101 lines
4 KiB
Markdown
101 lines
4 KiB
Markdown
|
|
---
|
||
|
|
date: 2016-07-10
|
||
|
|
title: Playing with Docker Swarm Mode
|
||
|
|
category: devops
|
||
|
|
---
|
||
|
|
|
||
|
|
|
||
|
|
The big announcement of the recent DockerCon was 1.12 integrating Swarm. As far the as the ecosystem goes that is quite a game changer, but I will not be dwelling on that. I am just going to regurgitate what others have said and add a few bit of my own.
|
||
|
|
|
||
|
|
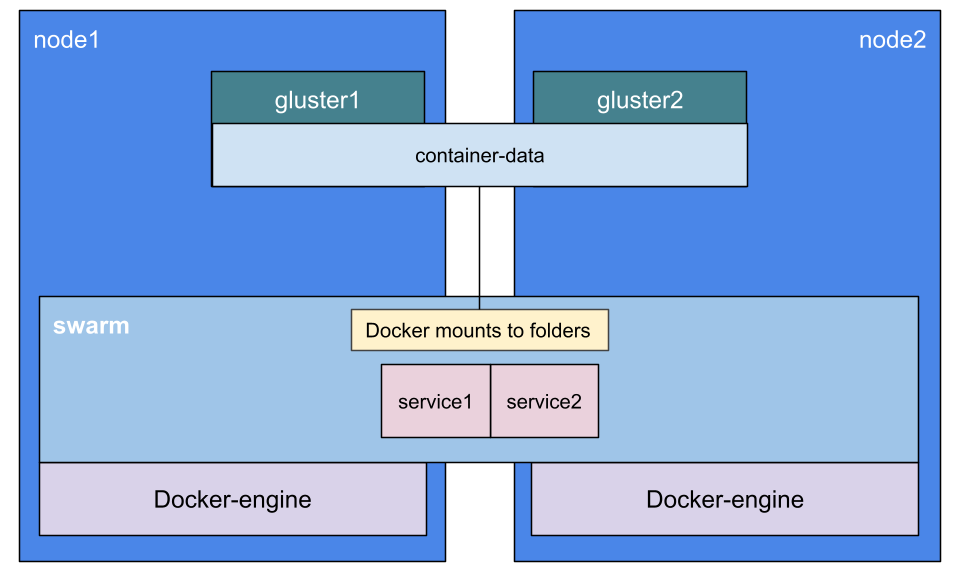
I am going to build a simple cluster that looks like this:
|
||
|
|
|
||
|
|
|
||
|
|
|
||
|
|
What we have here is 2 nodes running Centos 7 which run Docker 1.12-rcX in swarm mode. I am actually only going to create a single manager and a worker. For a bonus, I am going to touch on a subject that has been ignored a little: storage.
|
||
|
|
|
||
|
|
Many will say that your application should use S3, or whatever. The fact is that POSIX storage is really useful though. So, we need a way of having storage at the same place on each node that can be used as a volume in our application containers. In keeping with the principles of Swarm, this storage needs to be distributed, replicated and scalable. In the Open Source world we have 2 major players (and plenty of others) in [Ceph](https://ceph.com) and [Gluster](https://www.gluster.org/). They are both awesome, scalable, stable, blahblahblah. Either would be a great choice, but I am going to use Gluster because, err, reasons. Basically I flipped a coin.
|
||
|
|
|
||
|
|
I will make each of the 2 nodes a Gluster server with a replicated volume. I will then mount the volume on each node.
|
||
|
|
|
||
|
|
I am assuming that you have a pair of clean, and up-to-date, CentOS 7 nodes. I also assume that they have a single NIC (not best-practise, but we are playing here) and can resolve each other by name (either by DNS or `/etc/hosts`).
|
||
|
|
|
||
|
|
## Gluster
|
||
|
|
|
||
|
|
See the main docs for more info, but the *very* basic process is (on each node):
|
||
|
|
|
||
|
|
```
|
||
|
|
sudo yum install centos-release-gluster epel-release
|
||
|
|
sudo yum install glusterfs-server
|
||
|
|
sudo systemctl enable glusterd
|
||
|
|
sudo systemctl start glusterd
|
||
|
|
```
|
||
|
|
|
||
|
|
Now create the cluster. From node1 run:
|
||
|
|
|
||
|
|
```
|
||
|
|
sudo gluster peer probe node2
|
||
|
|
```
|
||
|
|
|
||
|
|
Next, from node2 run
|
||
|
|
|
||
|
|
```
|
||
|
|
sudo gluster peer probe node1
|
||
|
|
```
|
||
|
|
|
||
|
|
Now, we have our storage cluster setup we need to create a volume. On each node create a folder to store the data:
|
||
|
|
|
||
|
|
```
|
||
|
|
mkdir -pv /data/brick1/gv0
|
||
|
|
```
|
||
|
|
|
||
|
|
As an aside, I mount a seperate disk at `/data/brick1` formatted with XFS. This is not essential for our purposes though.
|
||
|
|
|
||
|
|
Now, from `node1` (because it will be our master, so my OCD dictates it is also our admin node) create the volume:
|
||
|
|
|
||
|
|
```
|
||
|
|
sudo gluster volume create gv0 replica 2 node1:/data/brick1/gv0 node2:/data/brick1/gv0
|
||
|
|
sudo gluster volume start gv0
|
||
|
|
```
|
||
|
|
|
||
|
|
Now on each node mount the volume:
|
||
|
|
|
||
|
|
```
|
||
|
|
echo "$(hostname -s):/gv0 /mnt glusterfs defaults,_netdev 0 0" | sudo tee -a /etc/fstab
|
||
|
|
sudo mount /mnt
|
||
|
|
```
|
||
|
|
|
||
|
|
## Docker
|
||
|
|
|
||
|
|
We'll install Docker using `docker-machine`. I do it from an admin machine, but you could use one of your cluster nodes. You need to have [passwordless root SSH access](http://bfy.tw/2AYK) to your nodes.
|
||
|
|
|
||
|
|
Install `docker-engine` and `docker-machine` as root on the admin node:
|
||
|
|
|
||
|
|
```
|
||
|
|
curl -fsSL https://experimental.docker.com/ | sudo sh
|
||
|
|
curl -L https://github.com/docker/machine/releases/download/v0.8.0-rc2/docker-machine-`uname -s`-`uname -m` > docker-machine && \
|
||
|
|
chmod +x docker-machine
|
||
|
|
sudo mv -v docker-machine /usr/local/bin/
|
||
|
|
```
|
||
|
|
|
||
|
|
Now you can go ahead and install docker-engine on the cluster nodes:
|
||
|
|
|
||
|
|
```
|
||
|
|
docker-machine create --engine-install-url experimental.docker.com \
|
||
|
|
-d generic --generic-ip-address=node-1 \
|
||
|
|
--generic-ssh-key /root/.ssh/id_rsa node-1
|
||
|
|
docker-machine create --engine-install-url experimental.docker.com \
|
||
|
|
-d generic --generic-ip-address=node-2 \
|
||
|
|
--generic-ssh-key /root/.ssh/id_rsa node-2
|
||
|
|
```
|
||
|
|
|
||
|
|
Now you can enable Swarm mode:
|
||
|
|
|
||
|
|
```
|
||
|
|
eval $(docker-machine env node1)
|
||
|
|
docker swarm init
|
||
|
|
eval $(docker-machine env node2)
|
||
|
|
docker swarm join node1:2377
|
||
|
|
```
|
||
|
|
|
||
|
|
That is it - you now have a swarm cluster. I have another post coming where I will describe a method I use for collecting metrics about the cluster. That will also include deploying an application on the cluster too.
|