and configure eyaml to look there.
|
||||||
|
|
||||||
|
mkdir -pv ~/.eyaml
|
||||||
|
mv -v keys ~/.eyaml/
|
||||||
|
cat > ~/.eyaml/config.yaml < EOF
|
||||||
|
---
|
||||||
|
pkcs7_private_key: '/home/chris/.eyaml/keys/private_key.pkcs7.pem'
|
||||||
|
pkcs7_public_key: '/home/chris/.eyaml/keyspublic_key.pkcs7.pem'
|
||||||
|
EOF
|
||||||
|
|
||||||
|
Now you can test it by running
|
||||||
|
`eyaml encrypt -l msql_root_password -s "correcthorsebatterystaple"`
|
||||||
|
which will output something like:
|
||||||
|
|
||||||
|
[hiera-eyaml-core] Loaded config from /home/mmzv6833/.eyaml/config.yaml
|
||||||
|
msql_root_password: ENC[PKCS7,MIIBiQYJKoZIhvcNAQcDoIIBejCCAXYCAQAxggEhMIIBHQIBADAFMAACAQEwDQYJKoZIhvcNAQEBBQAEggEAPvmib/bFce7ArK/FSMHX9DVsqDo38tL/Xpc9XtWCPlqvfkfwBFPRD0qM2qbEL3JchRSmirb/yBy/20HFk7vX84PIy7IfSYEt+u2RkVUuWgSHfjnKVnJc5wul8IqHdeWIoFT5/D6dsrBP94qD6CwbIzKRRzSijuxPMbXhQQecwPBBSQAtNHWAVsw4U7lv7tVP+OoZSSnP0zqJOp2Pt6x4ivj/Wha4hPcF8KvUNKLR7ZcebHbJslJUTYqg1cMwRPMuccbXS3JvGdoFiACAPEjghbAmK6UgaZ2nTxuVGJ4B81Q6Nnsk3Ir/JVjFCKI+x+bZoVn+y1coLBPy52RE5OdPoDBMBgkqhkiG9w0BBwEwHQYJYIZIAWUDBAEqBBCrcffFAXvzkNnYGpjcIVr2gCBpSG4Q9HZRDT07Yz0ijDb+3RlbLnRzlMvsP2O4phTOig==]
|
||||||
|
|
||||||
|
OR
|
||||||
|
|
||||||
|
msql_root_password: >
|
||||||
|
ENC[PKCS7,MIIBiQYJKoZIhvcNAQcDoIIBejCCAXYCAQAxggEhMIIBHQIBADAFMAACAQEw
|
||||||
|
DQYJKoZIhvcNAQEBBQAEggEAPvmib/bFce7ArK/FSMHX9DVsqDo38tL/Xpc9
|
||||||
|
XtWCPlqvfkfwBFPRD0qM2qbEL3JchRSmirb/yBy/20HFk7vX84PIy7IfSYEt
|
||||||
|
+u2RkVUuWgSHfjnKVnJc5wul8IqHdeWIoFT5/D6dsrBP94qD6CwbIzKRRzSi
|
||||||
|
juxPMbXhQQecwPBBSQAtNHWAVsw4U7lv7tVP+OoZSSnP0zqJOp2Pt6x4ivj/
|
||||||
|
Wha4hPcF8KvUNKLR7ZcebHbJslJUTYqg1cMwRPMuccbXS3JvGdoFiACAPEjg
|
||||||
|
hbAmK6UgaZ2nTxuVGJ4B81Q6Nnsk3Ir/JVjFCKI+x+bZoVn+y1coLBPy52RE
|
||||||
|
5OdPoDBMBgkqhkiG9w0BBwEwHQYJYIZIAWUDBAEqBBCrcffFAXvzkNnYGpjc
|
||||||
|
IVr2gCBpSG4Q9HZRDT07Yz0ijDb+3RlbLnRzlMvsP2O4phTOig==]
|
||||||
|
|
||||||
|
This is all well and good for you dev environment, but utterly useless
|
||||||
|
for the Puppetmaster as it has no idea about the key. Even if it did,
|
||||||
|
out-of-the-box it will not look for the encrypted data anyway.
|
||||||
|
|
||||||
|
So, copy the keys to your Puppetmaster:
|
||||||
|
|
||||||
|
scp -r ~/.eyaml/keys user@puppetmaster:~/
|
||||||
|
|
||||||
|
Notice I user `scp`: at least the private key is extremely sensitive;
|
||||||
|
never transport it in clear text, make sure you store it securely, etc,
|
||||||
|
etc. You have been warned.
|
||||||
|
|
||||||
|
Now put them where your Puppetserver can get to them and install the
|
||||||
|
Gem.
|
||||||
|
|
||||||
|
sudo mkdir -pv /etc/puppetlabs/puppet/secure
|
||||||
|
sudo mv -v keys /etc/puppetlabs/puppet/secure/
|
||||||
|
sudo chown -Rv puppet:puppet /etc/puppetlabs/puppet/secure
|
||||||
|
sudo chmod -Rv 550 /etc/puppetlabs/puppet/secure
|
||||||
|
sudo puppetserver gem install hiera-eyaml
|
||||||
|
|
||||||
|
Now you need to modify your hiera config file
|
||||||
|
(`/etc/puppetlabs/code/hiera.yaml`) to look something like:
|
||||||
|
|
||||||
|
---
|
||||||
|
:backends:
|
||||||
|
- eyaml
|
||||||
|
- yaml
|
||||||
|
|
||||||
|
:hierarchy:
|
||||||
|
- %{::clientcert}
|
||||||
|
- %{::environment}
|
||||||
|
- "virtual_%{::is_virtual}"
|
||||||
|
- common
|
||||||
|
|
||||||
|
:yaml:
|
||||||
|
:datadir: '/etc/puppetlabs/code/hieradata'
|
||||||
|
:eyaml:
|
||||||
|
:datadir: '/etc/puppetlabs/code/hieradata'
|
||||||
|
|
||||||
|
:pkcs7_private_key: /etc/puppetlabs/secure/keys/private_key.pkcs7.pem
|
||||||
|
:pkcs7_public_key: /etc/puppetlabs/secure/keys/public_key.pkcs7.pem
|
||||||
|
|
||||||
|
A couple of things here:
|
||||||
|
|
||||||
|
- I do not keep my hiera data in my repo, I like to have it completely
|
||||||
|
separate.
|
||||||
|
- It is truly a database for my Puppet code
|
||||||
|
- I can use the same data across environments
|
||||||
|
- I keep my encrypted data separate too, as is default, in .eyaml
|
||||||
|
files.
|
||||||
|
|
||||||
|
That is the Puppetmaster ready to use, we just need to actually put some encrypted data in there for it to collect. Think back to Puppet's excellent [Hiera docs](http://docs.puppetlabs.com/hiera/latest/hierarchy.html)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Now the host _db01_ will have potentially 2 files specific to it: `db01.example.com.yaml` and `db01.example.com.eyaml`. So to install Mysql on that (naturally using the [Puppetlabs module](https://forge.puppetlabs.com/puppetlabs/mysql)) `db01.example.com.yaml` will contain:
|
||||||
|
|
||||||
|
---
|
||||||
|
classes:
|
||||||
|
- mysql::server
|
||||||
|
mysql::server::remove_default_accounts: true
|
||||||
|
|
||||||
|
then in `db01.example.com.eyaml` put:
|
||||||
|
|
||||||
|
---
|
||||||
|
mysql::server::root_password: >
|
||||||
|
ENC[PKCS7,MIIBiQYJKoZIhvcNAQcDoIIBejCCAXYCAQAxggEhMIIBHQIBADAFMAACAQEw
|
||||||
|
DQYJKoZIhvcNAQEBBQAEggEAhWgxLsgvtUzALxqE23nrcgy8xR+UbV5b45Vo
|
||||||
|
joRLq4QLDhLKuwAsoaQ3MbYfrbJ5RQ2PTFlwB+Cp7X2uLQ0YYfisABT/dwaK
|
||||||
|
9iYZoXkvsSvt8iqZkVNP9HZLf/X1EkLfljbsEx7vigMyWu8ApDt5aGCxqGA6
|
||||||
|
NTGZkeOoUhfRM9KuzRvkIQB0eutuIx420EgKI0gdCVPv1Y51UdEMl7rClwz3
|
||||||
|
4ATlPmL0F2NVNifZC+KdWGei+PYSYM394JvS0ZBxuNWLowlmR2SgbzSCpWZn
|
||||||
|
mB1jolaG7nXv7Y1OnvZraA3EIUcwKiILlsC1vlXuVc6xdKBvhb70j6p30SzB
|
||||||
|
6eF2IzBMBgkqhkiG9w0BBwEwHQYJYIZIAWUDBAEqBBCH5GYGDeLdZniZdkCt
|
||||||
|
Xe7bgCAaY8TVUw4NaHc2ARbCSAsZSH91UPaDMAWaC6wrYorLEw==]
|
||||||
|
|
||||||
|
When the agent on _db01_ connects, the Puppetmaster will work its way down through the hierachy populating each variable as it goes. As the _eyaml_ backend is defined first in the hierachy, then it will take priority (for simple paramters, hashes and arrays are more complex). This means that if you were to leave an old value for `mysql::server::root_password` in the plain yaml file, it will be ignored.
|
||||||
|
|
||||||
|
I hope this is helpful for someone, what it means is that you can share all the code for your infrastructure with the world. I will certainly be doing this, I just need to refacter things a little to put my defined types into Hiera as I use them to create databases. This is not complex and will be the subject of a future post.
|
||||||
114
content/blog/using-hiera-with-puppet/index.md
Normal file
|
|
@ -0,0 +1,114 @@
|
||||||
|
---
|
||||||
|
date: 2013-04-11
|
||||||
|
title: Using Hiera with Puppet
|
||||||
|
category: devops
|
||||||
|
---
|
||||||
|
|
||||||
|
Using Hiera with Puppet is something I have struggled with a bit. I
|
||||||
|
could see the benefits, namely decoupling my site configuration from my
|
||||||
|
logic. However, for some reason I struggled a bit to really get my head
|
||||||
|
around it. This was compounded by it being quite new (only really
|
||||||
|
integrated in Puppet 3), so the docs are little lacking.
|
||||||
|
|
||||||
|
There is some though, the [documentation on PuppetLab's
|
||||||
|
site](https://docs.puppetlabs.com/hiera/latest/) is excellent, but a bit
|
||||||
|
light. It explains the principles well, but is a little limited in
|
||||||
|
real-world examples. Probably the best resource I found was Kelsey
|
||||||
|
Hightower's excellent presentation at [PuppetConf
|
||||||
|
2012](https://youtu.be/z9TK-gUNFHk):
|
||||||
|
|
||||||
|
I learnt a lot from that, but it would be nice if there was an
|
||||||
|
equivalent written down. I suppose that is what I am aiming at here.
|
||||||
|
|
||||||
|
Configuration
|
||||||
|
-------------
|
||||||
|
|
||||||
|
- [NFS Module](https://github.com/chriscowley/puppet-nfs)
|
||||||
|
- [Hiera
|
||||||
|
Config](https://github.com/chriscowley/my-master-puppet/blob/master/hiera.yaml)
|
||||||
|
- [Hiera
|
||||||
|
Data](https://github.com/chriscowley/my-master-puppet/tree/master/hieradata)
|
||||||
|
|
||||||
|
I am using Open Source Puppet 3. If you are using 2.7 or Puppet
|
||||||
|
Enterprise, files will be in a slightly different place. That is all
|
||||||
|
explained in the documentation linked above.
|
||||||
|
|
||||||
|
The first thing you need to do is configure Hiera using the file
|
||||||
|
`/etc/puppet/hiera.yaml`. Mine looks like this:
|
||||||
|
|
||||||
|
---
|
||||||
|
:backends:
|
||||||
|
- yaml
|
||||||
|
:yaml:
|
||||||
|
:datadir: /etc/puppet/hieradata/
|
||||||
|
:hierarchy:
|
||||||
|
- %{::clientcert}
|
||||||
|
- common
|
||||||
|
|
||||||
|
This tells Hiera to use only the YAML backend - I do not like JSON
|
||||||
|
because it always looks messy to me. It will look for the data in the
|
||||||
|
folder `/etc/puppet/hieradata`. Finally it will look in that folder for
|
||||||
|
a file called .yaml, then common.yaml. The process it uses to apply the
|
||||||
|
values is explained very nicely in this image: {% img
|
||||||
|
<https://docs.puppetlabs.com/hiera/latest/images/hierarchy1.png> %}
|
||||||
|
|
||||||
|
Next, create the file `/etc/puppet/hieradata/<certname>.yaml` that
|
||||||
|
contains your NFS exports:
|
||||||
|
|
||||||
|
---
|
||||||
|
exports:
|
||||||
|
- /srv/iso
|
||||||
|
- /srv/images
|
||||||
|
|
||||||
|
Now, checkout my NFS module from Github links above. If you are not on
|
||||||
|
RHEL6 or similar (I use Centos personally) you will have to modify it as
|
||||||
|
needed.
|
||||||
|
|
||||||
|
There are 2 files that are really interesting here. The manifest file
|
||||||
|
(manifests/server.pp) and the template to build the `/etc/exports` file
|
||||||
|
(templates/exports.erb). We'll take apart the manifest, the template
|
||||||
|
just iterates over the data passed to it from that.
|
||||||
|
|
||||||
|
The first line creates an array variable called \$exports from the Hiera
|
||||||
|
data. Specifically, it looks for a key called *exports*. Hiera then goes
|
||||||
|
through the hierarchy explained earlier looking for that key. In this
|
||||||
|
case it will find it in the .yaml.
|
||||||
|
|
||||||
|
This data is now used for 2 things. First it creates the necessary
|
||||||
|
folders, then it build `/etc/exports`. Here there is a minor problem,
|
||||||
|
because you cannot do a *for each* loop in a Puppet manifest. We can
|
||||||
|
fiddle it a bit by using a [defined
|
||||||
|
type](https://docs.puppetlabs.com/puppet/3/reference/lang_defined_types.html).
|
||||||
|
|
||||||
|
The line `list_exports { $exports:; }` passes the `$exports` array to
|
||||||
|
the type we define above it. This then goes ahead and creates the
|
||||||
|
folders ready to be exported. The `->` builds an [order
|
||||||
|
relationship](https://docs.puppetlabs.com/puppet/3/reference/lang_relationships.html#chaining-arrows)
|
||||||
|
with the File resource for */etc/exports*. Specifically, that the
|
||||||
|
directories need to be created before they are exported.
|
||||||
|
|
||||||
|
define list_exports {
|
||||||
|
$export = $name
|
||||||
|
file { $export:
|
||||||
|
ensure => directory,
|
||||||
|
mode => '0755',
|
||||||
|
owner => 'root',
|
||||||
|
group => 'root'
|
||||||
|
}
|
||||||
|
}
|
||||||
|
list_exports { $exports:; } -> File['/etc/exports']
|
||||||
|
|
||||||
|
Now it can go ahead and build the `/etc/exports` file using that same
|
||||||
|
\$exports array in the `templates/exports.erb` template:
|
||||||
|
|
||||||
|
<% [exports].flatten.each do |export| -%>
|
||||||
|
<%= export %> 192.168.1.0/255.255.255.0(rw,no_root_squash,no_subtree_check)
|
||||||
|
<% end -%>
|
||||||
|
|
||||||
|
There is nothing especially Hiera'y about this, other than where the
|
||||||
|
data in that array came from.
|
||||||
|
|
||||||
|
The rest of the manifest deals with installing the packages and
|
||||||
|
configuring services. Once again, nothing especially linked with Hiera,
|
||||||
|
but hopefully it will be useful for anyone wanting to Puppetize their
|
||||||
|
NFS servers - which of course you should be.
|
||||||
126
content/blog/using-letsencrypt-with-apache-and-puppet/index.md
Normal file
|
|
@ -0,0 +1,126 @@
|
||||||
|
---
|
||||||
|
date: 2016-05-10
|
||||||
|
title: Letsencrypt with Apache and Puppet
|
||||||
|
category: devops
|
||||||
|
Summary: Using Puppet to manage Letsencrypt certs and Apache VirtualHosts
|
||||||
|
---
|
||||||
|
|
||||||
|
This week I set myself the task of getting my various SSL site under Puppet control. Like all the cool kids I use [letsencrypt](https://letsencrypt.org) for these certs. I also want to get all the information from Hiera. There are a small collection of modules you need:
|
||||||
|
|
||||||
|
|
||||||
|
- [danzilio/letsencrypt](https:/forge.puppetlabs.com/danzilio/letsencrypt)
|
||||||
|
- [stahnma/epel](https:/forge.puppetlabs.com/stahnma/epel)
|
||||||
|
- [puppetlabs/apache](https:/forge.puppetlabs.com/puppetlabs/apache)
|
||||||
|
- Rob Nelson's [hiera_resources](https://github.com/rnelson0/puppet-hiera_resources)
|
||||||
|
|
||||||
|
If you're using R10K (which you should) then add the following to your `Puppetfile`:
|
||||||
|
|
||||||
|
```
|
||||||
|
mod 'puppetlabs/apache', '1.4.1'
|
||||||
|
mod 'danzilio/letsencrypt', '1.0.0'
|
||||||
|
mod 'stahnma/epel'
|
||||||
|
mod 'hiera_resources',
|
||||||
|
:git => 'https://github.com/rnelson0/puppet-hiera_resources.git'
|
||||||
|
```
|
||||||
|
|
||||||
|
We need to do 3 things (in the right order):
|
||||||
|
|
||||||
|
1. Create a non-SSL Virtualhost
|
||||||
|
- DNS must already point to the host
|
||||||
|
- Will redirect to the SSL Virtualhost
|
||||||
|
- Must not redirect the Letsencrypt acme-challenge
|
||||||
|
- The first time, this will need to respond via the default virtualhost
|
||||||
|
2. Generate a certificate
|
||||||
|
3. Create the SSL Virtualhost using this certificate
|
||||||
|
|
||||||
|
I cannot tell you how to do the DNS, but the rest we can do with Puppet.
|
||||||
|
|
||||||
|
I put all this in a dedicated *local* module. The only thing local about it is that it is not really useful for anyone other me. It is [available though](https://gogs.chriscowley.me.uk/puppet/chriscowley-lablocal) if you want to have a look at it. What this allows me to do is define my SSL and non-SSL vhosts seperately in Hiera, and also define my certs in hiera. I can then create relationships between them to define the order.
|
||||||
|
|
||||||
|
So, my `site.pp` will contain (`lablocal` is that local module):
|
||||||
|
|
||||||
|
```
|
||||||
|
hiera_include('classes')
|
||||||
|
class { 'lablocal::nonsslvhosts': }->
|
||||||
|
class { 'lablocal::letsencryptcerts': }->
|
||||||
|
class { 'lablocal::sslvhosts': }
|
||||||
|
```
|
||||||
|
|
||||||
|
That references 3 classes in the lablocal module:
|
||||||
|
|
||||||
|
nonsslvhosts.pp
|
||||||
|
|
||||||
|
```
|
||||||
|
class lablocal::nonsslvhosts {
|
||||||
|
hiera_resources('apache-nonssl-vhosts')
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
letsencryptcerts.pp
|
||||||
|
|
||||||
|
```
|
||||||
|
class lablocal::letsencryptcerts {
|
||||||
|
hiera_resources('letsencryptcerts')
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
sslvhosts.pp
|
||||||
|
|
||||||
|
```
|
||||||
|
class lablocal::sslvhosts {
|
||||||
|
hiera_resources('apache-ssl-vhosts')
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
None of that is very complicated. All of the clever stuff is happenning in the Hiera file for that node:
|
||||||
|
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
classes:
|
||||||
|
- apache
|
||||||
|
- epel
|
||||||
|
- letsencrypt
|
||||||
|
|
||||||
|
apache-nonssl-vhosts:
|
||||||
|
apache::vhost:
|
||||||
|
www.example.com-nonssl:
|
||||||
|
servername: www.example.com
|
||||||
|
port: 80
|
||||||
|
docroot: /var/www/html
|
||||||
|
redirectmatch_status: 301
|
||||||
|
redirectmatch_regexp: ^(?!/\.well-known/acme-challenge/).*
|
||||||
|
redirectmatch_dest: https://www.example.com$0
|
||||||
|
apache-ssl-vhosts:
|
||||||
|
apache::vhost:
|
||||||
|
www.example.com:
|
||||||
|
port: 443
|
||||||
|
servername: www.example.com
|
||||||
|
docroot: /var/www/www.example.com
|
||||||
|
ssl: true
|
||||||
|
ssl_chain: /etc/letsencrypt/live/www.example.com/chain.pem
|
||||||
|
ssl_key: /etc/letsencrypt/live/www.example.com/privkey.pem
|
||||||
|
ssl_cert: /etc/letsencrypt/live/www.example.com/cert.pem
|
||||||
|
proxy_pass:
|
||||||
|
-
|
||||||
|
path: '/'
|
||||||
|
url: 'http://10.1.0.15:8080/'
|
||||||
|
letsencrypt::email: example@example.com
|
||||||
|
letsencrypt::configure_epel: false
|
||||||
|
letsencrypt::manager_cron: true
|
||||||
|
letsencryptcerts:
|
||||||
|
letsencrypt::certonly:
|
||||||
|
www.example.com:
|
||||||
|
plugin: webroot
|
||||||
|
webroot_paths:
|
||||||
|
- /var/www/html
|
||||||
|
```
|
||||||
|
|
||||||
|
All this is colllected using the hiera_resources module. First we collect the nonssl vhosts. We create a vhost with using the default docroot that performs a permanent redirect to the https:// vhost. However, we add in an exception for */.well-known/acme-challenge/* so that the letsencrypt server can talk back to us to authorise the certificate.
|
||||||
|
|
||||||
|
When this is created, Apache will be **scheduled** for a restart. This does not actually happen, so the first time the certificate is created letsencrypt will actually come in via the default virtualhost, not this one. In the future though, when the certificate is renewed, it will be used and the exception is required.
|
||||||
|
|
||||||
|
Next we create the certificate itself using the *webroot* plugin and put the response in `/var/www/html/`. It will also create a cron job to automatically renew the certificate.
|
||||||
|
|
||||||
|
Finally it can create the main Virtualhost which should probably not contain anything surprising.
|
||||||
73
content/blog/vision-team-30-comp-review/index.md
Normal file
|
|
@ -0,0 +1,73 @@
|
||||||
|
---
|
||||||
|
date: 2017-04-11
|
||||||
|
title: Vision Team 30 comp review
|
||||||
|
category: cycling
|
||||||
|
featured_image: https://assets.cowley.tech/file/cowley-tech-assets/fykN1gbl.jpg
|
||||||
|
---
|
||||||
|
|
||||||
|
For the last few months I have been rolling on a set of Vision Team 30 Comp wheels.
|
||||||
|
|
||||||
|
These are an entry level set of wheels that are aimed at commuting and
|
||||||
|
training. They have a slightly deeper profile than most other wheels in this
|
||||||
|
price range (below €200) which, along with the bladed spokes make them more
|
||||||
|
aero than your average budget wheel (on paper at least). Also, at least in
|
||||||
|
black, they look great.
|
||||||
|
|
||||||
|
To get straight to the point, what do I think about them? To be fair, apart
|
||||||
|
froma couple of things, I quite like them. They roll well, I definitely think I
|
||||||
|
go a little faster on them and they have taken at least one big hit and are
|
||||||
|
perfectly true still.
|
||||||
|
|
||||||
|
What do I not like them? Two things, on relatively minor and one, well, not so
|
||||||
|
minor.
|
||||||
|
|
||||||
|
First, they are hard to mount tyres on. I use them with 23mm Vittoria Rubino
|
||||||
|
Pro. Without a floor pump, I simply cannot get the tyres to sit cleanly on the
|
||||||
|
rim - the bead will just not sit properly in the rim bed. Pump them up swiftly
|
||||||
|
with a track pump and at about 95-100psi you hear the bangs as the bead jumps
|
||||||
|
into place and everyone is happy. This means that road side repairs will never
|
||||||
|
be properly done. You will be vibrating slightly all the way home, or to the
|
||||||
|
nearest bike shop to borrow their pump. A CO2 inflator would probably work, but
|
||||||
|
I do not carry them as I think they are silly.
|
||||||
|
|
||||||
|
That is a pretty small problem though - far worse is the freehub. Basically,
|
||||||
|
after 3 months it was dead with the pawls no longer engaging. This left me
|
||||||
|
walking home and very grumpy. I know these are entry level wheels, but that is
|
||||||
|
just simply not good enough.
|
||||||
|
|
||||||
|
When I get home (late) I dismantled the rear hub to clean the pawls, however
|
||||||
|
the freehub is a sealed unit with no access to the pawls - the only option was
|
||||||
|
to replace the whole freehub. In addition, the drive-side bearings were badly
|
||||||
|
discoloured and both the cup and cone decidedly rough. To be generous they were
|
||||||
|
not in great condition, but more honestly they were ruined.
|
||||||
|
|
||||||
|
So what is one to do? After 3 months, there was no problem sending the wheel
|
||||||
|
back to Probike. They arranged for FedEx to collect it and I sent it back tor
|
||||||
|
them. Once I got the wheel back I inspected it to see what they had done. They
|
||||||
|
had rebuilt the wheel around a hun from the next wheel up in the range, so I
|
||||||
|
have now effectively got a Team 30 clincher instead of a Team 30 Comp. It has
|
||||||
|
cartridge bearings and rolls noticably more smoothly than before.
|
||||||
|
|
||||||
|
I am really happy with the way Probike handled my case. I dropped into my LBS
|
||||||
|
and asked if he had a replacement freehub that I could buy to get going quickly
|
||||||
|
while the broken one was RMA'd. As a thank you I got an earful about how online
|
||||||
|
retailers do no waste time behind a counter. Well they did spend a lot of time
|
||||||
|
with me. We had a substantial email conversation and they had to research the
|
||||||
|
necessary replacement parts with Vision. They never quibbled, and were initially
|
||||||
|
happy to simply send me a replacement freehub, although the correct model turned
|
||||||
|
out to be unavailable. They then got someone to essentially build me a new wheel.
|
||||||
|
|
||||||
|
As for the wheels themselves? Well, do not buy the Team 30 Comp as build
|
||||||
|
quality is awful. The Team 30 is €50 more and seems to be the far better buy. I
|
||||||
|
can also whole-heartedly recommend Probike too. I am not going to say they are
|
||||||
|
better than Wiggle or ChainReaction as all three provide an excellent service. I
|
||||||
|
have now used the after-sales from each of them and have not had a single issue.
|
||||||
|
|
||||||
|
|
||||||
|
Another thing: A lot of local bike shops get upset with online retailers. I can
|
||||||
|
understand them, but the reality is that Wiggle et al are going nowhere. A
|
||||||
|
local shop needs to change and evolve. Online brands know that they cannot offer
|
||||||
|
the personal service of the local shop, so they bend over backwards on the after
|
||||||
|
sales. If you want to survive, you cannot let a single client (or potential
|
||||||
|
client) walk out of your shop with a bad taste in their mouth.
|
||||||
|
|
||||||
34
content/blog/vmware-cli-on-ubuntu-saucy-salamander/index.md
Normal file
|
|
@ -0,0 +1,34 @@
|
||||||
|
---
|
||||||
|
date: 2014-04-09
|
||||||
|
title: VMware CLI on Ubuntu Saucy Salamander
|
||||||
|
category: linux
|
||||||
|
featured_image: (https://www.datanalyzers.com/VMware-Data-Recovery.jpg
|
||||||
|
---
|
||||||
|
|
||||||
|
The current project (as of this week) has me moving away from Openstack
|
||||||
|
for a while. For the next couple of months I will be immersing myself in
|
||||||
|
monitor, metrics and logging. Naturally, this being a shiney new
|
||||||
|
environment, this involves a significant amount of VMware time.
|
||||||
|
|
||||||
|
I have inherited an Icinga install running on Ubuntu Server, so I will
|
||||||
|
be needing to run CLI commands to create checks. Simply runnning the
|
||||||
|
installer does not work, as the vmware-cli package is a mixture of 32
|
||||||
|
and 64 bit commands.
|
||||||
|
|
||||||
|
First you need to download the CLI from VMware. How to do that is an
|
||||||
|
exercise for the reader, as I cannot be bothered to find the link (hint:
|
||||||
|
it is not hard). Then you need to install a bunch of packages:
|
||||||
|
|
||||||
|
sudo apt-get install cpanminus libdata-dump-perl libsoap-lite-perl libclass-methodmaker-perl libxml-libxml-simple-perl libssl-dev libarchive-zip-perl libuuid-perl lib32z1 lib32ncurses5 lib32bz2-1.0
|
||||||
|
|
||||||
|
This includes a bunch of Perl modules for munching through XML, plus
|
||||||
|
some 32-bit libraries so that all the tools can work.
|
||||||
|
|
||||||
|
Finally, you can extract the tarball and install the CLI:
|
||||||
|
|
||||||
|
tar xvf VMware-vSphere-CLI-5.5.0-1549297.x86_64.tar.gz
|
||||||
|
cd vmware-vsphere-cli-distrib/
|
||||||
|
sudo ./vmware-install.pl
|
||||||
|
|
||||||
|
I have not tested it, but this will probably be the same process for
|
||||||
|
Debian (at least Wheezy and Sid).
|
||||||
62
content/blog/what-a-boss-owes-their-staff/index.md
Normal file
|
|
@ -0,0 +1,62 @@
|
||||||
|
---
|
||||||
|
date: 2013-03-18
|
||||||
|
title: What a boss owes their staff
|
||||||
|
category: Opinions
|
||||||
|
featured_image: /images/reputation-management-starts-with-trust.jpg
|
||||||
|
---
|
||||||
|
|
||||||
|
I recently had a conversation on Twitter with my friend [Rob
|
||||||
|
Borley](https://www.robborley.com/) who runs a [mobile
|
||||||
|
startup](https://www.dootrix.com/). He had asked what interesting perks
|
||||||
|
he should be giving his
|
||||||
|
[staff](https://twitter.com/bobscape/statuses/313610008535367680).
|
||||||
|
|
||||||
|
My initial response was the standard IT answer.
|
||||||
|
Training, certifications and a lab to play in, which they already have.
|
||||||
|
I like to find the root cause of things, usually that means looking for
|
||||||
|
the underlying reason something is broken. In this case I wanted to put
|
||||||
|
a more positive spin on it. When you have a great work environment
|
||||||
|
what is it that is at the root? The answer is simple: trust.
|
||||||
|
|
||||||
|
By way of a silly example, if I were to put a cake in the middle of my
|
||||||
|
son's classroom, I can guarantee that the majority of the cake will go
|
||||||
|
into the mouths of a few, while most will probably not get any. Why?
|
||||||
|
They are children, that is why. However, if I give it to his teacher
|
||||||
|
then she will make sure that it gets evenly distributed to everyone.
|
||||||
|
She, like your staff, is an adult and she behaves as such.
|
||||||
|
|
||||||
|
The has been a lot in the news recently about
|
||||||
|
remote-working. Chiefly because of the new Yahoo CEO [putting a
|
||||||
|
stop](https://allthingsd.com/20130222/physically-together-heres-the-internal-yahoo-no-work-from-home-memo-which-extends-beyond-remote-workers/)
|
||||||
|
to it. I have to fall in line with what Tony Schwartz [wrote in
|
||||||
|
response](https://www.businessinsider.com/want-productive-employees-treat-them-like-adults-2013-3)
|
||||||
|
to that on Business Insider. Basically, if you cannot trust your staff
|
||||||
|
to work when they are not in the office, you have hired the wrong
|
||||||
|
people. You cannot be watching them all the time, nor can
|
||||||
|
middle-management once you are past the start-up stage. Basically,
|
||||||
|
if someone is going to sit there surfing Engadget all day, you are
|
||||||
|
powerless to stop them. However, they will not be delivering, so
|
||||||
|
they have to go. Likewise I have had colleagues who everytime I looked
|
||||||
|
at their screen were surfing Ebay, or the Register. We hardly ever
|
||||||
|
discussed computers, we mostly discussed trains and bikes. We delivered
|
||||||
|
however, so who cares what was in our browser window and conversation? I
|
||||||
|
myself got pulled to one side one day by my old boss to ask why I was
|
||||||
|
playing around with an ESX server. We had no VMware servers, nor did we
|
||||||
|
have any plans to. My response was that it would help make me better at
|
||||||
|
my job. A year later we started rolling out a VMware infrastructrue, a
|
||||||
|
project which I lead because I had taken the time to learn stuff. My
|
||||||
|
boss had *trusted* me that I was not wasting my time and it paid off for
|
||||||
|
him because we did not have to get in expensive consultants.
|
||||||
|
|
||||||
|
Trust leads to everything else that we like about
|
||||||
|
work. Allowing your staff to work from home whenever they want is a
|
||||||
|
question of trust. Perhaps one of them is spending time learning how to
|
||||||
|
program in [Go](https://golang.org/) even though you are a Dot Net
|
||||||
|
house. Let them do so, trust them that they are going to make themselves
|
||||||
|
a better programmer.
|
||||||
|
|
||||||
|
This stuff may pay off directly (as in my VMware example), may be it
|
||||||
|
won't. If you let people work from home, maybe at times you will wonder
|
||||||
|
what they are doing. You will however have a happier employee. If that
|
||||||
|
employee has no desire to go anywhere else, but wants to deliver the
|
||||||
|
best they can for your company then you can only win.
|
||||||
15
content/blog/why-we-need-an-open-source-gps/index.md
Normal file
|
|
@ -0,0 +1,15 @@
|
||||||
|
---
|
||||||
|
date: 2015-07-17
|
||||||
|
title: Why we need an open source gps
|
||||||
|
slug: why-we-need-an-open-source-gps
|
||||||
|
category: opinion
|
||||||
|
status: draft
|
||||||
|
summary: Currently all the major exercise GPS units are proprietory. I think
|
||||||
|
we need an open alternative.
|
||||||
|
---
|
||||||
|
|
||||||
|
The GPS market is really dominated by Garmin, for the simple reason that
|
||||||
|
that the make an excellent product. However, I really think we need to
|
||||||
|
have an alternative device that is totally open source. Why? Because not
|
||||||
|
only do these things follow us everywhere, but they broadcast that
|
||||||
|
information everywhere too.
|
||||||
78
content/blog/writeable-tftp-server-on-centos/index.md
Normal file
|
|
@ -0,0 +1,78 @@
|
||||||
|
---
|
||||||
|
date: 2013-03-25
|
||||||
|
title: Writeable TFTP Server On CentOS
|
||||||
|
category: linux
|
||||||
|
---
|
||||||
|
|
||||||
|
Well this caught me out for an embarassingly long time. There are
|
||||||
|
[loads](https://blog.penumbra.be/tag/tftp/)
|
||||||
|
[of](https://www.question-defense.com/2008/11/13/linux-setup-tftp-server-on-centos)
|
||||||
|
[examples](https://wiki.centos.org/EdHeron/PXESetup) of setting up a
|
||||||
|
TFTP server on the web. The vast majority of them assume that you are
|
||||||
|
using them read-only for PXE booting.
|
||||||
|
|
||||||
|
I needed to make it writeable so that it could be used for storing
|
||||||
|
switch/router backups. It is trivially simple once you have read the man
|
||||||
|
page (pro tip: RTFM).
|
||||||
|
|
||||||
|
I am doing this on RHEL6, it should be fine on Centos, Scientific Linux
|
||||||
|
or Fedora as is. Any other distro it will require some modification.
|
||||||
|
First install it (install the client as well to test at the end:
|
||||||
|
|
||||||
|
yum install tftp tftp-server xinetd
|
||||||
|
chkconfig xinetd on
|
||||||
|
|
||||||
|
Now edit the file \`/etc/xinetd.d/tftp to read:
|
||||||
|
|
||||||
|
service tftp
|
||||||
|
{
|
||||||
|
socket_type = dgram
|
||||||
|
protocol = udp
|
||||||
|
wait = yes
|
||||||
|
user = root
|
||||||
|
server = /usr/sbin/in.tftpd
|
||||||
|
server_args = -c -s /var/lib/tftpboot
|
||||||
|
disable = no
|
||||||
|
per_source = 11
|
||||||
|
cps = 100 2
|
||||||
|
flags = IPv4
|
||||||
|
}
|
||||||
|
|
||||||
|
There are 2 changes to this file from the defaults. The `disable` line
|
||||||
|
enables the service. Normally that is where you leave it. However, you
|
||||||
|
cannot upload to the server in this case without pre-creating the files.
|
||||||
|
|
||||||
|
The second change adds a `-c` flag to the `server_args` line. This tells
|
||||||
|
the service to create the files as necessary.
|
||||||
|
|
||||||
|
It still will not work though. You need to tweak the filesystem
|
||||||
|
permissions and SELinux:
|
||||||
|
|
||||||
|
chmod 777 /var/lib/tftpboot
|
||||||
|
setsebool -P tftp_anon_write 1
|
||||||
|
|
||||||
|
Of course you'll also need to open up the firewall. So add the
|
||||||
|
following line to `/etc/sysconfig/iptables`:
|
||||||
|
|
||||||
|
-A INPUT -m state --state NEW -m udp -p udp -m udp --dport 69 -j ACCEPT
|
||||||
|
|
||||||
|
If your IPtables set up is what comes out of the box, there will be a
|
||||||
|
similar line to allow SSH access (tcp:22), I would add this line just
|
||||||
|
after that one. If you have something more complicated, then you will
|
||||||
|
probably know how to add this one as well anyway.
|
||||||
|
|
||||||
|
You should now be able to upload something to the server
|
||||||
|
|
||||||
|
echo "stuff" > test
|
||||||
|
tftp localhost -c put test
|
||||||
|
|
||||||
|
Your test file should now be in `var/lib/tftpboot`.
|
||||||
|
|
||||||
|
One final note with regards to VMware. This does not work if you are
|
||||||
|
using the VMXNET3 adapter, so make sure you are using the E1000. GETs
|
||||||
|
will work and the file will be created, but no data will be put on the
|
||||||
|
server. To annoy you even more, the test PUTting to localhost will work,
|
||||||
|
but PUTs from a remote host will not.
|
||||||
|
|
||||||
|
It has been noted in the VMware forums
|
||||||
|
[here](https://communities.vmware.com/thread/215456)
|
||||||
11
content/contact.md
Normal file
|
|
@ -0,0 +1,11 @@
|
||||||
|
---
|
||||||
|
title: Contact
|
||||||
|
featured_image: ''
|
||||||
|
omit_header_text: true
|
||||||
|
description: We'd love to hear from you
|
||||||
|
type: page
|
||||||
|
menu: main
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
{{< form-contact action="https://formspree.io/f/xleqdkdo" >}}
|
||||||
22
layouts/shortcodes/video.html
Normal file
|
|
@ -0,0 +1,22 @@
|
||||||
|
<div class="container">
|
||||||
|
<div id="player-wrapper" class="{{ .Get 1 }}"></div>
|
||||||
|
</div>
|
||||||
|
|
||||||
|
<script
|
||||||
|
type="text/javascript"
|
||||||
|
src="https://cdn.jsdelivr.net/npm/@clappr/player@latest/dist/clappr.min.js"
|
||||||
|
>
|
||||||
|
</script>
|
||||||
|
|
||||||
|
<script>
|
||||||
|
var playerElement = document.getElementById("player-wrapper");
|
||||||
|
|
||||||
|
var player = new Clappr.Player({
|
||||||
|
source: {{ .Get 0 }},
|
||||||
|
mute: true,
|
||||||
|
height: 360,
|
||||||
|
width: 640
|
||||||
|
});
|
||||||
|
|
||||||
|
player.attachTo(playerElement);
|
||||||
|
</script>
|
||||||
24
pelican2hugo.sh
Executable file
|
|
@ -0,0 +1,24 @@
|
||||||
|
#!/bin/bash
|
||||||
|
|
||||||
|
INDIR="${HOME}/code/chriscowley-me-uk/content"
|
||||||
|
OUTDIR="${HOME}/code/cowley-tech/content/blog"
|
||||||
|
|
||||||
|
for FILE in $(ls ${INDIR}/*.md ); do
|
||||||
|
DATE="$(echo ${FILE} | cut -b 46-55)"
|
||||||
|
SLUG="$(echo ${FILE} | cut -b 57- | sed 's/.md//')"
|
||||||
|
mkdir -pv "${OUTDIR}/$SLUG"
|
||||||
|
OUTFILE="${OUTDIR}/$SLUG/index.md"
|
||||||
|
#echo "---\ndate: $DATE\n" > "${OUTDIR}/$SLUG/index.md"
|
||||||
|
echo "---" | tee "${OUTFILE}"
|
||||||
|
printf "date: %s\n" ${DATE} | tee -a "${OUTFILE}"
|
||||||
|
sed -e 's/Title: /title: /g' ${FILE} \
|
||||||
|
-e 's/Thumbnail: /featured_image: /g' \
|
||||||
|
-e 's/Category: /category: /g' \
|
||||||
|
-e '/Slug: /d' \
|
||||||
|
-e '/Email: /d' \
|
||||||
|
-e '/Tags: /d' \
|
||||||
|
-e '/tags: /d' \
|
||||||
|
-e '0,/^$/ s/^$/---\n/' \
|
||||||
|
| tee -a "${OUTFILE}"
|
||||||
|
done
|
||||||
|
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
{"Target":"ananke/css/main.min.css","MediaType":"text/css","Data":{}}
|
||||||
|
|
@ -0,0 +1 @@
|
||||||
|
{"Target":"css/coder.css","MediaType":"text/css","Data":{}}
|
||||||
BIN
static/images/0k24Ambl.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 35 KiB |
BIN
static/images/20140911103132_272.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 64 KiB |
BIN
static/images/2DBKEPM2OT.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 590 KiB |
BIN
static/images/3140gr.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 80 KiB |
BIN
static/images/3SJXbMb.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 60 KiB |
BIN
static/images/5360082447 - Mens Windslam LS Jersey - frnt.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 383 KiB |
BIN
static/images/82H3FWFl.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 23 KiB |
BIN
static/images/Bike-park-thumbnail.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 446 KiB |
BIN
static/images/Bike-park-thumbnail.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 36 KiB |
BIN
static/images/BrownSwitch-3D.gif
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.7 MiB |
BIN
static/images/FNGMpcr.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 48 KiB |
BIN
static/images/GYvvKrx.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 40 KiB |
BIN
static/images/IMG_20180327_185937.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 946 KiB |
BIN
static/images/IMG_20190227_104927822.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 1.8 MiB |
BIN
static/images/PowerEdge-VRTX-Front-View-with-2.5-Drives.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 296 KiB |
BIN
static/images/Product-gps-minigpsY12-zoom11.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 171 KiB |
BIN
static/images/Product-gps-minigpsY12-zoom2.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 153 KiB |
BIN
static/images/Product-gps-minigpsY12-zoom2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 169 KiB |
BIN
static/images/SYS-2027PR-HTR_25.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 16 KiB |
BIN
static/images/Tux.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 880 KiB |
BIN
static/images/VID_20190227_162245419.gif
Normal file
{kind=link}
|
After Width: | Height: | Size: 6.8 MiB |
BIN
static/images/VID_20190227_162311194.gif
Normal file
{kind=link}
|
After Width: | Height: | Size: 7.4 MiB |
BIN
static/images/VID_20190227_162410026.gif
Normal file
{kind=link}
|
After Width: | Height: | Size: 5.3 MiB |
BIN
static/images/Z8LFhPUl.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 193 KiB |