initial commit
This commit is contained in:
commit
ca6a4d45d1
113 changed files with 10501 additions and 0 deletions
200
content/blog/open-source-hyper-converged-infrastructure/index.md
Normal file
200
content/blog/open-source-hyper-converged-infrastructure/index.md
Normal file
|
|
@ -0,0 +1,200 @@
|
|||
---
|
||||
date: 2014-09-19
|
||||
title: Open Source Hyper-converged Infrastructure
|
||||
category: devops
|
||||
---
|
||||
|
||||
Hyper-converged seems to be all the rage at the moment. VMware\'s
|
||||
announcement of the [EVO:RAIL](https://www.vmware.com/products/evorail/)
|
||||
has naturally got lots of tongues wagging. They are jumping into a
|
||||
market already well populated.
|
||||
|
||||
I was looking at the pricing/features and though it all looks a little
|
||||
expensive. Nutanix for example, will sell you the following:
|
||||
|
||||
- NX-1000: \$80k+ (4 little nodes)
|
||||
- NX-3000: \$144k+ (4 big nodes)
|
||||
- NX-6000: \$120k+ (2 massive nodes)
|
||||
|
||||
I'd imagine that, once you include licensing, EVO:RAIL systems will
|
||||
come in similar. What do you get for your case:
|
||||
|
||||
- A COTS server (dual E5-26x0 Xeon, 64GB+ RAM)
|
||||
- Networking (at least 2x 1Gb, but most are 10Gb)
|
||||
- A few TB Storage
|
||||
- Tend to rely on the customer to supply the network infrastructure,
|
||||
but I see no real problem with that. If I had all HP Procurves in my
|
||||
DC, I would pretty annoyed if I suddenly had a pair of Cisco\'s to
|
||||
worry about
|
||||
- The while system is built on top of architectually identical
|
||||
building blocks
|
||||
|
||||
That last one does not necessarily mean that all the boxes are the same.
|
||||
It means there is no concept of a \"storage node\" or a \"compute
|
||||
node\". You just have \"nodes\" that all contain compute, storage,
|
||||
networking, whatever. You may have some that are bigger than others, but
|
||||
they all do the same job.
|
||||
|
||||
On top of that, you get some software special sauce to tie it all
|
||||
together. For EVO::RAIL, that looks something like this:
|
||||
|
||||

|
||||
|
||||
and this:
|
||||
|
||||

|
||||
|
||||
[Which is nice](https://youtu.be/XOhZgAPn_CU)
|
||||
|
||||
I decided to play a little game, a bit like when you want to buy a new
|
||||
computer: you go online, put together all the parts you want in a
|
||||
basket, look at, dream a little. After a few rounds of this you start
|
||||
justifying it to yourself, then you wife/accountant. Eventually, you
|
||||
build one final basket pull out the credit card an pull the trigger.
|
||||
Well, this is like that, but more expensive.
|
||||
|
||||
I think that we now have everything we need in the FLOSS world to
|
||||
impliment a Hyper-converged architecture. I suppose this is my attempt
|
||||
to document that as a some sort of reference architecture. A key
|
||||
component will be Openstack, but not necessarily everywhere.
|
||||
|
||||
# Hardware
|
||||
|
||||
<img class='image-process-article-image' src='images/SYS-2027PR-HTR_25.jpg' />
|
||||
|
||||
The easy bit is the CPU and RAM: plenty (at least 6 cores with 64GB of
|
||||
RAM). Networking, surprisingly is also relatively simple. Anything will
|
||||
do (2x 1Gb will be fine an entry level node), but 2x 10Gb is preferable,
|
||||
Infiniband would also be great (Linux works beautifully with
|
||||
Infiniband). All this would (ideally) be put into a box that has
|
||||
[multiple nodes in one
|
||||
box](https://www.supermicro.com.tw/products/system/2U/2028/SYS-2028TP-HTR.cfm).
|
||||
|
||||
Storage is more complex. Tiering is essential, and I personally am not a
|
||||
fan of hardware RAID. Additionally, this needs to be replicated. The
|
||||
overall architecture would look something like:
|
||||
|
||||
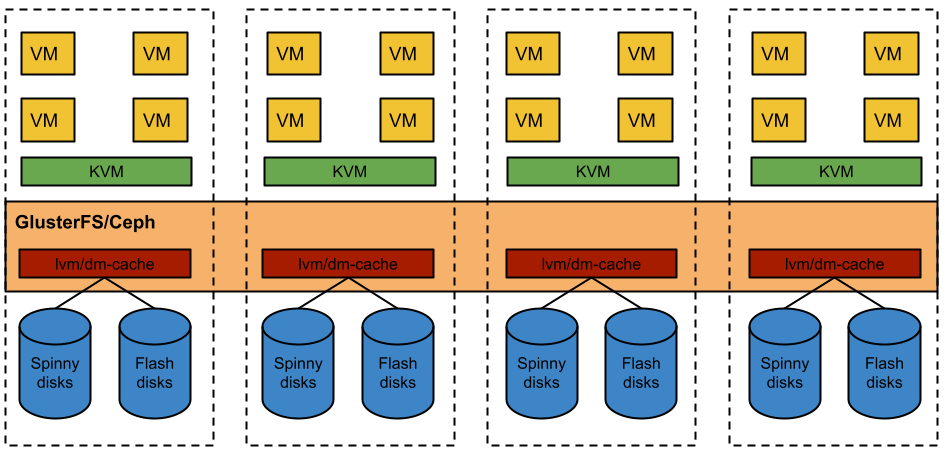
|
||||
|
||||
Each node would have to at least an SSD, plus a decent number of spinny
|
||||
disks to get a sensible capacity. The spinners have no need for RAID
|
||||
-data protection is done on a cluster level higher up the stack. I think
|
||||
right now, I would probably run with Gluster, for reasons which I will
|
||||
revisit later. Ceph is probably where is till be at in the future
|
||||
though.
|
||||
|
||||
A good rule of thumb when using tiering is that your SSD should be
|
||||
roughly 10% of your spinning rust. So lets say a single 400-500GB SSD,
|
||||
along side 5TB of spinning disk.
|
||||
|
||||
For the clustering, you would need at least 2x 1Gb NICs dedicated to
|
||||
this. If one could dedicate a pair of 10Gb NICs then that would be
|
||||
awesome.
|
||||
|
||||
Finally, the OS needs to be installed on something, but a USB key or SD
|
||||
card is more than sufficient for that.
|
||||
|
||||
The complex bit is the initial configuration. What really makes the
|
||||
likes of Nutanix and EVO:RAIL stand out is the simplicity of install.
|
||||
The images above our the 4 steps it takes to get an EVO:RAIL cluster
|
||||
running and I have to admit it pretty darn good.
|
||||
|
||||
# Software
|
||||
|
||||
What we need to aim at is that you:
|
||||
|
||||
1. download an image
|
||||
2. burn on to USB keys/SD cards
|
||||
3. boot all the nodes
|
||||
4. it works!
|
||||
|
||||
I think all the parts to auto-configure a cluster exist in the FOSS
|
||||
world. The problem is making it 100% plug and play. I would say that
|
||||
this is finally a genuine use for IPv6 and mDNS. Let\'s dedicate a pair
|
||||
of 1Gb/s NICs to cluster communications and do all that over IPv6.
|
||||
|
||||
This enables to get a fully working network going with no intervention
|
||||
from the user. Now we can have a Config Management system running over
|
||||
said network. If we use Puppet, then our secret sauce can be used as an
|
||||
ENC to configure all the nodes.
|
||||
|
||||
What this means is that amount of new code that needs to be written is
|
||||
relatively small. All we need is that initial configuration utility. To
|
||||
make it super simple, this could even be in \"the cloud\" and each
|
||||
cluster registers itself with a UUID. I suppose this would work in much
|
||||
the same way as `etcd`. I suppose this interface could also be where the
|
||||
user downloads their image files, thus the UUID could be part of said
|
||||
image. Make all that FLOSS, and people can host their own management
|
||||
portal if they prefer. It would function in much the same way as
|
||||
RHN/Satellite.
|
||||
|
||||
Anyway, once that is all done, Puppet can then go and do all the
|
||||
necessary configuration. There is quite a bit of integration that needs
|
||||
to happen here.
|
||||
|
||||
There are 2 obvious choices for the virtualisation layer:
|
||||
|
||||
- oVirt
|
||||
- Openstack
|
||||
|
||||
These are necessarily mutually exclusive. The oVirt team are build in
|
||||
support for various Openstack technologies:
|
||||
|
||||
- Neutron for networking
|
||||
- Cinder for block storage
|
||||
- Glance for template storage
|
||||
|
||||
Different hosts could be tagged as either oVirt or Nova nodes depending
|
||||
on the type of app they are running. They all then share the same pool
|
||||
of storage.
|
||||
|
||||
The configuration would then be dealt with using Puppet roles.
|
||||
|
||||
When you need to add a new appliance, you just download an image with
|
||||
the correct UUID and it will add itself to the cluster.
|
||||
|
||||
# The bottom line
|
||||
|
||||
Of course, the important bit is the price. This is very much back of
|
||||
envelope, but something like a Supermicro quad-node, where each node
|
||||
consists of:
|
||||
|
||||
- 1x Xeon E5-2620V2 (6C, HT 2.1GHz)
|
||||
- 64GB RAM
|
||||
- 1x 240GB SSD
|
||||
- 2x 1TB 10k SATA
|
||||
- 4x 1Gb NIC
|
||||
|
||||
comes to \~£8500. This compares pretty well with a Nutanix NX-1000, for
|
||||
10% of the price.
|
||||
|
||||
Something comparable to a the NX-3000 would again be 4 nodes, each
|
||||
consisting of:
|
||||
|
||||
- 2x Xeon E5-2620V2 (6C, HT 2.1GHz)
|
||||
- 128GB RAM
|
||||
- 1x 480GB SSD
|
||||
- 4x 1TB 10k SATA
|
||||
- 4x 1Gb NIC
|
||||
- 4x 10Gb NIC
|
||||
|
||||
would come to \~£15000. Again, this is 10% of the the price of the
|
||||
commercial solution.
|
||||
|
||||
These are 90% markups! **90%!!!** Even when you add in the vSphere
|
||||
licensing, that is still 70%. I have not seen any prices for any of the
|
||||
EVO::RAIL vendors, but I do not see that it will be much different. Why
|
||||
should it be?
|
||||
|
||||
Yes they are supported, but that is a lot to pay. I do not mean to pick
|
||||
on Nutanix, they make a fantastic product - one that I have proposed to
|
||||
customers on multiple occasions. The only reason I have used them is
|
||||
because it is relatively easy to find pricing.
|
||||
|
||||
Is this a statement of intent? I do not know. For now I do not have the
|
||||
time to run with this, but that does not mean I will not find the time.
|
||||
It does give a good reference architecture that will work for 95% of use
|
||||
cases with the above mentioned virtualisation/cloud platforms.
|
||||
Loading…
Add table
Add a link
Reference in a new issue